

论文
Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
主要贡献
- 提出Hybrid memory混合记忆模型
- 在无监督方法中将聚类得到的异常值也加以利用
- 提出统一对比损失
- 提出聚类可靠性评估方法
Pipeline
- 初始化1:在ImageNet上初始化cnn编码网络F
- 初始化2:使用F对源域数据以及目标域数据编码
- 初始化3:源域数据选择类中心存入Hybird memory,目标域数据所有特征存入Hybird menmory。
- 训练1:使用F对输入的batch编码,与Hybird memory中的对应特征进行对比损失计算。
- 如果属于源域则与Hybird memory中对应类的中心特征进行计算
- 如果属于目标域聚类的类别,则与Hybird memory中聚类类别的类中心特征进行计算
- 如果属于目标域聚类异常值,则与Hybird memory中同一个特征进行计算
- 训练2:得到损失反向传播修正F
- 训练3:使用F对源域数据以及目标域数据编码
- 训练4:对特征进行聚类,使用聚类可靠性评估将不可靠的聚类拆成聚类异常值
- 训练5:根据新的编码使用动量更新Hybird memory中对应的值
- 重复训练步骤
对比损失公式
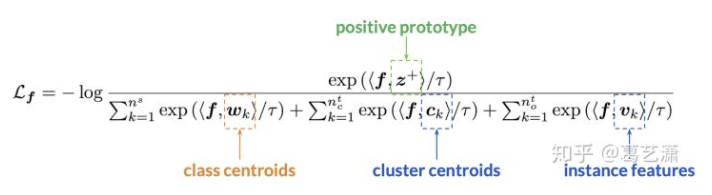
- z+是表示特征向量f属于那个类别的特征,对应于pipline中的训练1中的分析
- <a,b>表示a和b向量点乘,因为向量都L2 nomal处理了所以点乘来代替余弦计算</a,b>
- 分母就是特征向量与其他类别的余弦距离的计算和。
- 整个式子优化到0则log的对数优化到1,则优化分子等于分母,即f和z+的距离最近其他都最小。
动量更新Hybird memory
对于源域类别的更新,对同一类别的图片编码的特征求均值对应更新Hybird memory同一类别: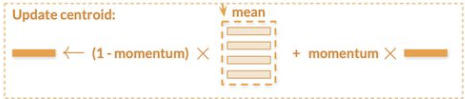
对于目标域类别的更新,直接根据索引找到对应的向量更新: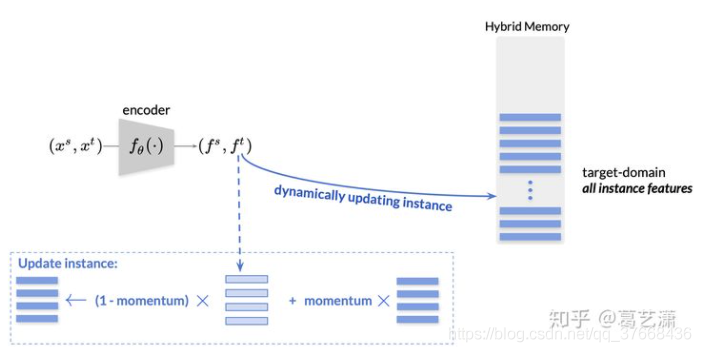
聚类可靠性
通俗的说就是:一个可靠的聚类应当在多尺度的聚类环境下保持稳定。从每个点来看,正常聚类用一个面积为10的包围圈包括了它,然后用一个面积为8的包围圈也包括了他并且这次的包围圈和面积为10的包围圈包围相同的点的个数大于一个设置的阈值超参,然后用一个面积为8的包围圈也包括了他并且这次的包围圈和面积为12的包围圈包围相同的点的个数大于一个设置的阈值超参。满足上面两个条件这个点就属于聚类结果,不然就属于离群点。
SpCL的两种任务
任务一:UDA,无监督领域泛化
这个主要是利用源域的数据来优化目标域的性能,目标域数据无标签。任务二:USL,无监督
只使用目标域的数据,且目标域数据无标签。
任务一和任务二在使用SpCl的主要区别在于对比损失的计算有差异(去掉了和源域类中心计算对比损失)以及memory存储的特征不同(不存源域的类中心特征)。
对于任务一,对比损失如下:
对于任务二,对比损失如下:
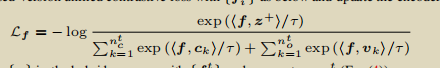
论文
Refining Pseudo Labels with Clustering Consensus over Generations for Unsupervised Object Re-identification
主要贡献
- 结合前面一轮的伪标签来优化这一轮的伪标签,可以很好的兼容现有的方法。
Pipeline
硬标签
- 在imagenet上训练网络f
- 使用f对训练数据提取特征
- 使用dbscan聚类算法进行聚类,得到硬标签Y(1)
- 计算本次聚类t时刻每一个类与上一次聚类t-1时刻每一个类的IOU,存入矩阵C
- 利用矩阵C和上一次聚类t-1的硬标签根据RLCC算法(见# RLCC)计算从t-1传播到t的的伪标签Y(1>2)
- 根据本次模型的输出特征聚类得到本次的硬伪标签Y_hard(2)
- 使用momentum思想用Y(1>2)和Y_hard(2)得到最终本次的伪标签Y(2)
软标签
- 在imagenet上训练网络f
- 使用f对训练数据提取特征
- 使用dbscan聚类算法进行聚类
- 计算本次聚类t时刻每一个类与上一次聚类t-1时刻每一个类的IOU,存入矩阵C
- 利用保存的t-1时刻的模型对样本前向传播从分类层拿到软标签Y(1)
- 利用矩阵C和上一次软标签根据RLCC算法计算从t-1传播到t的的伪标签Y(1>2)
- 根据本次模型的输出特征聚类得到本次的硬伪标签Y_hard(2)
- 使用momentum思想用Y(1>2)和Y_hard(2)得到最终本次的伪标签Y(2)
两者相比,软标签的时候需要额外的存储t-1时刻的模型,用来计算分类得到的软标签。
为什么要存储模型不能直接存储当时的软标签呢?
因为在t时刻是没有使用这时候模型的分类层,而是使用了t-1时刻的分类层,因此反向传播的时候相当于优化了t-1时候分类层的参数。换句话说就是在t时刻,这时候分类层的参数适配的是t-1时刻的类别。所以必须额外存储t-1时候的模型在t时刻来计算。
RLCC
算法流程如图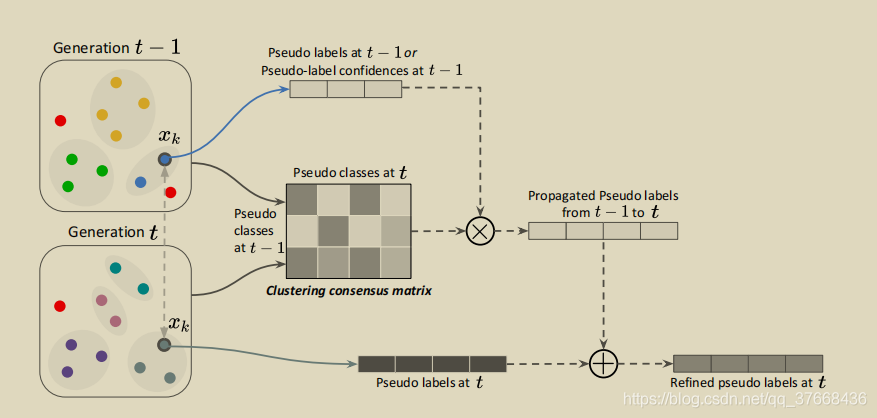
首先,下图表示t-1时刻和t时刻不同的聚类结果,在t-1时刻有3个聚类,在t时刻有4个聚类: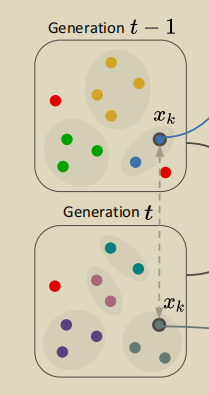
因此可以根据t-1时刻和t时刻每个聚类一一计算包含相同实例的比例可以得到一个3 _ 4的矩阵C,注意这里C对每一行进行了归一化,就是每一行的和为1,如下图 :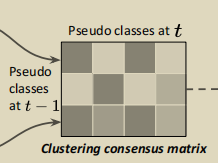
从t-1时刻的模型根据聚类得到硬伪标签或者根据分类层输出得到软伪标签Y(1),Y(1)的维度和t-1时刻聚类的类别数相同都是3,如下图:
将矩阵C和标签Y(1)进行矩阵乘得到从t-1时刻传播到t时刻的伪标签Y(1>2),矩阵乘公式:Y(1>2) = CT_Y(1),如下图: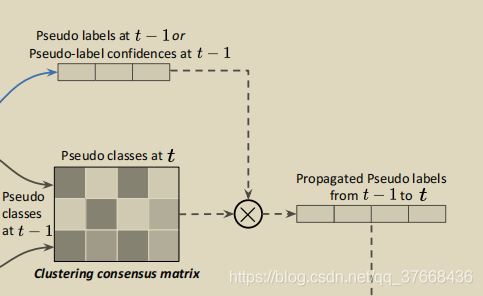
公式不好理解,在图示上演示一个Y(1)为硬标签情况的计算,下图很好理解,如果Y(1)第一列是1,则取C中的第一行,那如果不是硬标签换成软标签原理类似,就是C中不同行根据软标签的权重取最后累加得到Y(1>2)的每一项。
得到Y(1>2)后,然后根据t时刻聚类得到t时刻的硬标签Y_hard(2),两者根据一个权重参数a分配再相加得到最后的伪标签Y(2),如下图圈出部分: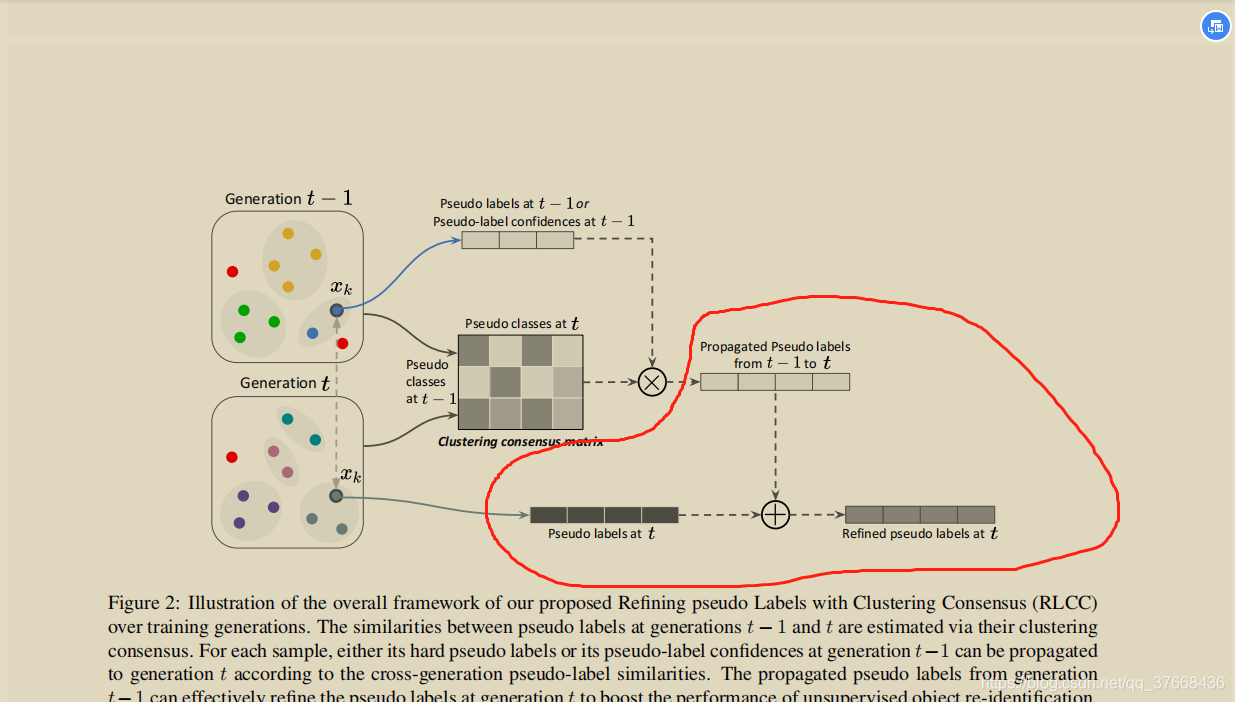
将RCLL应用于SpCl
RCLL这个方法是根据迭代过程中相邻两个时刻伪标签来精炼当前时刻的伪标签,SpCl是作者提出的一个在无监督领域泛化和无监督领域reid的一个有效的方法,SpCl的目的也是提高伪标签的可靠性,可以将RCLL方法结合进去。
因为SpCl使用的是对比损失,并且该方法没有分类层所以得到软标签的时候需要特殊操作。软标签根据当前样本与memory中的所有样本计算对比损失得到,公式如下: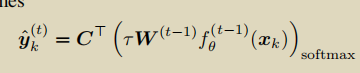
W·f表示的就是计算样本k的对比损失得到的软标签,前面的系数是用来放大置信度的超参。
效果
RLCC的效果
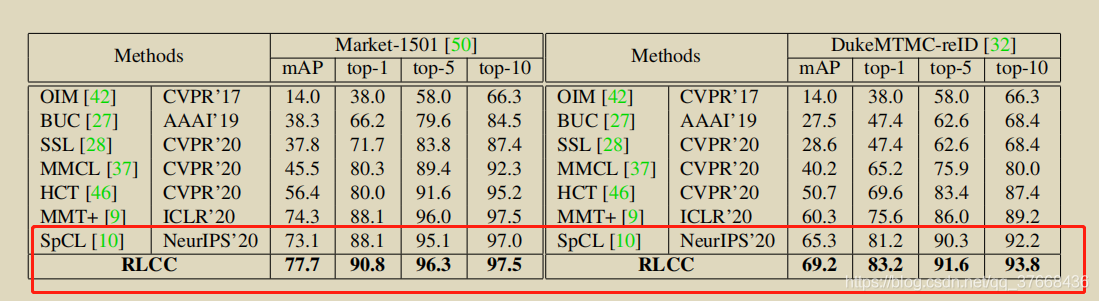
作者的baseline为SpCl,在两个person reid任务Market-1501和DukeMTMC上涨点分别4.6%和3.9%:
MSMT17上涨点8.8%: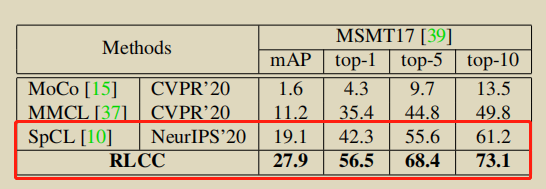
在VeRi776上涨点2.7%:
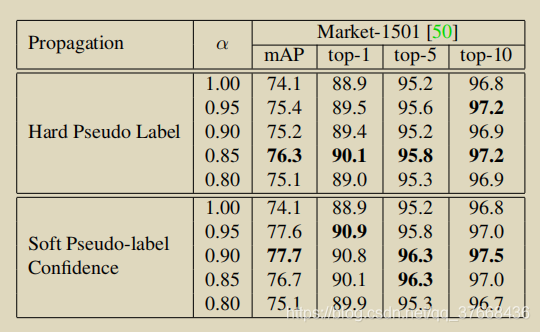
硬伪标签效果对比



评论(0)
您还未登录,请登录后发表或查看评论