

前言
本文开源代码地址:https://github.com/PaddleEdu/OCR-models-PaddlePaddle/tree/main/PSENet
aistudio在线运行地址:https://aistudio.baidu.com/aistudio/projectdetail/1945560
论文分析
该论文解决了什么问题?
首先文字检测一般有两种方法:
1、 基于回归的方法,定位文字存在无法处理弯曲文本的问题,因为回归的方法一般会生成锚框,一般是矩形框,而弯曲的文本用矩形框不是很好包括。
2、 基于图像分割的方法可以定位弯曲文本,但是相邻两行文本粘合过紧的话分割模型容易误认为是同一行文本,也就是分割的方法很难解决文本粘合过紧的问题。
因此该论文提出了PSE算法,Progressive Scale Expansion Network,该算法基于BFS的原理。PSENET对文本框的检测首先采取的是图像分割的方法,这样psenet可以解决弯曲文本的问题,接着得到网络的分割结果后该算法的后处理部分采用的是设计的PSE算法来定位文本该算法的贡献在于可以有效的区分相邻文本。
PSENet在CTW1500数据集上表现优越超当时的SOTA6.6%!
Pipeline
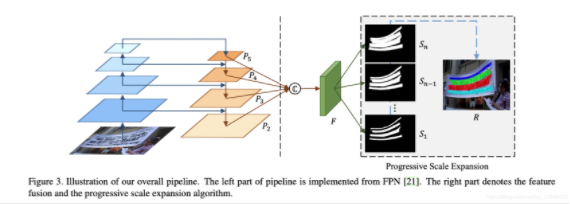
这张图是完整的pipeline,最左侧的四张蓝色块是主干网络(resnet50)从原图提取的特征,从下往上分别是从resnet50 layer1 layer2 layer3 layer4拿出来的特征(f2,f3,f4,f5):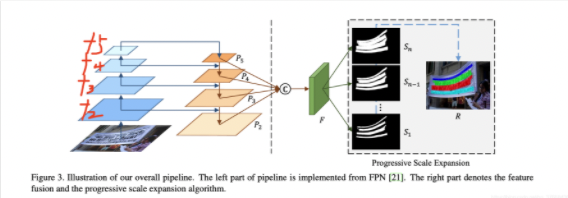
shape分别是:
- f2:[bs,256,184,184]
- f3:[bs,512,92,92]
- f4:[bs,1024,46,46]
- f5:[bs,2048,23,23]
拿到特征后,作者参考FPN的原理对不同尺度的特征进行concat到C中,首先横线上的操作是conv - bn - relu修改f2,f3,f4,f5的channel数为256: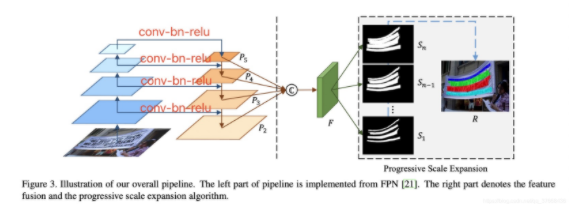
因此横线输出的的shape从下往上分别为:
- [bs,256,184,184]
- [bs,256,92,92]
- [bs,256,46,46]
- [bs,256,23,23]
然后根据图上的箭头:
P5 = f5
P4 = conv-bn-relu(f4) + P5
P3 = conv-bn-relu(f3) + P4
P2 = conv-bn-relu(f2) + P3
你可能注意到了这里conv-bn-relu(f4) + P5不可以直接加的,因为shape不一样,所以做加法之前对P5进行上采样到f4相同大小再做add,其他同理。
拿到了P2、P3、P4、P5之后,直接进行concat就得到了图上的C,自然他的shape就是[bs,1024,184,184](这里的1024就是4*256)
最后对C采用conv-bn-relu-conv输出一个通道数为num_class的特征,论文里这个值设成了7,这7个特征就是图中的Sn:
拿到了这7个S后采用PSE算法进行扩张得到最后的分割结果。
PSE算法原理

这是一个生动的例子(见图4),它解释了逐步扩展尺度算法的过程,其中心思想来自广度优先搜索(BFS)算法。 在示例中,我们有3个分割结果S = {S1,S2,S3}。 首先,基于最小的分割结果S1,可以找到4个不同的连接组件C = {c1,c2,c3,c4}作为初始化。 图4(b)中具有不同颜色的区域分别表示这些不同的连接组件。 到目前为止,我们已经检测到所有文本实例的中心部分(即最小分割结果)。 然后,通过合并S2和S3中的像素,逐步扩展检测到的内核。 两次缩放的结果分别显示在图(c)和图(d)中。 最后,我们提取图(d)中用不同颜色标记的连接组件作为文本实例的最终预测。
图(g)示出了膨胀的过程。该扩展基于“广度优先搜索”算法,该算法从多个内核的像素开始,并迭代合并相邻的文本像素。注意,在扩展过程中可能会有冲突的像素,如图(g)中的红色框所示。在我们的实践中,解决冲突的原则是,混淆的像素只能在先到先得的基础上由单个内核合并。由于采用了“渐进式”扩展程序,这些边界冲突将不会影响最终的检测和性能。
伪代码:
训练技巧
第一:我们添加了更丰富的开源数据集去训练我们的pretrain模型,对比原论文中的实验细节作者的pretrain模型没具体说验证精度在那个数据集上但是给了准确的指标,因此怀疑是在IC15上测试的,我们评估pretrain的指标选择的是将我们准备的ic13 ic17 coco数据集随机划分训练测试集,在划分的测试集上选择最优的pretrain模型。然后使用这个pretrain模型在total_text数据集上finetune就直接超过了作者原论文的最高的指标3个点左右。
第二:我们采用了随机旋转,随机镜像,随机尺度缩放三种数据增强的手段,在随机尺度缩放上采用了一点训练技巧,我们程序里设计了缩放的shortsize,就是用这个设置的值除以传入图片的短边得到一个缩放比例,然后因为ic15里面这个图片尺寸固定大小,所以我们预设了7组参数从0.7到1.3,得到缩放比例后随机从这7组参数抽1个乘上缩放比例,这样的话图片的尺寸就不定了。然后在训练的时候最开始这个shortsize设置的是1024,我们实验完发现在ic15评测时候presicion比较高有86左右,而recall只有79左右,评估识别结果发现小字,模糊的字,密集文本有大量的漏检情况,因此我们用这个1024训练的模型做为pretrain模型,修改shortsize为1260然后进行finetune,训练完后模型涨点1个点左右,hmean达到84多,训练结果最差的效果还是小字和模糊的字为主。然后训练的过程中我们发现在经过100多个epoch训练的时候模型的loss有震荡的趋势,基本也不收敛了 ,参考论文Improving Generalization Performance by Switching from Adam to SGD的结论:前期用Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解。然后我们加载1260的结果为pretrain并shortsize切换到1480更换优化器为SGD后模型涨点1个点左右最优效果hmean达到85.1超过作者开源的最好模型3个点。



评论(0)
您还未登录,请登录后发表或查看评论