

人脸识别是指程序对输入的人脸图像进行判断,并识别出其对应的人的过程。人脸识别程序像我们人类一样,“看到”一张人脸后就能够分辨出这个人是家人、朋友还是明星。当然,要实现人脸识别,首先要判断当前图像内是否出现了人脸,也即人脸检测。只有检测到图像中出现了人脸,才能根据人脸判断这个人到底是谁。本文分别介绍人脸检测和人脸识别的基本原理,并分别给出了使用OpenCV 实现它们的简单案例。
1. 人脸检测
当我们预测的是离散值时,进行的是“分类”。例如,预测一个孩子能否成为一名优秀的运动员,其实就是看他是被划分为“好苗子”还是“普通孩子”的分类。
对于只涉及两个类别的“二分类”任务,我们通常将其中一个类称为“正类”(正样本),另一个类称为“负类”(反类、负样本)。
例如,在人脸检测中,主要任务是构造能够区分包含人脸实例和不包含人脸实例的分类器。这些实例被称为“正类”(包含人脸图像)和“负类”(不包含人脸图像)。
1.1 基本原理
OpenCV 提供了三种不同的训练好的级联分类器,下面简单介绍其中涉及的一些概念。
1. 级联分类器
级联分类器是将多个简单的分类器按照一定的顺序级联而成的。
级联分类器的优势是,在开始阶段仅进行非常简单的判断,就能够排除明显不符合要求的实例。在开始阶段被排除的负类,不再参与后续分类,这样能极大地提高后面分类的速度。
OpenCV 提供了用于训练级联分类器的工具,也提供了训练好的用于人脸定位的级联分类器,都可以作为现成的资源使用。
2. Haar级联分类器
OpenCV 提供了已经训练好的Haar 级联分类器用于人脸定位。
有关级联分类器的原理可以参考这篇文章:基于Haar特征的Adaboost级联人脸检测分类器
1.2 级联分类器的使用
为了训练针对特定类型对象的级联分类器,OpenCV 提供了专门的软件工具。在OpenCV根目录下的build 文件夹下,查找build\x86\vc12\bin 目录(不同的OpenCV 版本,路径会略有差异),会找到opencv_createsamples.exe 和opencv_traincascade.exe,这两个.exe 文件可以用来训练级联分类器。
训练级联分类器很耗时,如果训练的数据量较大,可能需要好几天才能完成。在OpenCV中,有一些训练好的级联分类器供用户使用。这些分类器可以用来检测人脸、脸部特征(眼睛、鼻子)、人类和其他物体。这些级联分类器以XML 文件的形式存放在OpenCV 源文件的data目录下,加载不同级联分类器的XML 文件就可以实现对不同对象的检测。
OpenCV 自带的级联分类器存储在OpenCV 根文件夹的data 文件夹下。该文件夹包含三个子文件夹:haarcascades、hogcascades、lbpcascades,里面分别存储的是Harr 级联分类器、HOG级联分类器、LBP 级联分类器。
其中,Harr 级联分类器多达20 多种(随着版本更新还会继续增加),提供了对多种对象的检测功能。部分级联分类器如表所示。
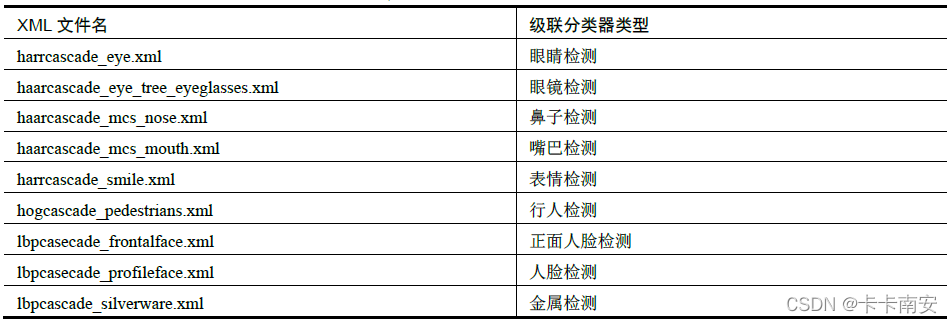
加载级联分类器的语法格式为:
<CascadeClassifier object> = cv2.CascadeClassifier( filename )
式中,filename 是分类器的路径和名称。
下面的代码是一个调用实例:
faceCascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
使用级联分类器时需要注意:如果你是通过在anaconda 中使用pip 的方式安装的OpenCV,则无法直接获取级联分类器的XML 文件。可以通过以下两种方式获取需要的级联分类器XML文件:
- 安装 OpenCV 后,在其安装目录下的data 文件夹内查找XML 文件。
- 直接在网络上找到相应XML 文件,下载并使用。
同样,如果使用opencv_createsamples.exe 和opencv_traincascade.exe,也需要采用上述方式获取XML 文件。
1.3 函数介绍
在 OpenCV 中,人脸检测使用的是cv2.CascadeClassifier.detectMultiScale()函数,它可以检测出图片中所有的人脸。该函数由分类器对象调用,其语法格式为:
objects = cv2.CascadeClassifier.detectMultiScale( image[, scaleFactor[, minNeighbors[, flags[, minSize[, maxSize]]]]] )
- image:待检测图像,通常为灰度图像。
- scaleFactor:表示在前后两次相继的扫描中,搜索窗口的缩放比例。
- minNeighbors:表示构成检测目标的相邻矩形的最小个数。默认情况下,该值为3,意味着有3 个以上的检测标记存在时,才认为人脸存在。如果希望提高检测的准确率,可以将该值设置得更大,但同时可能会让一些人脸无法被检测到。
- flags:该参数通常被省略。在使用低版本OpenCV(OpenCV 1.X 版本)时,它可能会被设置为CV_HAAR_DO_CANNY_PRUNING,表示使用Canny 边缘检测器来拒绝一些区域。
- minSize:目标的最小尺寸,小于这个尺寸的目标将被忽略。
- maxSize:目标的最大尺寸,大于这个尺寸的目标将被忽略。
- objects:返回值,目标对象的矩形框向量组。
1.4 案例介绍
import cv2
#读取待检测的图像
image = cv2.imread(‘dface3.jpg’)
# 获取xml文件,加载人脸检测器
faceCascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
# 色彩转换,转换为灰度图像
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
# 调用函数detectMultiScale
faces = faceCascade.detectMultiScale(
gray,
scaleFactor = 1.15,
minNeighbors = 5,
minSize = (5,5)
)
print(faces)
#打印输出测试结果
print(“发现{0}个人脸!”.format(len(faces)))
#逐个标记人脸
for(x,y,w,h) in faces:
# cv2.rectangle(image,(x,y),(x+w,y+w),(0,255,0),2) #矩形标注
cv2.circle(image,(int((x+x+w)/2),int((y+y+h)/2)),int(w/2),(0,255,0),2)
#显示结果
cv2.imshow(“dect”,image)
#保存检测结果
cv2.imwrite(“re.jpg”,image)
cv2.waitKey(0)
cv2.destroyAllWindows()
运行后输出以下内容:
[[129 59 61 61]
[ 35 76 62 62]
[565 65 61 61]
[443 62 71 71]
[290 13 77 77]]
发现 5 个人脸!


2. LBPH 人脸识别
人脸识别的第一步,就是要找到一个模型可以用简洁又具有差异性的方式准确反映出每个人脸的特征。识别人脸时,先将当前人脸采用与前述同样的方式提取特征,再从已有特征集中找出当前特征的最邻近样本,从而得到当前人脸的标签。
OpenCV 提供了三种人脸识别方法,分别是LBPH 方法、EigenFishfaces 方法、Fisherfaces方法。本节主要对LBPH 方法进行简单介绍。
LBPH(Local Binary Patterns Histogram,局部二值模式直方图)所使用的模型基于LBP(Local Binary Pattern,局部二值模式)算法。LBP 最早是被作为一种有效的纹理描述算子提出的,由于在表述图像局部纹理特征上效果出众而得到广泛应用。
2.1 基本原理
LBP 算法的基本原理是,将像素点A 的值与其最邻近的8 个像素点的值逐一比较:
- 如果 A 的像素值大于其临近点的像素值,则得到0。
- 如果 A 的像素值小于其临近点的像素值,则得到1。
最后,将像素点A 与其周围8个像素点比较所得到的0、1 -值连起来,得到一个8位的二进制序列,将该二进制序列转换为十进制数作为点A 的LBP 值。
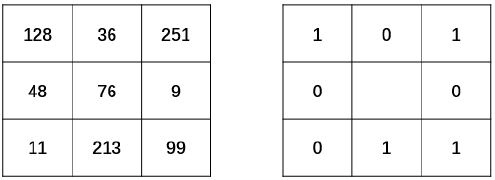
完成二值化以后,任意指定一个开始位置,将得到的二值结果进行序列化,组成一个8 位的二进制数。例如,从当前像素点的正上方开始,以顺时针为序得到二进制序列“01011001”。
最后,将二进制序列“01011001”转换为所对应的十进制数“89”,作为当前中心点的像素值,如图所示。

对图像逐像素用以上方式进行处理,就得到LBP 特征图像,这个特征图像的直方图被称为LBPH,或称为LBP 直方图。
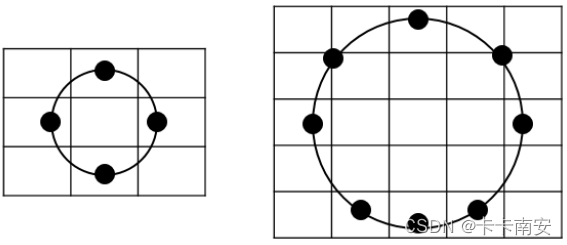
为了得到不同尺度下的纹理结构,还可以使用圆形邻域,将计算扩大到任意大小的邻域内。
人脸的整体灰度由于受到光线的影响,经常会发生变化,但是人脸各部分之间的相对灰度会基本保持一致。LBP 的主要思想是以当前点与其邻域像素的相对关系作为处理结果,正是因为这一点,在图像灰度整体发生变化(单调变化)时,从LBP 算法中提取的特征能保持不变。因此,LBP 在人脸识别中得到了广泛的应用。
2.2 函数介绍
在 OpenCV 中,可以用函数cv2.face.LBPHFaceRecognizer_create()生成LBPH 识别器实例模型, 然后应用cv2.face_FaceRecognizer.train()函数完成训练, 最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
1. 函数cv2.face.LBPHFaceRecognizer_create()
retval = cv2.face.LBPHFaceRecognizer_create( [, radius[, neighbors[, grid_x[, grid_y[, threshold]]]]])
其中全部的参数都是可选的,含义如下:
- radius:半径值,默认值为1。
- neighbors:邻域点的个数,默认采用8 邻域,根据需要可以计算更多的邻域点。
- grid_x:将LBP 特征图像划分为一个个单元格时,每个单元格在水平方向上的像素个数。该参数值默认为8,即将LBP 特征图像在行方向上以8 个像素为单位分组。
- grid_y:将LBP 特征图像划分
- 为一个个单元格时,每个单元格在垂直方向上的像素个数。该
参数值默认为8,即将LBP 特征图像在列方向上以8 个像素为单位分组。
- threshold:在预测时所使用的阈值。如果大于该阈值,就认为没有识别到任何目标对象。
2. 函数cv2.face_FaceRecognizer.train()
函数 cv2.face_FaceRecognizer.train()对每个参考图像计算LBPH,得到一个向量。每个人脸都是整个向量集中的一个点。该函数的语法格式为:
None = cv2.face_FaceRecognizer.train( src, labels )
- src:训练图像,用来学习的人脸图像。
- labels:标签,人脸图像所对应的标签。
3. 函数cv2.face_FaceRecognizer.predict()
函数 cv2.face_FaceRecognizer.predict()对一个待测人脸图像进行判断,寻找与当前图像距离最近的人脸图像。与哪个人脸图像最近,就将当前待测图像标注为其对应的标签。当然,如果待测图像与所有人脸图像的距离都大于函数cv2.face.LBPHFaceRecognizer_create()中参数threshold 所指定的距离值,则认为没有找到对应的结果,即无法识别当前人脸。
label, confidence = cv2.face_FaceRecognizer.predict( src )
式中参数与返回值的含义为:
- src:需要识别的人脸图像。
- label:返回的识别结果标签。
- confidence:返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0 表示完全匹配。通常情况下,认为小于50 的值是可以接受的,如果该值大于80 则认为差别较大。
2.3 案例介绍
本例中有两个人,每个人有两幅人脸图像,用于机器学习。然后,我们用程序识别第5 幅人脸图像(为其中一个人的人脸),观察识别结果。
用于学习的 4 幅人脸图像如图所示,从左到右图像的名称分别为a1.png、a2.png、b1.png、b2.png。

这 4 幅图像中,前两幅图像是同一个人,将其标签设定为“0”;后两幅图像是同一个人,将其标签设定为“1”。
用于识别的人脸图像如图所示,该图像的名称a3.png。

import cv2
import numpy as np
images=[]
images.append(cv2.imread(“a1.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“a2.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“b1.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“b2.png”,cv2.IMREAD_GRAYSCALE))
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.train(images, np.array(labels))
predict_image=cv2.imread(“a3.png”,cv2.IMREAD_GRAYSCALE)
label,confidence= recognizer.predict(predict_image)
print(“label=”,label)
print(“confidence=”,confidence)
运行上述程序,识别结果为:
label= 0
confidence= 67.6856704732354
从输出结果可以看到,标签值为“0”,置信区间值为68。这说明图像a3.png被识别为标签0所对应的人脸图像,即认为当前待识别图像a3.png 中的人与图像a1.png、a2.png 中的是同一个人。
3. EigenFaces 人脸识别
EigenFaces 通常也被称为特征脸,它使用主成分分析(PCA)方法将高维的人脸数据处理为低维数据后(降维),再进行数据分析和处理,获取识别结果。
3.1 基本原理
在现实世界中,很多信息的表示是有冗余的。例如,表中所列出的一组圆的参数中就存在冗余信息。
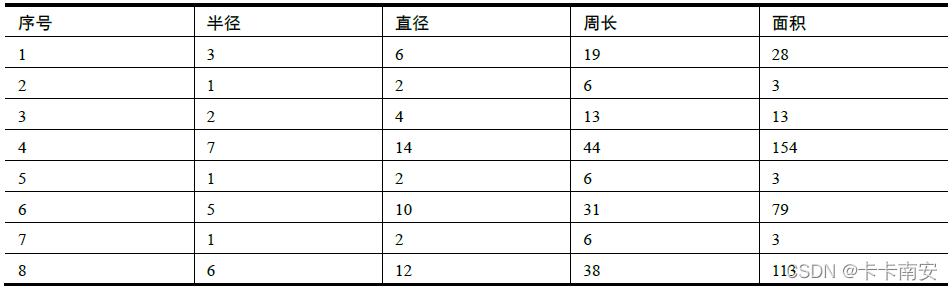
在上表所示的参数中,各个参数之间存在着非常强的相关性:
- 直径 = 2×半径
- 周长 = 2π×半径
- 面积 = π×半径×半径
可以看到,直径、周长和面积都可以通过半径计算得到。
在进行数据分析时,如果我们希望更直观地看到这些参数的值,就需要获取所有字段的值。但是,在比较圆的面积大小时,仅使用半径就足够了,此时其他信息对于我们来说就是“冗余”的。
因此,我们可以理解“半径”就是上表所列数据中的“主成分”,我们将“半径”从上述数据中提取出来供后续分析使用,就实现了“降维”。
当然,上面例子的数据非常简单、易于理解,而在大多数情况下,我们要处理的数据是比较复杂的。很多时候,我们可能无法直接判断哪些数据是关键的“主成分”,所以就要通过PCA方法将复杂数据内的“主成分”分析出来。
EigenFaces 就是对原始数据使用PCA 方法进行降维,获取其中的主成分信息,从而实现人脸识别的方法。
3.2 函数介绍
OpenCV 通过函数cv2.face.EigenFaceRecognizer_create()生成特征脸识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
1. 函数cv2.face.EigenFaceRecognizer_create()
retval = cv2.face.EigenFaceRecognizer_create( [, num_components[, threshold]] )
- num_components:在PCA 中要保留的分量个数。当然,该参数值通常要根据输入数据来具体确定,并没有一定之规。一般来说,80 个分量就足够了。
- threshold:进行人脸识别时所采用的阈值。
2. 函数cv2.face_FaceRecognizer.train()
函数 cv2.face_FaceRecognizer.train()对每个参考图像进行EigenFaces 计算,得到一个向量。每个人脸都是整个向量集中的一个点。该函数的语法格式为:
None = cv2.face_FaceRecognizer.train( src, labels )
- src:训练图像,用来学习的人脸图像。
- labels:人脸图像所对应的标签。
3. 函数cv2.face_FaceRecognizer.predict()
函数 cv2.face_FaceRecognizer.predict()在对一个待测人脸图像进行判断时,会寻找与当前图像距离最近的人脸图像。与哪个人脸图像最接近,就将待测图像识别为其对应的标签。
label, confidence = cv2.face_FaceRecognizer.predict( src )
- src:需要识别的人脸图像。
- label:返回的识别结果标签。
- confidence:返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0 表示完全匹配。该参数值通常在0 到20000 之间,只要低于5000,都被认为是相当可靠的识别结果。注意,这个范围与LBPH的置信度评分值的范围是不同的。
3.3 案例介绍
本例中用于学习的4 幅人脸图像如图所示,从左到右图像的名称分别为e01.png、e02.png、e11.png、e12.png。

这 4 幅图像中,前两幅图像是同一个人,将其标签设定为“0”;后两幅图像是同一个人,将其标签设定为“1”。待识别的人脸图像如下图所示,该图像的名称为eTest.png。

import cv2
import numpy as np
images=[]
images.append(cv2.imread(“e01.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“e02.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“e11.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“e12.png”,cv2.IMREAD_GRAYSCALE))
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels))
predict_image=cv2.imread(“eTest.png”,cv2.IMREAD_GRAYSCALE)
label,confidence= recognizer.predict(predict_image)
print(“label=”,label)
print(“confidence=”,confidence)
运行上述程序,识别结果为:
label= 0
confidence= 1592.4971123726827
- 19
从输出结果可以看到,eTest.png 被识别为标签“0”所对应的人脸图像,即认为图像eTest.png与图像e01.png、e02.png 中的是同一个人。
4. Fisherfaces 人脸识别
PCA 方法是EigenFaces 方法的核心,它找到了最大化数据总方差特征的线性组合。不可否认,EigenFaces 是一种非常有效的方法,但是它的缺点在于在操作过程中会损失许多特征信息。
因此,在一些情况下,如果损失的信息正好是用于分类的关键信息,必然会导致无法完成分类。Fisherfaces 采用LDA(Linear Discriminant Analysis,线性判别分析)实现人脸识别。
4.1 基本原理
线性判别分析在对特征降维的同时考虑类别信息。其思路是:在低维表示下,相同的类应该紧密地聚集在一起;不同的类别应该尽可能地分散开,并且它们之间的距离尽可能地远。简单地说,线性判别分析就是要尽力满足以下两个要求:
- 类别间的差别尽可能地大。
- 类别内的差别尽可能地小。
做线性判别分析时,首先将训练样本集投影到一条直线A 上,让投影后的点满足:
- 同类间的点尽可能地靠近。
- 异类间的点尽可能地远离。
做完投影后,将待测样本投影到直线A 上,根据投影点的位置判定样本的类别,就完成了识别。
例如,下图所示的是一组训练样本集。现在需要找到一条直线,让所有的训练样本满足:同类间的距离最近,异类间的距离最远。
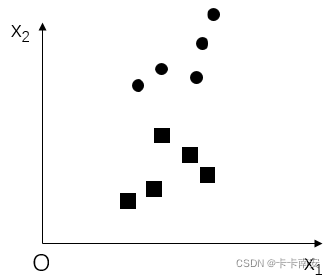
下图中的左图和右图中分别有两条不同的投影线L1 和L2将上图中的样本分别投影到这两条线上,可以看到样本集在L2 上的投影效果要好于在L1 上的投影效果。
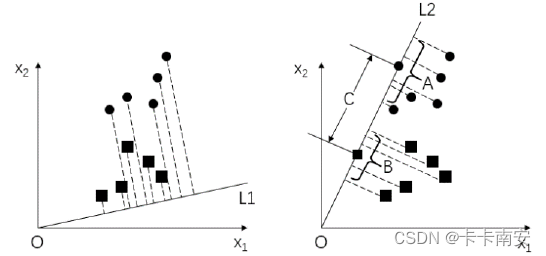
线性判别分析就是要找到一条最优的投影线。以上图中右图投影为例,要满足:
- A、B 组内的点之间尽可能地靠近
- C 的两个端点之间的距离(类间距离)尽可能地远
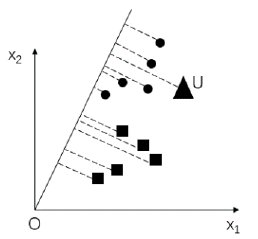
找到一条这样的直线后,如果要判断某个待测样本的分组,可以直接将该样本点向投影线投影,然后根据投影点的位置来判断其所属类别。
例如,在下图中,三角形样本点U 向投影线投影后,其投影点落在圆点的投影范围内,则认为待测样本点U 属于圆点所在的分类。
4.2 函数介绍
在 OpenCV 中,通过函数cv2.face.FisherFaceRecognizer_create()生成Fisherfaces 识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
1. 函数cv2.face.FisherFaceRecognizer_create()
retval = cv2.face.FisherFaceRecognizer_create( [, num_components[, threshold]] )
- num_components:使用Fisherfaces 准则进行线性判别分析时保留的成分数量。可以采用默认值“0”,让函数自动设置合适的成分数量。
- threshold:进行识别时所用的阈值。如果最近的距离比设定的阈值threshold 还要大,函数会返回“-1”。
2. 函数cv2.face_FaceRecognizer.train()
函数 cv2.face_FaceRecognizer.train()对每个参考图像进行Fisherfaces 计算,得到一个向量。每个人脸都是整个向量集中的一个点。该函数的语法格式为:
None = cv2.face_FaceRecognizer.train( src, labels )
式中各个参数的含义为:
- src:训练图像,即用来学习的人脸图像。
- labels:人脸图像所对应的标签。
3. 函数cv2.face_FaceRecognizer.predict()
函数 cv2.face_FaceRecognizer.predict()在对一个待测人脸图像进行判断时,寻找与其距离最近的人脸图像。与哪个人脸图像最接近,就将待测图像识别为其对应的标签。该函数的语法格式为:
label, confidence = cv2.face_FaceRecognizer.predict( src )
- src:需要识别的人脸图像。
- label:返回的识别结果的标签。
- confidence:置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0 表示完全匹配。该值通常在0到20 000 之间,若低于5000,就认为是相当可靠的识别结果。需要注意,该评分值的范围与EigenFaces 方法的评分值范围一致,与LBPH 方法的评分值范围不一致。
4.3 案例介绍
本例中用于学习的4 幅人脸图像如图所示,它们的名称从左至右分别为f01.png、f02.png、f11.png、f12.png。

这 4 幅图像中,前两幅图像是同一个人,将其标签设定为“0”;后两幅图像是同一个人,将其标签设定为“1”。待识别的人脸图像如下图所示,该图像的名称为fTest.png。

import cv2
import numpy as np
images=[]
images.append(cv2.imread(“f01.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“f02.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“f11.png”,cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread(“f12.png”,cv2.IMREAD_GRAYSCALE))
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.FisherFaceRecognizer_create()
recognizer.train(images, np.array(labels))
predict_image=cv2.imread(“fTest.png”,cv2.IMREAD_GRAYSCALE)
label,confidence= recognizer.predict(predict_image)
print(“label=”,label)
print(“confidence=”,confidence)
运行上述程序,识别结果为:
label= 0
confidence= 92.5647623298737
- 19
从输出结果可以看到,fTest.png 被识别为标签“0”所对应的人脸图像,即认为人脸图像fTest.png 与图像f01.png、f02.png 所表示的是同一个人。
5. 最后
从官网下载并安装OpenCV 后,会得到一些有用的学习示例。这些示例通常位于“安装路径\sources\samples\python”下面,当然不同版本对应的路径可能略有差异。
这些示例对于学习OpenCV 都非常有帮助。可以通过研读上述示例的源代码来学习面向Python 语言的OpenCV 库。



评论(0)
您还未登录,请登录后发表或查看评论