

从《类别不平衡分布对传统分类器性能的影响机理》文章可以看出,类别不平衡分布是会对各种传统分类算法的性能产生负面影响的。然而,这种负面影响的大小却与很多因素有关,本文和大家探讨这些影响因素。
类别不平衡比率
如《类别不平衡分布对传统分类器性能的影响机理》所述,在不平衡分类问题中,类别不平衡比率(Imbalanced Ratio, IR)是一个较为重要的概念,其具体可表示为多数类样本数与少数类样本数的比值,即 一般而言,IR值越高,其对分类器的负面影响往往也越大,如在朴素贝叶斯分类器中,若P ( c − ) 与P ( c + ) 的差值越大,则显然分类面就会越偏向于少数类区域;在支持向量机分类器中,IR值越大,少数类错误率的上限也会随之越大;而在极限学习机中,IR值越大,其在交叠的致密区域中的子类别不平衡比率S 也可能会越大,从而导致少数类样本被误分的概率更高。为了更清晰地向读者展示类别不平衡比率的影响,这里分别给出了在IR=9(a)IR=90(b)时的样本分布图,具体如下图所示:
一般而言,IR值越高,其对分类器的负面影响往往也越大,如在朴素贝叶斯分类器中,若P ( c − ) 与P ( c + ) 的差值越大,则显然分类面就会越偏向于少数类区域;在支持向量机分类器中,IR值越大,少数类错误率的上限也会随之越大;而在极限学习机中,IR值越大,其在交叠的致密区域中的子类别不平衡比率S 也可能会越大,从而导致少数类样本被误分的概率更高。为了更清晰地向读者展示类别不平衡比率的影响,这里分别给出了在IR=9(a)IR=90(b)时的样本分布图,具体如下图所示: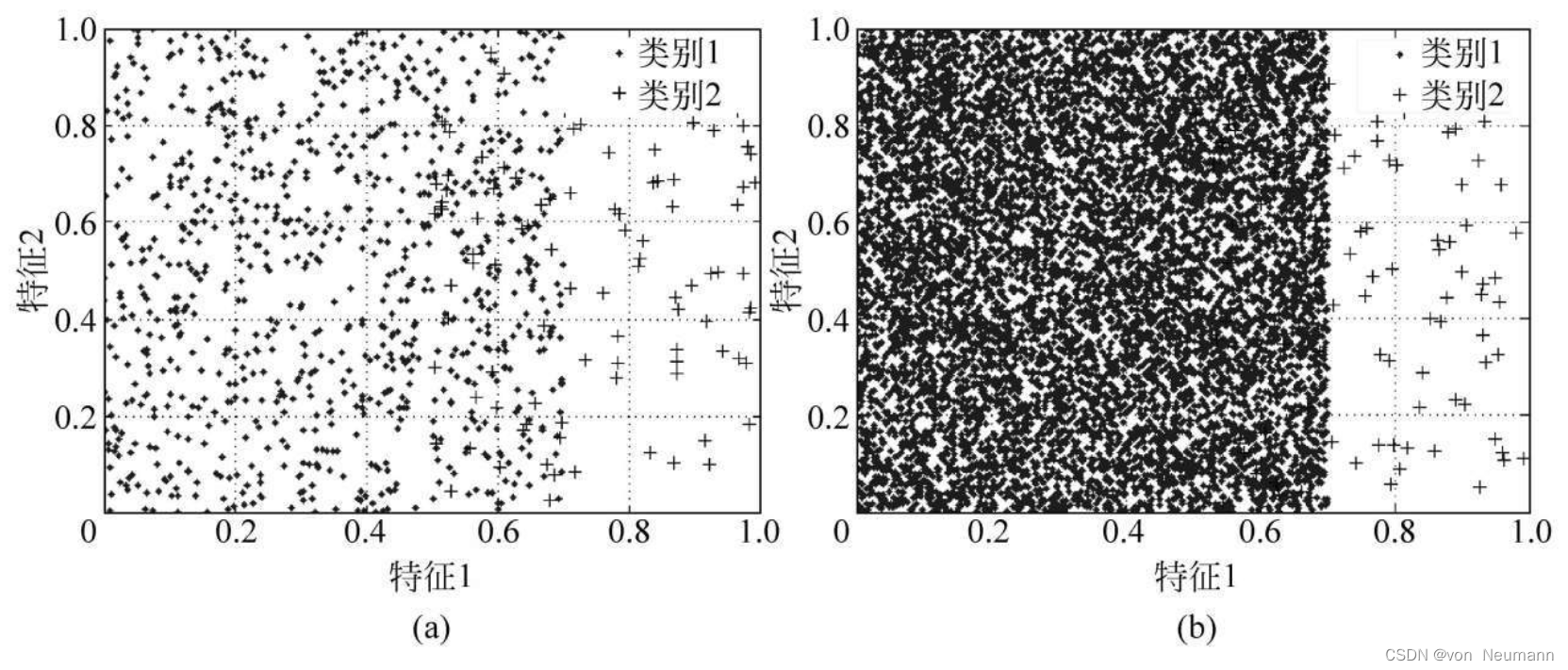
从上图不难看出,不同的类别不平衡比率对分类器的危害程度是不一样的。因此,在进行类别不平衡学习时,要考虑到类别不平衡比率的影响。实际上,在很多实际的类别不平衡学习任务中,其类别不平衡比率均可达到100以上,甚至达到10000。
重叠区域的大小
不同类样本的重叠区域大小也会对分类性能产生较大影响。所谓重叠区域,即是指不同类样本在属性空间的交叠区域。下图刻画了两个具有相同IR值,但重叠区域大小不同的不平衡样本集的样本分布情况。
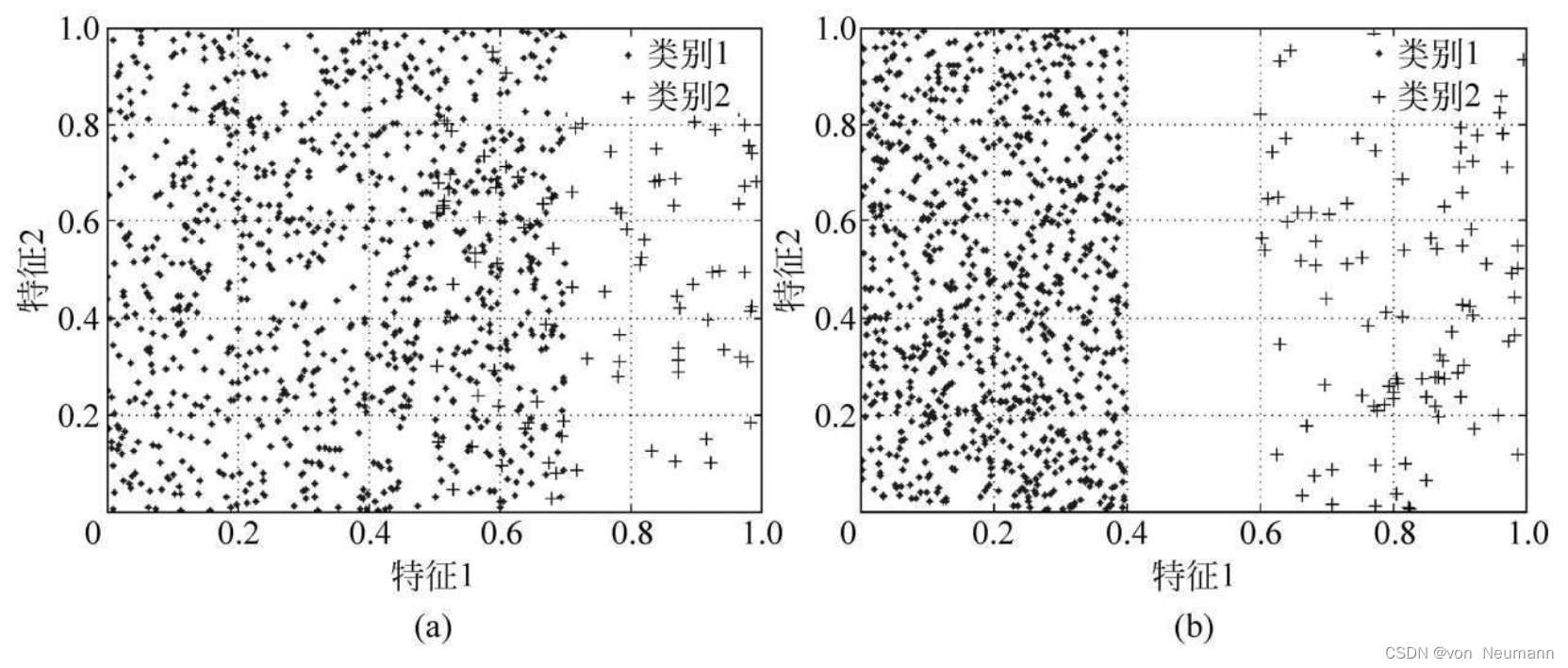
从上图可以看出,两类样本在(a)所刻画的分布中具有较大的重叠区域,而在图(b)中则具有清晰的间隔。那么,显而易见,尽管两种分布均具有相同的IR值,但在图(b)中,更易于找到一个将两类样本完全正确分类的划分超平面。实际上,前人研究已经发现:在不平衡分类任务中,不同类样本的重叠区域越大,则对传统分类器性能的影响也会越大,而若不同类样本在属性空间中可清晰地分开,则对传统分类器性能的影响将是十分有限的。
训练样本的绝对数量
在类别不平衡学习任务中,训练样本的绝对数量,也就是训练集的规模,也会对分类器的性能产生较大影响。这一问题并不难理解,其实即使是在类别平衡的学习任务中,若训练样本规模过小,也会大幅降低分类器的训练精度。因为在小样本数据集上,难以通过统计学方法获取样本的真实分布,即使统计得到一个分布特征,距真实分布的偏差也会较大,从而造成最后学习的结果不准确。不过,在类别不平衡问题中,这一因素的影响又被进一步放大了,可以想象:在训练样本总数本身就不足的情况下,少数类样本的分布必将更加稀疏,从而只能体现出一定的随机性,而完全无法从中观察到其真实分布的情况。下图对两个具有相同IR值,相同重叠区域大小,但训练样本规模不同的样本集的样本分的影响进行了直观说明。
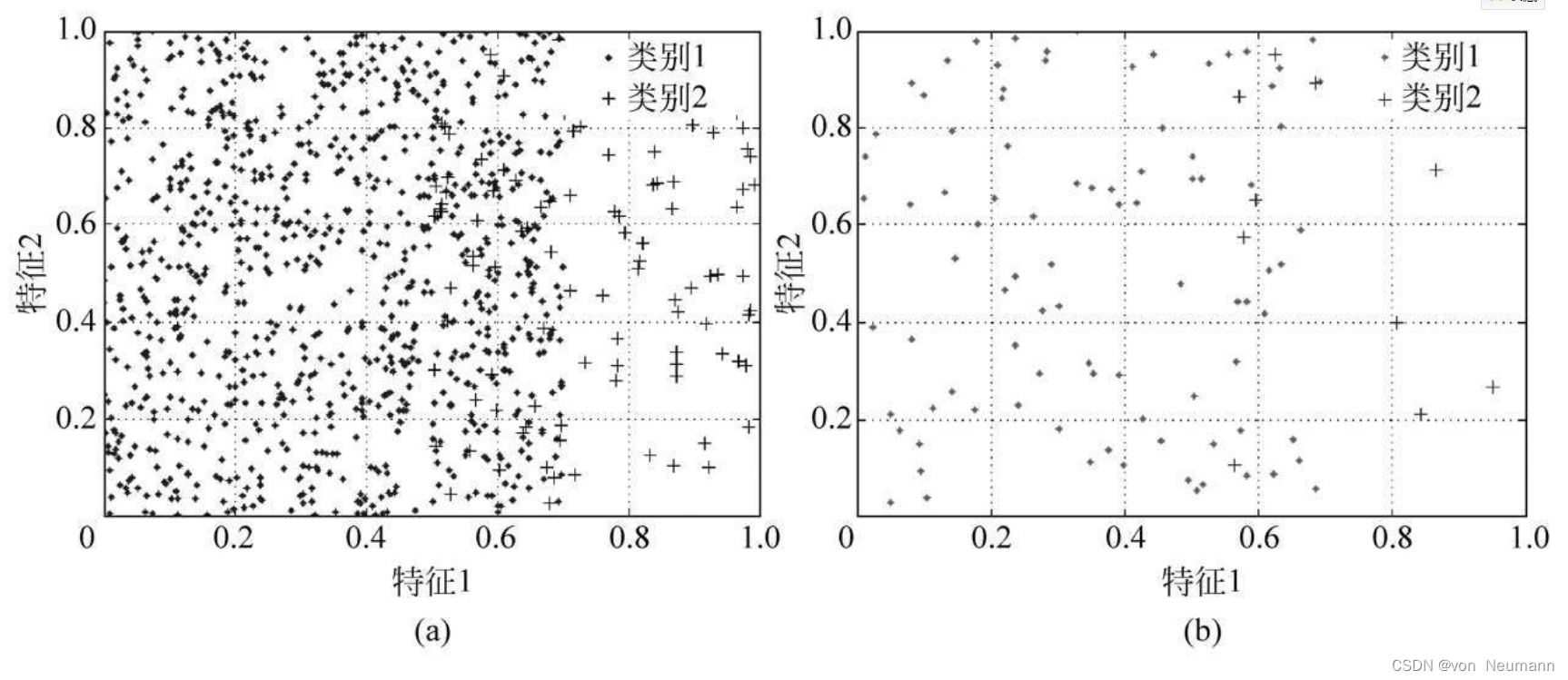
从上图中不难看出,尽管两个子图中的样本来源于完全相同的分布,且IR值与重叠区域的大小也完全相同,但从(a)能够清晰看出样本的分布情况,而在(b)中,样本的分布形状并不清晰,尤其是少数类样本,由于分布过于稀疏,已完全看不出具体的分布情况。由此可知,在类别不平衡学习任务中,训练样本的绝对数量越少,其学习可能越不充分,所训练的分类面的偏差也可能越大。
类内子聚集现象的严重程度
类内子聚集,也被称作类内不平衡或小析取项,通常指代少数类样本中出现两个或者多个概念,且概念有主次之分的情况。下图给出了一个少数类出现类内子聚集的示例。
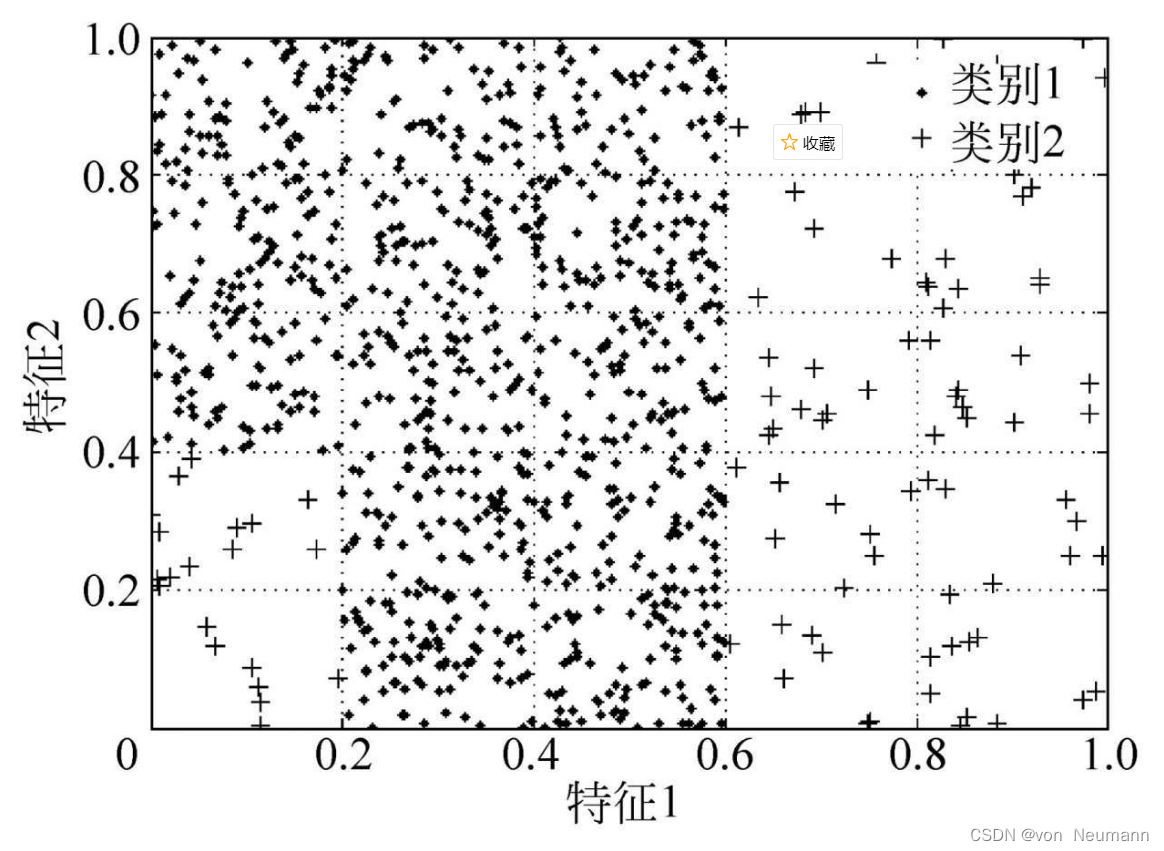
从上图中不难看出,在特征空间中,少数类样本分别被聚集到了两堆,大部分样本服从特征1取值为[ 0.6 , 1 ]、特征2取值为[ 0 , 1 ]的均匀分布,还有少部分样本服从特征1取值为[ 0 , 0.2 ]、特征2取值为[ 0 , 0.4 ] 的均匀分布。显然,上述第一个分布描述了少数类样本的主概念,而第二个分布则描述了次概念。少数类样本本就受到类间不平衡因素的影响,若再存在类内不平衡现象,而需分类器同时学习多个概念,则必然会加剧分类算法的学习难度,而进一步降低少数类的分类精度。
噪声样本的比率
噪声样本的比率通常也是影响类别不平衡学习性能的一个重要因素。所谓噪声样本,主要是指那些不符合同类样本分布的样本,它们在属性空间中通常是以离群点的形式存在。若这些噪声样本恰好出现在了其他类样本的决策区域,则会对其他类样本的决策造成危害。对于不平衡分类问题而言,多数类中的噪声样本比率只要偏高,便可严重损害到少数类的分类精度,而少数类噪声样本的比率即使很高,对多数类所造成的危害也将是十分有限的。上述问题可通过下图加以说明。
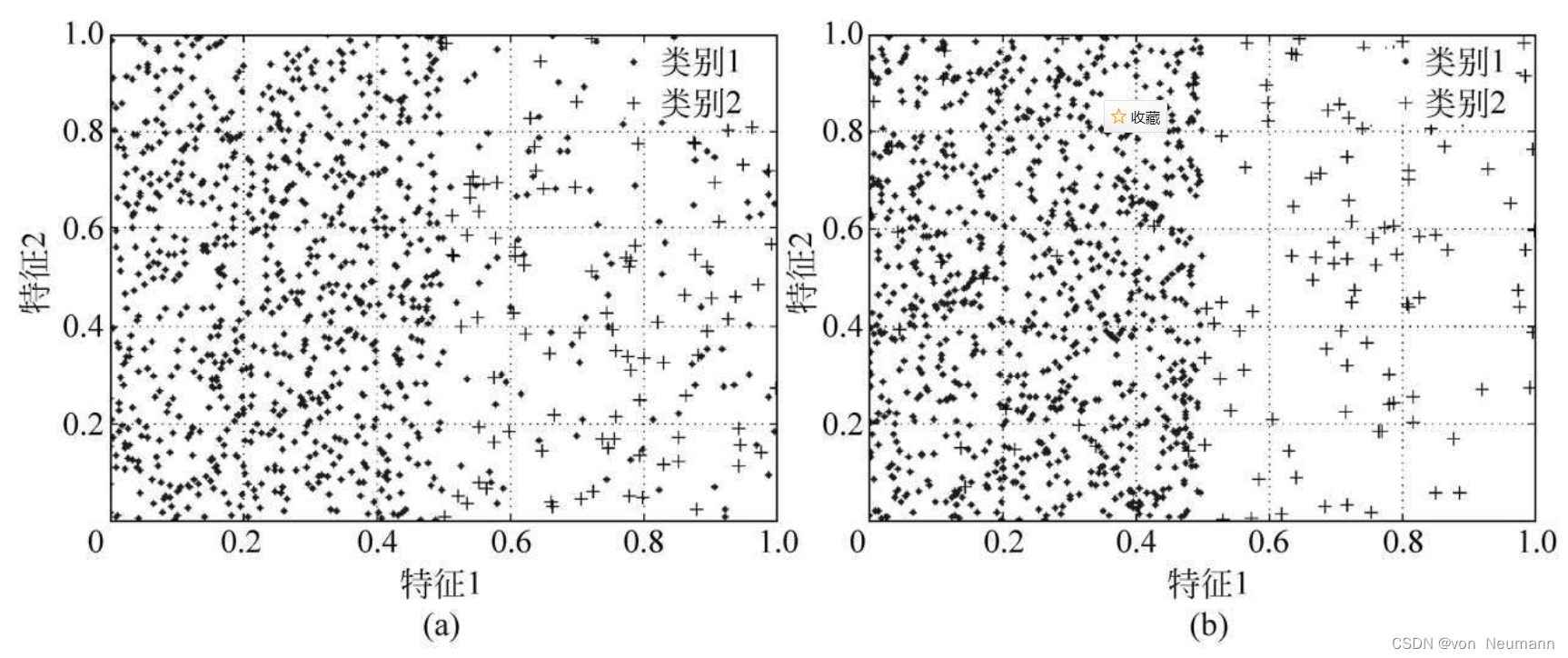
从上图可以看出,对于不平衡分类问题而言,若多数类中含有较高比例的噪声样本,则可能会极大地降低对少数类样本判别正确的可能性,而若少数类噪声样本的比例偏高,则往往会湮没在多数类样本之中,不会对后者的性能产生多少负面影响。故在类别不平衡数据中,噪声样本对于多数类与少数类的危害性往往是不对称的。因此,较高的噪声样本比率往往会加大类别不平衡学习的难度。
其它因素
除上述影响因素外,样本的维度,即样本的属性数的多少也会对类别不平衡学习的性能产生影响。对于高维的不平衡分类问题而言,常规的做法是先对训练集进行降维处理,然后再在低维的样本空间中调用类别不平衡学习方法进行训练。
我们也采用真实分类器检测了三个最重要的因素,即类别不平衡比率I R IRIR、重叠区域大小及训练样本的绝对数量对其分类边界的影响,以使读者能够对该问题有更深入的理解。考虑到在真实世界应用中,同类样本通常近似呈高斯正态分布,故在本例中,我们采用随机高斯函数来生成符合正态分布的虚拟样本集。此外,为了有更好的可视化效果,我们将虚拟样本的维度固定为两维,即每个样本由两个属性组成。这里分别采用μ +和μ − 表示正类与负类样本的均值,而以σ 来表示两类样本分布的标准差。为方便起见,σ的取值被固定为0.3。分类器采用极限学习机,其中,隐层节点数L 及惩罚因子C 均固定为10,激活函数选用Sigmoid函数。另外,在测试过程中,每测试一个参数,均固定另外两个参数的取值,默认参数为μ + = 0.7,μ − = 0.3, I R = 10 ,训练样本绝对数为1100。分类面随各参数取值的变化趋势如下图所示。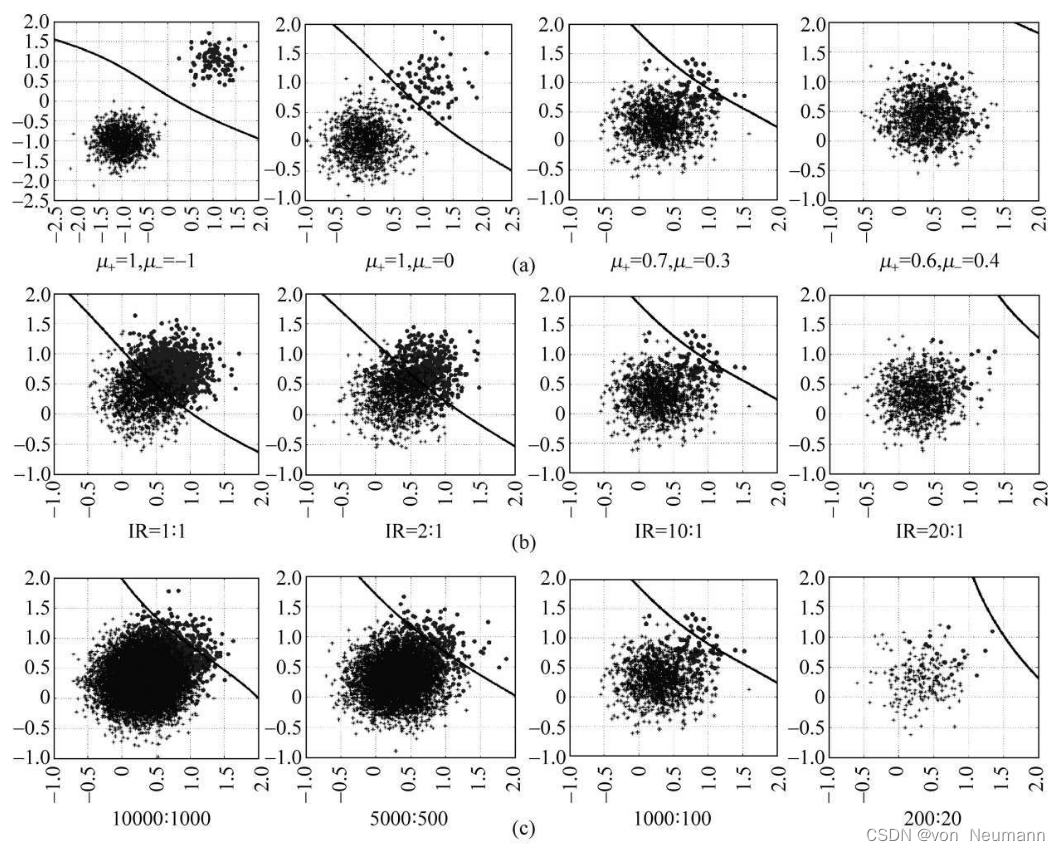
从上图中不难看出,上述各参数均与分类器性能存在着较为密切的联系,当某一参数的取值相对极端时,甚至会造成少数类样本完全被错分,分类模型完全失效。而上述每个实验还仅仅是考查了一个因素的影响,若将各因素综合考量,则将是一个非常复杂的问题。



评论(0)
您还未登录,请登录后发表或查看评论