

说起深度学习,目前流行的主要有TensorFlow和Pytorch。其中TensorFlow目前主要应用于工业界,Pytorch在学术界用的比较多。TensorFlow目前正在向2.0转型,由于2.0与1.0差异较大,所以TensorFlow的生态社区目前并不是很友好。而Pytorch的生态社区较为完善。
在官网上找到Windows下的安装说明
所以,打开cmd,输入conda install pytorch torchvision cudatoolkit=10.2 -c pytorch 即可自动安装。
编译环境选择在Vscode中进行,没有Tab索引功能,差评~
参考教程为:《PyTorch深度学习实践》完结合集
第一个例子,线性模型
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x_w
def loss(x,y):
y_pred = forward(x)
return (y_pred-y)_(y_pred-y)
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):
print(“w=”,w)
l_sum = 0
for x_val, y_val in zip(x_data,y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val,y_val)
l_sum += loss_val
print(‘\t’,x_val,y_val,y_pred_val,loss_val)
print(‘MSE = ‘, l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list,mse_list)
plt.ylabel(‘Loss’)
plt.xlabel(‘w’)
plt.show()输出结果为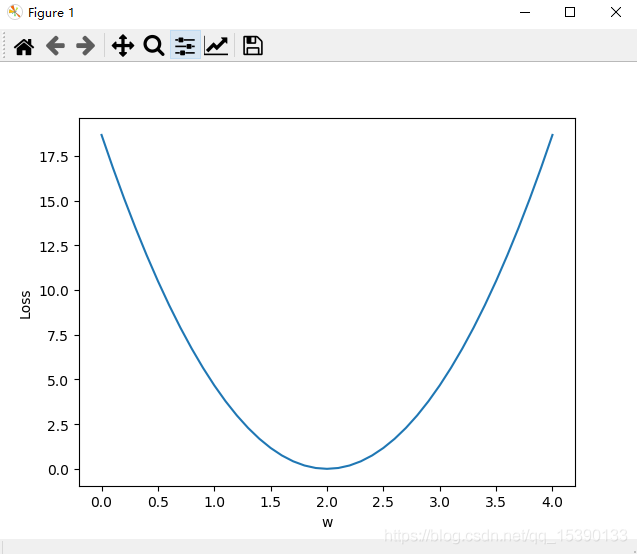
代码含义为通过不断遍历尝试w值,找到最小的损失值,其中loss函数定义为
L
o
s
s
=
(
y
p
r
e
d
−
y
)
2
Loss = (y_{pred}-y)^2
Loss=(ypred−y)2.
下面的代码实现基于梯度下降的线性回归问题。注意显示曲线的时候,需要将for循环中生成的变量保存在list中。

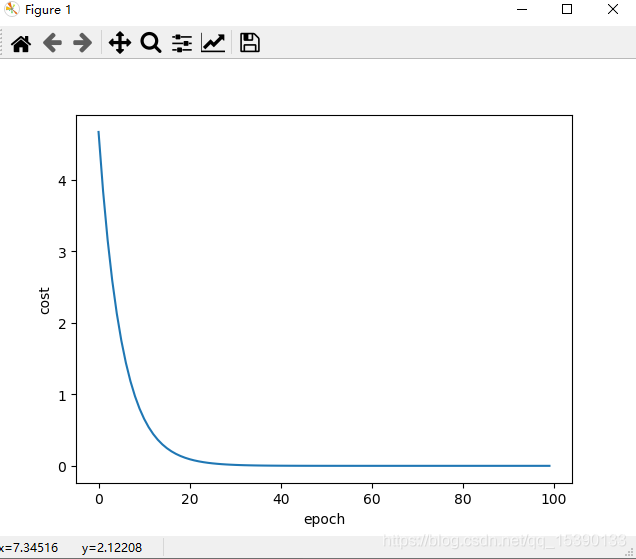
示例三:使用反向梯度,此时已经开始import torch,不再使用numpy库了,所以,梯度函数就不用定义了,一个backward解决问题。
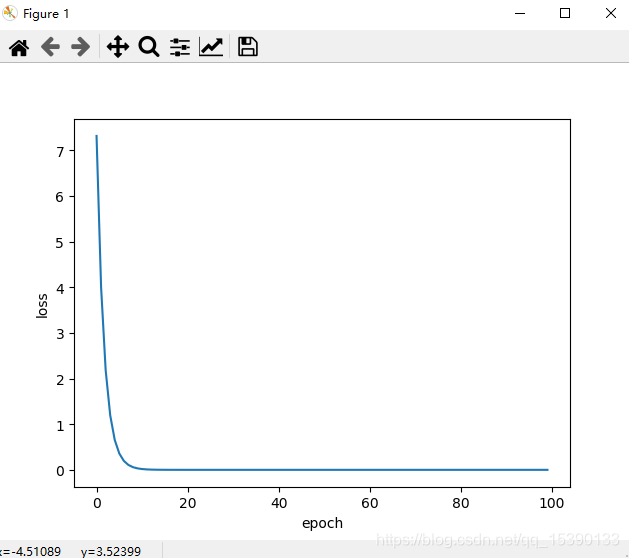
下面的例子采用torch中的库直接完成线性化模型的回归问题。
import torch
import matplotlib.pyplot as plt
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
class LinearModel(torch.nn.Module): #继承于nn.Module
def init(self): #构造函数
super(LinearModel,self).init() #调用父类的构造
self.linear = torch.nn.Linear(1,1) #pytorch中的一个类,nn.linear,
#继承于 Module
# 成员函数 weight,bias
def forward(self,x): #必须叫这个名字 ,父类中有forward这个函数
#这个地方相当于override
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# model.parameter()自动加载权重-all 权重 lr 自动学习率
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(‘w=’,model.linear.weight.item())
print(‘b=’,model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print(‘y_pred=’,y_test.data)下面的代码表示二分类问题
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
import numpy as np
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[0],[0],[1]])
class LogisticRegressionModel(torch.nn.Module): #继承于nn.Module
def __init__(self): #构造函数
super(LogisticRegressionModel,self).__init__() #调用父类的构造
self.linear = torch.nn.Linear(1,1) #pytorch中的一个类,nn.linear,
#继承于 Module
# 成员函数 weight,bias
def forward(self,x): #必须叫这个名字 ,父类中有forward这个函数
#这个地方相当于override
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# model.parameter()自动加载权重-all 权重 lr 自动学习率
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(‘w=’,model.linear.weight.item())
print(‘b=’,model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print(‘y_pred=’,y_test.data)
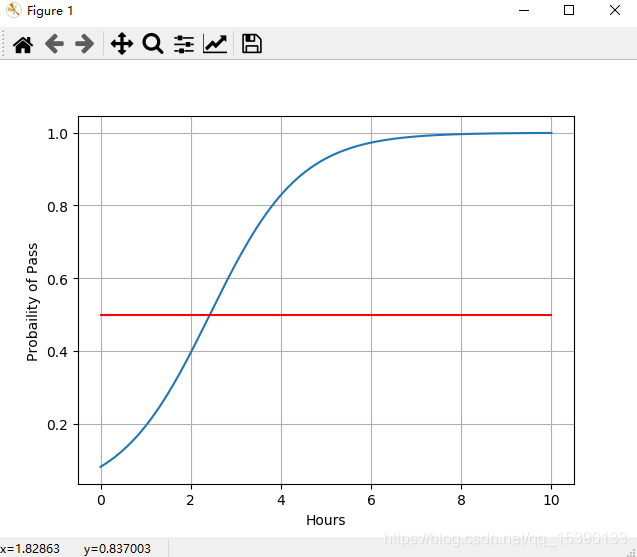
x = np.linspace(0,10,200)
x_t = torch.Tensor(x).view((200,1))
y_t = model(x_t)
y = y_t.data.numpy()
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c=‘r’)
plt.xlabel(‘Hours’)
plt.ylabel(‘Probaility of Pass’)
plt.grid()
plt.show()
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
import numpy as np
from torch.utils.data import Dataset,DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=‘,’,dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset(‘diabetes.csv.gz’)
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers =2)
class Model(torch.nn.Module): #继承于nn.Module
def __init__(self): #构造函数
super(Model,self).__init__() #调用父类的构造
self.linear1 = torch.nn.Linear(8,6) #pytorch中的一个类,nn.linear,
#继承于 Module
# 成员函数 weight,bias
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x): #必须叫这个名字 ,父类中有forward这个函数
#这个地方相当于override
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
# y_pred = torch.sigmoid(self.linear(x))
return x
model = Model()
epoch_list = []
loss_list = []
criterion = torch.nn.BCELoss(reduction=‘sum’)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# model.parameter()自动加载权重-all 权重 lr 自动学习率
if __name__==‘__main__‘:
for epoch in range(100):
for i,data in enumerate(train_loader,0):
inputs,labels = data
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_list.append(epoch)
loss_list.append(loss.item())
plt.plot(epoch_list,loss_list)
# plt.plot([0,10],[0.5,0.5],c=’r’)
plt.xlabel(‘Epoch’)
plt.ylabel(‘Loss’)
plt.grid()
plt.show()上述程序中,存在如下问题
解决方法为:



评论(0)
您还未登录,请登录后发表或查看评论