

码字不易,别忘点赞!
最近Meta大佬团队(FixRes,DeiT,ResMLP等作者团队)在论文Three things everyone should know about Vision Transformers提出了关于ViT的三点改进建议,它们分别涉及到如何加速ViT,如何对ViT进行finetune,以及如何改进ViT的patch预处理层来提升基于MIM(图像掩码)的无监督训练。这篇文章将介绍这三点改进建议以及其中的实验结论。
ViT的baseline
论文研究的是谷歌ViT论文提出的两个原生ViT模型:ViT-B/16和ViT-L/16,同时加上DeiT论文中提出的两个更小的模型:ViT-Ti/16和ViT-S/16,这4个模型的patch_size均为16x16,主要的区别在于模型的参数设置,即采用不同的depth,width和heads:
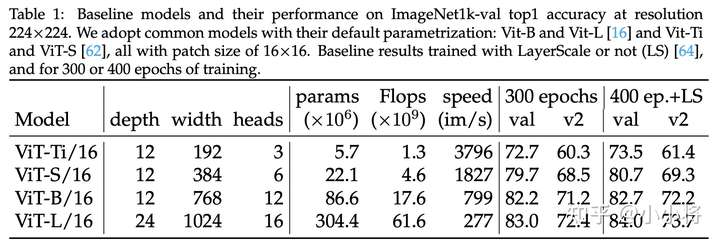
不过,这里baseline的训练策略采用的是ResNet strikes back: An improved training procedure in timm提出的A2策略,而不是采用DeiT的训练策略,相比DeiT训练策略,A2策略也是训练300 epochs,但是采用LAMB优化器,而且采用的是BCE loss而不是常规的CE loss。
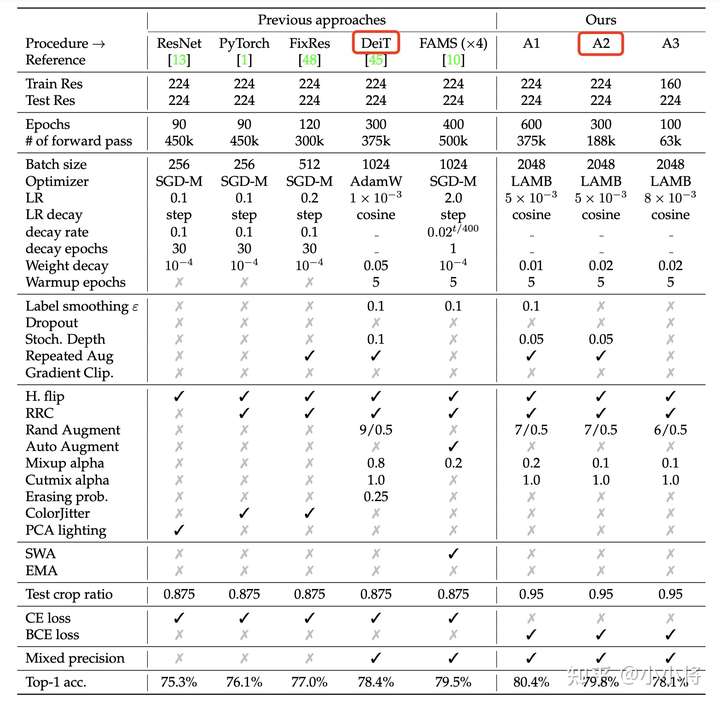
不过A2策略是为ResNet的训练而设计,对于ViT,这里调整了学习速率和随机深度(Stochastic Depth)的drop rate:
- ViT-Ti和ViT-S的学习速率采用4e-3,而ViT-B和ViT-L的学习速率采用3e-3;
- ViT-Ti不采用随机深度即drop rate为0,ViT-S,ViT-B和ViT-L的drop rate分别为0.05,0.1和0.4;
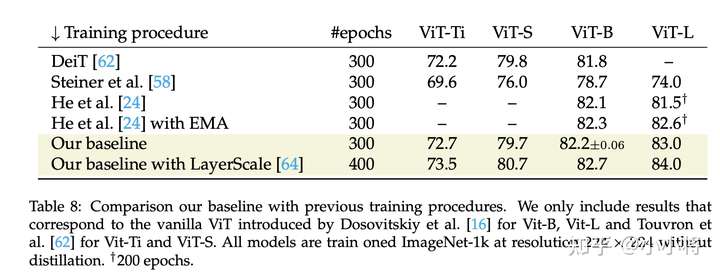
上述训练策略相比DeiT的策略,训练得到的模型在ImageNet1K验证集上的top1 acc有微弱的提升,比如ViT-B从81.8提升至82.2。此外,论文还训练了一个加上LayerScale(见论文CaiT)的400 epoch增强版本,其模型效果有进一步提升,比如ViT-B从82.2提升至82.7。论文还对比了MAE中训练的ViT(训练策略和DeiT基本一致,但超参数不同,而且采用EMA),其中300 epoch版本和MAE效果相当:
class LayerScale(nn.Module):
def __init__(self, dim, init_values=1e-5, inplace=False):
super().__init__()
self.inplace = inplace
self.gamma = nn.Parameter(init_values * torch.ones(dim))
def forward(self, x):
return x.mul_(self.gamma) if self.inplace else x * self.gamma
class Block(nn.Module):
def __init__(
self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., init_values=None,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.ls1 = LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.ls2 = LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
x = x + self.drop_path1(self.ls1(self.attn(self.norm1(x))))
x = x + self.drop_path2(self.ls2(self.mlp(self.norm2(x))))
return x并行ViT
网络的深度(depth)和宽度(width)是模型设计中很重要的两个参数,很多模型往往是通过增加depth来增大模型比如ResNet50 -> ResNet101,也有一些研究如Wide ResNet和Wide Residual Networks通过增加width来扩展模型,此外EfficientNet提出同步增加depth和width(以及input resolution)来扩展模型。毫不疑问,增加depth和width都能提升模型的容量从而提升性能,但两种方式有各自的优缺点。
首先,在优化方面,网络的越深,优化难度越大,当然通过残差连接可以减轻深度网络的训练难题,但是这依然是无法避免的,最近也有一些工作如CaiT和DeepNet来专门解决深层transformer的训练问题。另外一点是模型的可分离性(Separability),分类模型的线性分类器前的特征维度大小影响可分离性,那么网络越宽,特征维度越大,可分离性越好(一些网络如MobileNet额外增加一个卷积层来提升特征维度);但是特征维度过大也可能会带来过拟合,所以这其中需要一定的折中。对于ViT模型,其特征维度往往较小,比如ResNet50的特征维度为2048,而同等量级的ViT-S模型的特征大小是384。最后,depth和width对模型的复杂度有不同的影响,对于ViT模型:
- 参数量:和depth成正比,而和width的平方成正比;
- 计算量(FLOPS):和depth成正比,而和width的平方成正比;
- 推理的峰值显存:增加depth不会影响显存,但和width的平方成正比;
- 推理速度:理论上更宽的网络的并行度更好,其推理速度更快,但这也和具体的框架实现和硬件平台相关。
基于上述的讨论,论文提出了并行ViT:将几个连续的transformer blocks并行化处理,这就相当于减少模型的深度而增加模型的宽度,如下图所示:
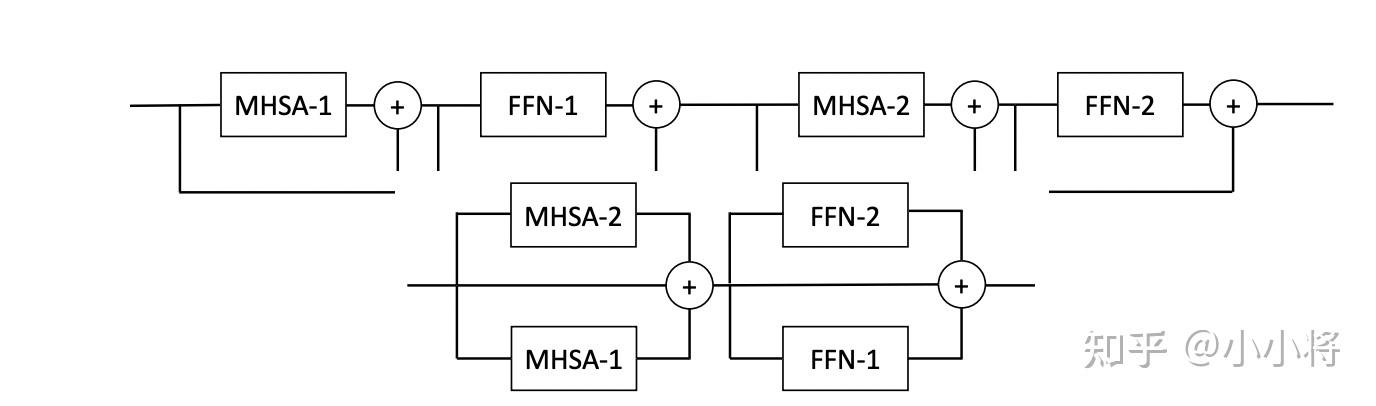
原来的ViT是串行处理transformer blocks,对于两个连续的blocks,其计算如下:
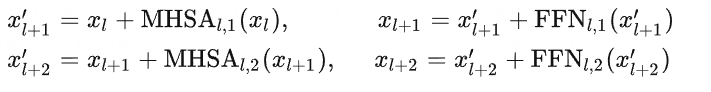
这里我们调整MHSA-2和FFN-1的位置,并将两个MHSA和两个FFN分别进行并行化处理:
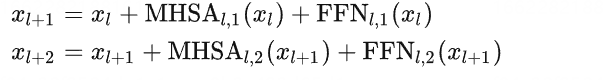
这里之所以可以这样处理,是因为当网络变深时,残差部分变得比较小,此时有 ,那么并行化后和原来的处理近似等效。而且,并行化处理后,并不会改变模型的参数量和FLOPs。
class ParallelBlock(nn.Module):
def __init__(
self, dim, num_heads, num_parallel=2, mlp_ratio=4., qkv_bias=False, init_values=None,
drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.num_parallel = num_parallel
self.attns = nn.ModuleList()
self.ffns = nn.ModuleList()
for _ in range(num_parallel):
self.attns.append(nn.Sequential(OrderedDict([
('norm', norm_layer(dim)),
('attn', Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)),
('ls', LayerScale(dim, init_values=init_values) if init_values else nn.Identity()),
('drop_path', DropPath(drop_path) if drop_path > 0. else nn.Identity())
])))
self.ffns.append(nn.Sequential(OrderedDict([
('norm', norm_layer(dim)),
('mlp', Mlp(dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)),
('ls', LayerScale(dim, init_values=init_values) if init_values else nn.Identity()),
('drop_path', DropPath(drop_path) if drop_path > 0. else nn.Identity())
])))
def _forward_jit(self, x):
x = x + torch.stack([attn(x) for attn in self.attns]).sum(dim=0)
x = x + torch.stack([ffn(x) for ffn in self.ffns]).sum(dim=0)
return x
@torch.jit.ignore
def _forward(self, x):
x = x + sum(attn(x) for attn in self.attns)
x = x + sum(ffn(x) for ffn in self.ffns)
return x
def forward(self, x):
if torch.jit.is_scripting() or torch.jit.is_tracing():
return self._forward_jit(x)
else:
return self._forward(x)论文通过实验研究了并行ViT和串行ViT(原生ViT)在性能和速度上的区别。这里首先介绍一下实验所采用的模型命名规则:使用Ti/S/B/L来指代模型的width,Ti/S/B/L分别对应192/384/768/1024;然后后面加上模型的depth。比如ViT-B24模型,其width为768,而depth为24;对于并行ViT,还要说明模型的并行分支数量,比如ViT-B12x2,其width为768,而depth为12,但是每个block包含两个并行分支,所以它和串行模型ViT-B24相当。
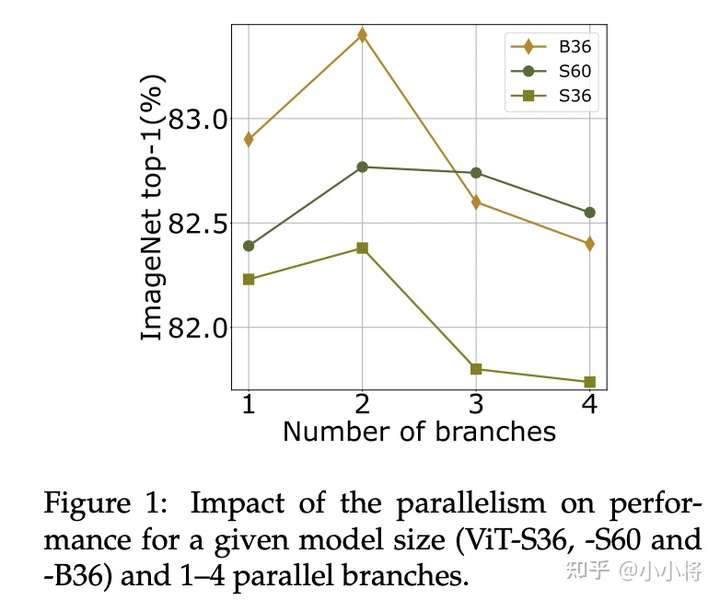
论文首先研究了并行分支量对模型的性能影响,这里选择了3个模型(S36,S60和B36),分别实验了并行分支为1(ViT-B36),2(ViT-B18x2),3(ViT-B12x3)和4(ViT-B9x4)时的性能,如下所示,可以看到并行度为2时模型效果是最好的,而且效果也超过串行模型(大概是深度减半后更容易训练了),因而后面的实验都默认采用2个并行分支。
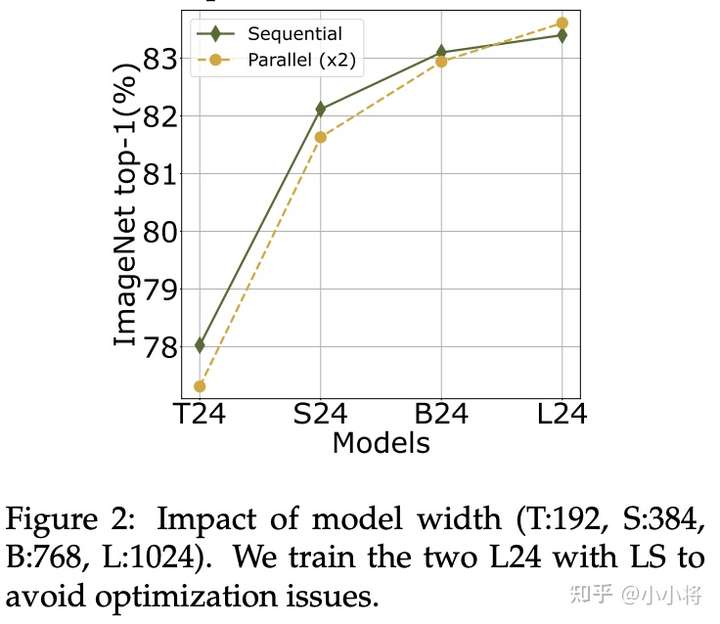
然后是并行模型在不同width下的表现,如下图所示,对于小模型T24和S24,其串行模型效果要优于并行版本,这应该是在depth为24时,本身串行模型就很容易优化;而B24和B12x2性能相当,对于最大的模型L24,并行版本效果要优于串行版本(这里采用LayerScale来避免优化问题)。
对于不同的depth,并行模型和串行模型的对比如下,可以看到无论是B还是S模型,网络越来越深时,并行版本就超过串行版本,这说明并行处理能在一定程度上减轻深度模型的优化问题。
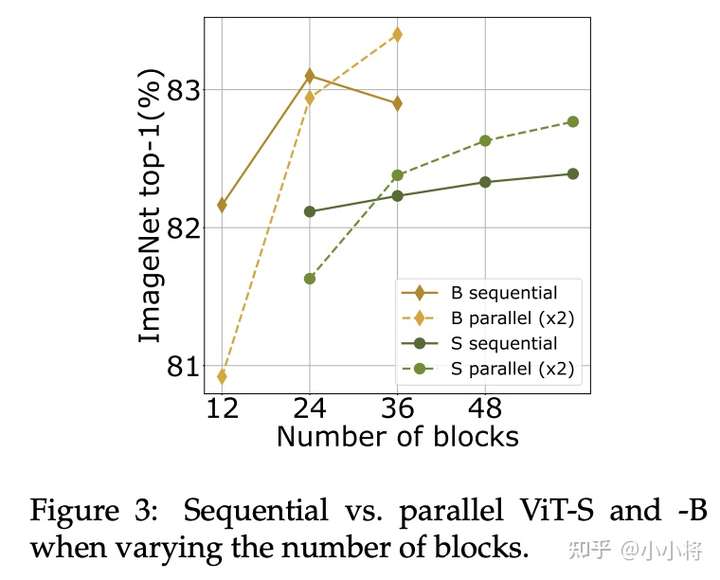
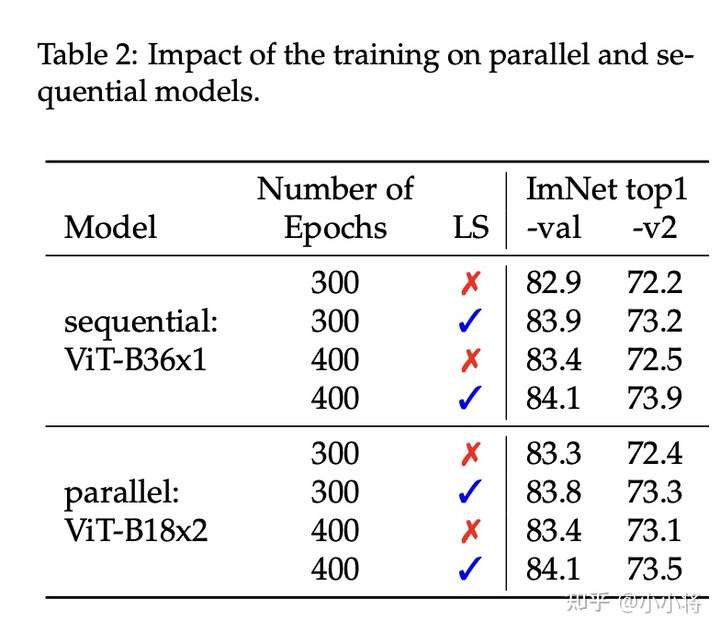
对于大模型,LayerScale可以一定程度上减轻优化问题,论文以B36模型实验了LayerScale对并行模型的影响,如下所示,可以看到LayerScale均可以提升串行模型和并行模型的效果,最终两个模型效果相当。
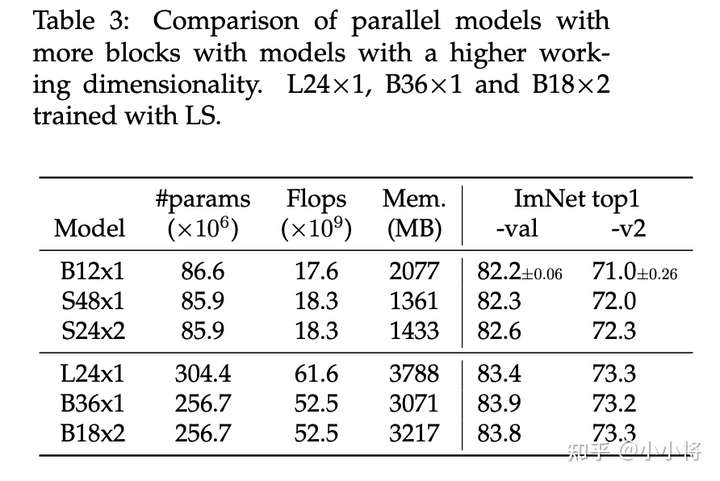
另外一个对比是与直接增加width模型的对比,如下表所示,比如B12x1模型它的width是768,而S48x1的width是384,B12x1和S48x1在参数量和FLOPS上是相当的,只不过B12x1属于宽网络,这里S24x2是并行版本。可以看到无论是串行版本还是并行版本,其效果均优于宽网络,而且宽网络需要更大的显存。其中S24x2效果也好于S48x1(网络较深):
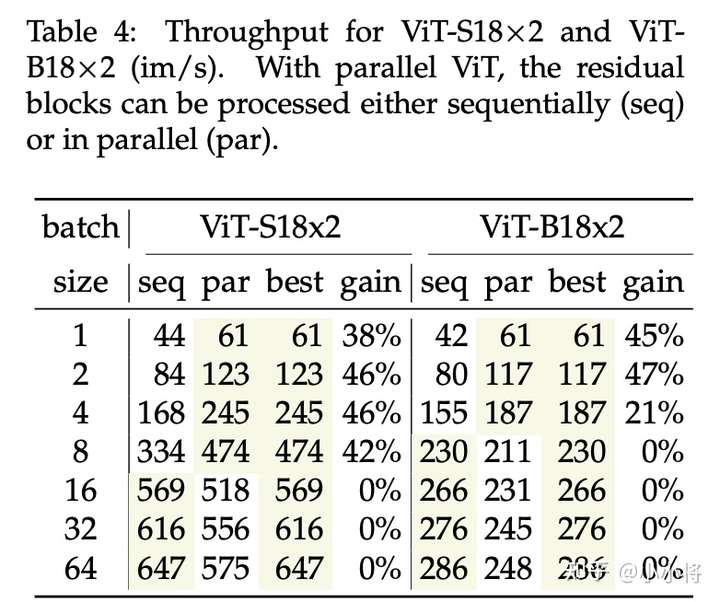
最后是推理速度的对比,可以看到在单样本和小batch size推理场景下,并行ViT可以带来较大的推理速度提升,但在较大的batch size下(超过16),速度就差于串行版本,这种差异是缺少特定的CUDA kernel实现导致的。
综上,得到如下结论:通过对连续的2个transformer block进行并行化,在不改变参数量和FLOPS下,能得到和原生ViT类似的性能,而且对于较大较深的模型,并行版本由于缓解了优化问题还能带来性能的提升,此外并行ViT在较小的batch size场景下推理速度有明显的优势。
你只需要finetune attention
第二个改进点是有关finetune,模型finetune主要有两个应用场景,一是将模型迁移到更大的分辨率图像上,FixRes论文指出由于RandomResizedCrop数据增强的使用会导致训练和测试时图像分辨率不一致,当模型训练完后,在稍大的分辨率下对模型finetune可以得到更好的性能,如224训练然后384微调;对于ViT,由于position embedding和图像分辨率绑定,所以增加分辨率后也需要进行finetune。第二个场景是迁移学习,我们往往会采用ImageNet上预训练好的模型在下游任务上finetune。这里提出的改进是:与其finetune整个ViT,不如只finetune其中的attention层。只finetune attention层只需要训练全部参数的约30%,而且节省10%的显存,训练速度也可以提升10%:
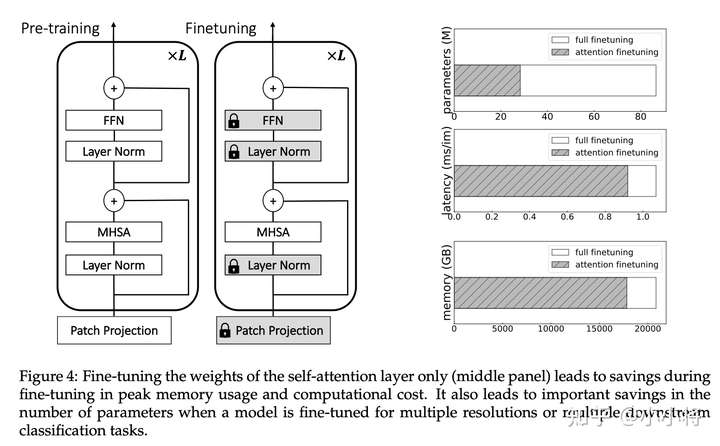
如下所示,采用224训练(这里为了保证足够收敛,采用400epoch训练策略),然后384下进行finetune,只finetune attention层和finetune全部层的效果是相当的,相比之下,只finetune FFN层效果就差一些。
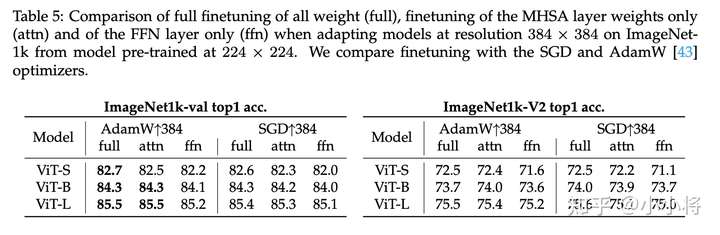
在迁移学习方面,即先在ImageNet上预训练,然后在其它分类数据集上finetune,这里测试了6个数据集,结果如下表所示,其中在较小的数据集上(CARS和Flowers,训练数据较少,类别少),只finetune attention层效果比finetune全部层要好一点。但是在其它较大一点的数据集上(INAT-18,INAT-19和CIFAR-100),只finetune attention层和finetune全部层存在较大的性能gap,而且也差于只finetune FFN层。这主要是因为这些数据集存在较多的ImageNet1K没有的新类别,需要更多的参数来学习,而attention层的参数只占整个模型的1/3;对于较大的模型如ViT-L,其性能gap就较小一点,因为此时attention层参数也达到了finetune所需。
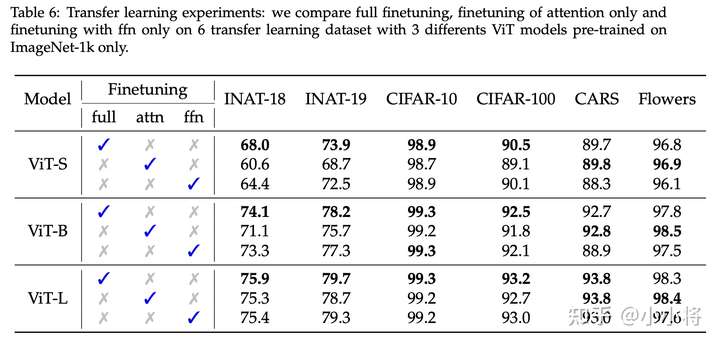
综上,可以得到如下结论:如果在同样的数据集上将模型迁移到更大的分辨率上,可以只finetune attention层;如果要迁移到其它数据集上,如果数据集比较小或者模型足够大,也可以只finetune attention层。
基于hMLP的patch预处理
第三个改进点是patch预处理。原生的ViT的patch embedding层是直接采用一个linear层将16x16的patch转换为一个patch embedding,实现上等价于一个stride=16且kernel_size=16的卷积层。这里提出的改进是采用一个层级的MLP stem,简称hMLP,如下所示,首先对4x4大小的patch进行转换,然后经过两次合并2x2区域,得到1/16大小的特征图。虽然经过了3次操作,但是16x16大小的patch还是独立处理的,所以这和原生ViT的处理是完全等价的。而且对于基于图像掩码的无监督训练方法如BeiT,hMLP这种patch预处理也是完全兼容的,你可以在patch预处理前或者之后进行图像掩码。
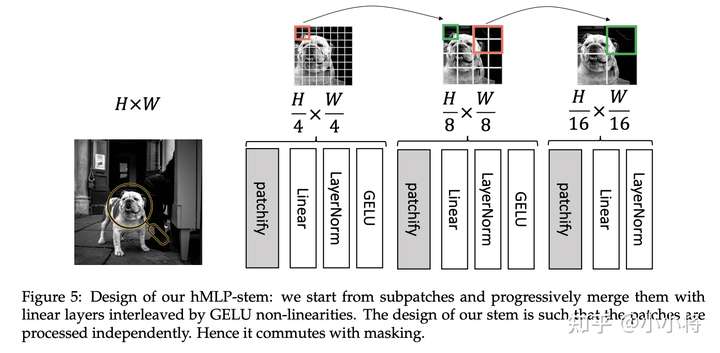
与原来的ViT采用一个卷积层(16x16 conv)进行token化类似,其实hMLP也可以用几个卷积层(4x4 conv -> 2x2 conv -> 2x2 conv)来等价实现:
import torch
import torch.nn as nn
class hMLP_stem(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=(224,224), patch_size=(16,16), in_chans=3, embed_dim=768):
super().__init__()
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = torch.nn.Sequential(
*[nn.Conv2d(in_chans, embed_dim//4, kernel_size=4, stride=4),
nn.SyncBatchNorm(embed_dim//4), # 这里采用BN,也可以采用LN
nn.GELU(),
nn.Conv2d(embed_dim//4, embed_dim//4, kernel_size=2, stride=2),
nn.SyncBatchNorm(embed_dim//4),
nn.GELU(),
nn.Conv2d(embed_dim//4, embed_dim, kernel_size=2, stride=2),
nn.SyncBatchNorm(embed_dim),
])
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x)
return x所以,hMLP也是一种conv stem,其实在此之前,论文LeViT已经提出采用几个连续的卷积层来替代原生的patch embedding层,不过那里采用是4个连续的stride=2的3x3卷积层,不同的patchs之间就存在信息交互了,也就和原来的ViT不是完全等价了。另外要说的一点是,hMLP相比原来的ViT,其计算量FLOPS不没有明显增加,比如ViT-B模型从原来的17.58G只增加到17.73G。
基于hMLP的ViT在ImageNet数据集上的效果如下表所示,这里的对比实验包括了有监督训练,也包括了基于BeiT的无监督预训练+finetune。可以看到,无论是有监督还是无监督实验,基于hMLP的ViT效果均优于原来的ViT:
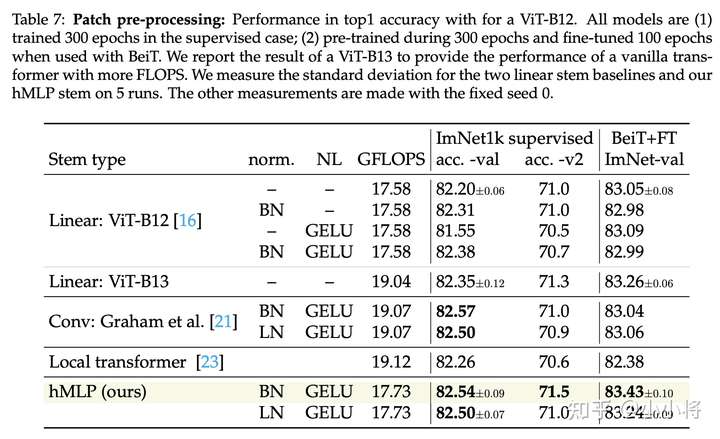
总结来看:基于hMLP的ViT在几乎不增加计算量的情况下,可以提升ViT在有监督和无监督下的训练性能。
小结
虽然在ViT之后,出现了很多vision transformer的改进工作,如金字塔ViT和Local ViT,但它们都变得越来越复杂了,相比之下,这篇论文提出的三点改进没有损害ViT原来的简约设计,而且也是实用有效的。
参考
- Three things everyone should know about Vision Transformers
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Training data-efficient image transformers & distillation through attention
- https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py



评论(0)
您还未登录,请登录后发表或查看评论