

在研究语义通信的时候,发现解码端很多都是用GAN或基于GAN来完成的。带着对GAN的好奇,对GAN进行了一个初步学习。这篇文章介绍一下和GAN相关的一些常识吧~
本文围绕以下几个内容展开:
1.什么是GAN?
2.为什么要研究GAN?
3.GAN具体的训练过程?
4.GAN的优缺点
5.GAN的应用
6.现有的开源GAN项目
一、什么是GAN?
GAN全称是Generative adversarial network,生成对抗网络。里面有两个关键词“生成”“对抗”。生成是GAN的作用,对抗是GAN的思想(现在不懂这句话也没关系,后面会介绍的~)。
GAN有两个组成部分:生成网络(Generator)和判别网络(Discriminator)。给这两个网络下个定义。
生成网络(Generator)负责生成模拟数据;
判别网络(Discriminator)负责判断输入的数据是真实的还是生成的。
GAN的精髓都在这两个网络上,前面说GAN的作用是生成,使用者希望能生成有效数据,也就是使用者想要的是良好的生成网络,但未经训练的网络生成效果是很差的,这时它需要一个“老师”来告诉它生成的数据是否有效并告诉它如何改进,这就是判别网络的作用:判别网络会对生成网络结果进行判断,如果发现了问题就把问题告诉生成网络,生成网络优化自己,这样生成网络的性能就会得到提升。
上面一段话大致是GAN的思想,下面细化一下。上面一段话有一个问题:判断网络是怎么判断存在问题的?问题到达指什么?
GAN常用于图像,就拿图像生成举例子。在图像生成任务中生成网络的作用就是生成图像。GAN会把生成图像和真实图像混在一起,一起送入判别网络中,判别网路需要将生成的和真实的进行区分。如果区分的好说明生成器不合格,没办法以假乱真。如果完全区分不出来那就说明生成器完全OK了。把上面的文字转换成图就是下面这样: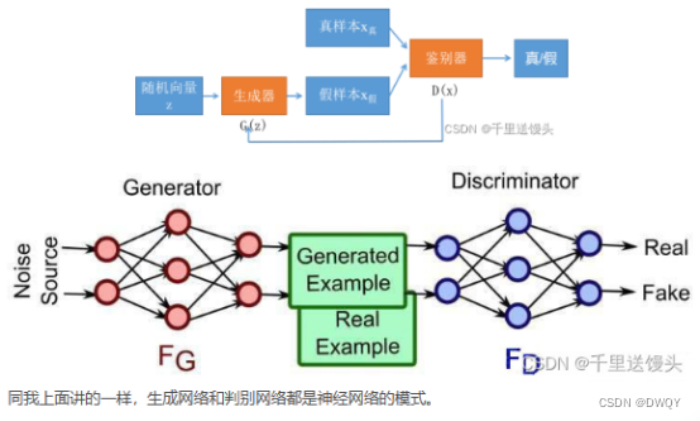
图源:https://blog.csdn.net/m0_61878383/article/details/122462196
介绍了思想再来回头看看名字,“生成”“对抗”。生成是最终的目的——生成有效的数据,对抗是指生成器和判别器之间的关系,它们两个在对抗中不断优化迭代。
GAN首次提出是在2014年(但是我在网上发现有点儿争议~),以论文形式发表:https://arxiv.org/pdf/1406.2661.pdf。它作为一种无监督算法,得到了很好的推广。
二、为什么会研究GAN?
这里我分享一下自己的观点:
1)首先是应用需求导向,AI时代模型训练需要大量的数据,通过人工采集标注已经被证明远远不够,所以自动化的生成数据是时代需要。同时还要保证生成的数据的有效的,所以对有效数据的高效生成变成了AI从业者必须克服的难关。
2)其次是业务发展了,以图像为例。对于图像的使用不仅限于传输了,还包图像修复、图像合成、图像个性化生成等。图像的创造主体从人变成了AI,开始研究用AI做个性化生成。
3)最后可能是对于无监督学习的需要,开始让机器自己监督自己训练,去形成机器间的对抗学习是无监督学习的一种重要方式。
三、GAN的具体训练过程
其实训练过程就是生成器和判别器的博弈过程了。
第一阶段:固定判别器,训练生成器
使用一个还 OK 判别器,让一个「生成器G」不断生成“假数据”,然后给这个「判别器D」去判断。一开始,「生成器G」还很弱,所以很容易被揪出来。但是随着不断的训练,「生成器G」技能不断提升,最终骗过了「判别器D」。
第二阶段:固定「生成器G」,训练「判别器D」
判别器「D」通过不断训练,提高了自己的鉴别能力,最终它可以准确的判断出所有的假图片。到了这个时候,「生成器G」已经无法骗过「判别器D」。
循环一阶段和二阶段
参考:https://zhuanlan.zhihu.com/p/622307792
上面简单介绍下过程,现在回归到真实的网络训练上来。生成器和判别器是两个神经网络,神经网络的训练就是后向传播,也就是必须要找到损失函数,下面介绍下生成器和判别器的损失函数。
如果用图来形容loss变化就是下面这样的: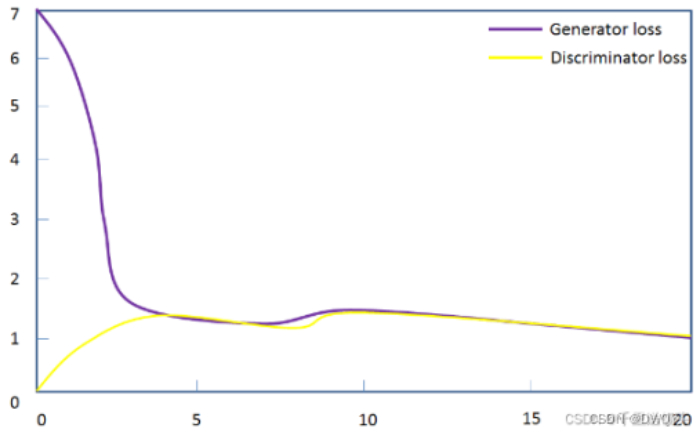
图源:https://blog.csdn.net/m0_61878383/article/details/122462196
四、GAN的优缺点
优点:
1)本质上是一种架构,同时训练生成和判别网络,使两个问题都能变得很好,所以几乎适合所有问题。
2)结果上看能生成更加清晰,更加真实的样本(理论一点儿说就是能更好的建模数据分布)
3)使用无监督学习,不需要依赖大量标注数据。它可以从未标记的数据中学习出数据的分布和特征,可以被广泛的使用在无监督和半监督学习领域
4)无需利用马尔科夫链反复采样,只是反向传播,无需在学习过程中进行推断,没有复杂的变分下界,避开近似计算棘手的概率的难题(我也不懂啥意思~),这点比VAE强。
缺点:
1)难训练,不稳定。训练GAN需要纳什均衡(存在优化方法使判别器和生成器都能达到最大收益),但是在实际训练中很容易D收敛,G发散。会有模式崩溃和模式塌缩的问题
ps:模式崩溃和模式塌缩:生成器可能会陷入生成某些常见模式或样本的困境,导致模式崩溃。而模式塌缩是指生成器输出的样本缺乏多样性,倾向于生成同一或相似的样本。
2)不适合离散形式数据,比如文本(目前GAN多用于生成图像数据)。
3)评价指标困难:对于 GAN,很难找到一个普遍有效的评估指标来衡量生成样本的质量和多样性。通常需要结合人工评价和其他指标进行评估。
4)训练时间较长:由于 GAN 模型的复杂性,训练时间往往较长。特别是对于复杂的数据集和高分辨率的图像,训练所需的计算资源可能很大。
参考:https://zhuanlan.zhihu.com/p/73916148
五、GAN的应用:
GAN的应用在这篇文章里面进行了介绍:https://zhuanlan.zhihu.com/p/73916148,总结一下还是图像的生成,这里写个目录
1.生成图像数据集
2.生成人脸照片
3.生成照片,漫画人物
4.图像到图像的转换
5.文字到图像的转换
6.语义到图像的转换
7.自动生成模特
8.照片到Emojis
9.照片编辑
10.预测不同年龄长相
11.提高照片分辨率
12.照片修复
13.自动生成3D模型
六、现有的开源项目
与GAN相关的成熟论文及源码都在下面这个项目里了:https://github.com/hindupuravinash/the-gan-zoo
还发现一个pytorch版本的:https://github.com/eriklindernoren/PyTorch-GAN



评论(0)
您还未登录,请登录后发表或查看评论