

论文:YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers
Github:https://github.com/reu2018DL/YOLO-LITE
论文致力于设计一个网络(cpu速度大于10FPS,PASCAL VOC精度大于30%),因此基于YOLO-v2,提出了一个cpu端的或者端侧的实时检测框架YOLO-LITE。在PASCAL VOC 上取得了33.81%的map,在COCO上取得了12.26%的map,实时性达到了21FPS。

最终识别结果如下,

论文贡献:
(1)贡献了非gpu端的浅层实时检测框架
(2)BatchNorm对于浅层的网络并不需要,虽然可以对精度有1%的提升,使得训练速度也加快,但是缺点是带来了参数量的增加,推理速度的延迟。因此对于浅层网络可以尝试去掉BN。
LOSS函数:
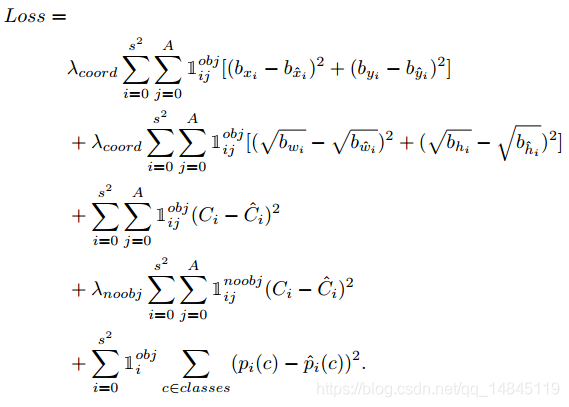
SXS:表示yolo中分块的grid数目,横纵各S个,最终形成SxS个grid。
A:每个grid中的预测的边框数目
λcoord :坐标中心和长宽的系数
λnoobj :预测没有物体的分数的系数
C:预测的有没物体的分数confidence
P(c):分类的类别的分数
1obj ij :预测和groundtruth的IOU大于规定阈值时为1,其他为0
1noobjij: 预测和groundtruth的IOU小于规定阈值时为1,其他为0
整个loss包含了预测的中心坐标的loss,预测边框的宽,高的loss,分类的有物体的loss,没有物体的loss,物体类别的loss。
平均准确性的公式:

P(k) :在IOU阈值为k时的准确性
∆r(k) :在IOU阈值为k时的召回率
优化策略:
(1)输入图片的大小
输入图片的大小减半后,会使得推理速度从2.4 FPS增加为6.94 FPS,但是也带来精度的损失,使得精度从 40.48% 降为30.24%。
本论文决定采用精度换取速度的方式,使用输入减半的策略。从yolo-v2的416_416_3的输入变为224_224_3的输入。
(2)Batch Normalization
BN的使用可以有效的缓解covariate shift 和梯度消失的问题,但是带来推理时间的增加。
本论文决定去掉BN层
(3)剪枝Pruning
基于固定阈值的剪枝可以使得AlexNet的参数量减少9倍,VGG的参数量减少13倍,并且对精度的影响很小。基于量化和哈夫曼编码也可以使得参数量减少3-4倍。
但是剪枝的策略对于YOLO-LITE在精度和速度上都没有提升。主要因为剪枝可能对全连接层更加有效。而YOLO-LITE大部分是卷积层。
实验验证:
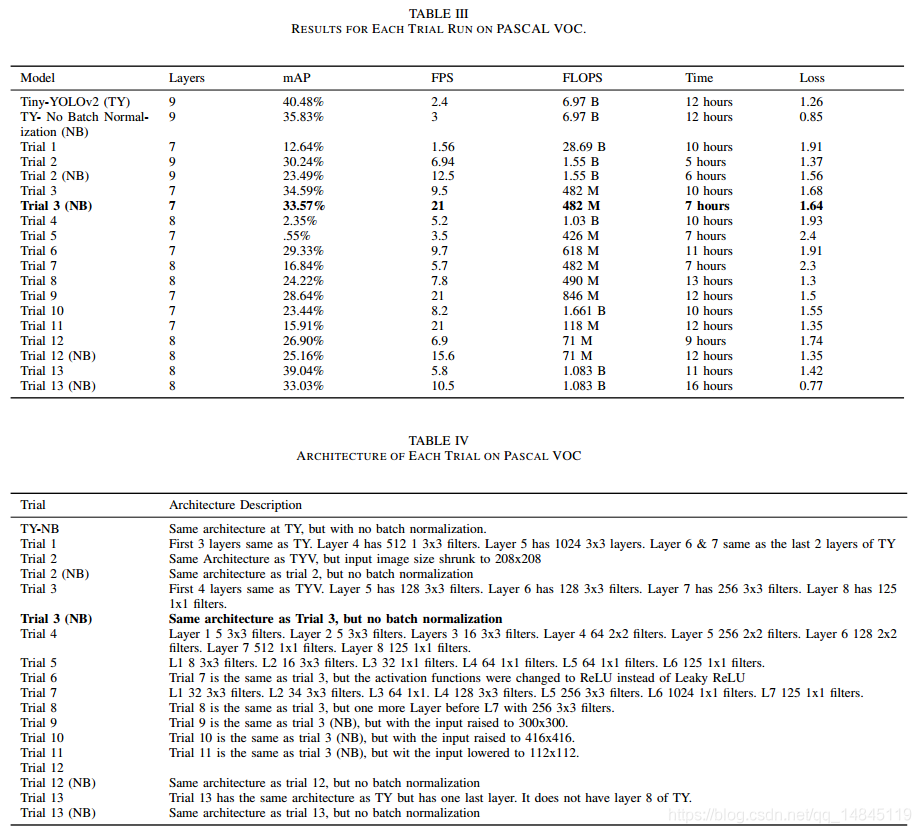
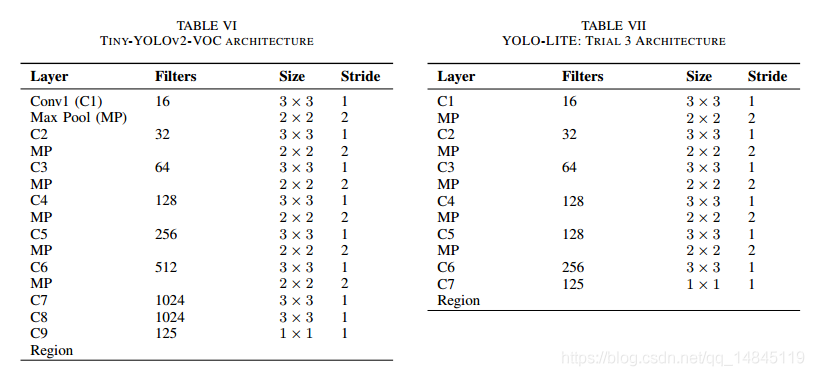
如上表所示,论文进行了13次的不同结构的实验。能满足精度30%+,速度20+map的只有Trial 3(NB)。因此Trial 3(NB)是本文最终的模型,即tiny-yolov2-trial13_noBatch,大小为84M。
与Tiny-YOLO v2的区别在于,
(1)去掉BN
(2)前4层保持不变,第5层有128个通道(3_3),第6层有128个通道(3_3),第7层256个通道(3_3),第8层125个通道(1_1)
实验运行:
这里使用的yolo-v3的程序进行的测试。
-
git clone https://github.com/pjreddie/darknet
-
cd darknet
-
Make -j32
-
-
./darknet detect ./YOLO-LITE/cfg/tiny-yolov2-trial3-noBatch.cfg ./YOLO-LITE/weights/tiny-yolov2-trial3-noBatch.weights data/dog.jpg

总结:
提出了一个yolo-v2的轻量化版本YOLO-LITE,在速度和精度之间做了权衡。最终速度为21FPS,VOC精度为33.77%



评论(0)
您还未登录,请登录后发表或查看评论