

1.
通常的惯例是把 VSLAM 分为前端和后端。前端为视觉里程计和回环检测,相当于是对图像数据进行关联;后端是对前端输出的结果进行优化,利用滤波或非线性优化理论,得到最优的位姿估计和全局一致性地图。

1 前端:图像数据的关联
1.1 视觉里程计
前端中的视觉里程计, 为通过采集的图像得到相机间的运动估计,视觉里程计问题可由下图描述(双目立体视觉里程计)。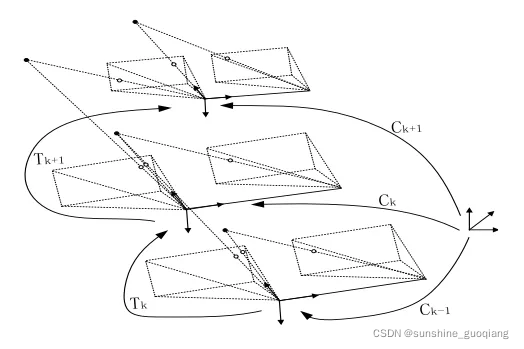
视觉系统在运动过程中,在不同时刻获取了环境的图像,而且相邻时刻的图像必须有足够的重叠区域,则视觉系统的相对旋转和平移运动可被估算出来,然后将每两个相邻时刻之间视觉系统的运动串联起来,可以得到累计的视觉系统相对于参考坐标系的旋转和平移。
如上图所示, 视觉里程计的任务就是已知 k = 0 的初始位置 C0 (这可以根据情况自己定义),求相机的运动轨迹当前的位置 Ck 通过 Tk 和上一时刻的位置Ck-1 来计算,Tk 为 K 和 K+1 时刻的相机相对位置变化,可根据相应时刻采集的图像计算出来,从而恢复相机的运动轨迹。
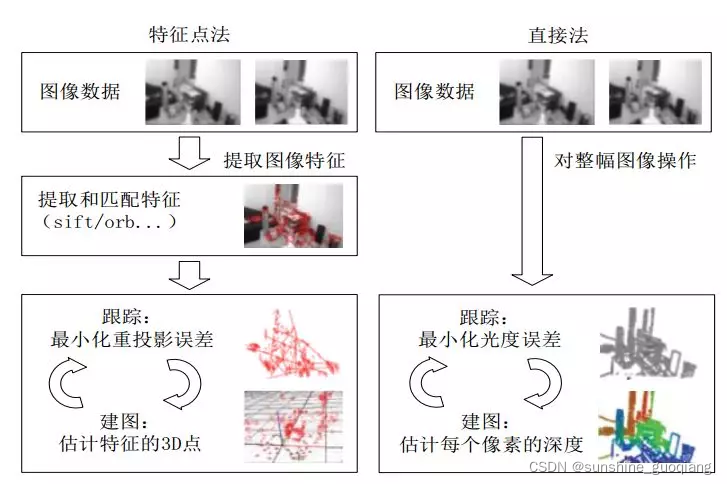
2. 视觉里程计可分为特征点法和直接法。
特征点法主要是根据图像上的特征匹配关系得到相邻帧间的相机运动
估计,它需要对特征进行提取和匹配,然后根据匹配特征构建重投影误差函数,并将其最小化从而得到相机的相对运动;
直接法是假设两帧图像中的匹配像素的灰度值不变,构建光度误差函数, 也将其最小化求解帧间的相机运动。
在这里插入图片描述
1.特征点法
特征点法有几个问题:
a) 关键点的提取和描述子的计算非常耗时,如果保证SLAM 实时运行,需要 30 Frame/s,也就是每帧图像的处理时间约 30 ms,而实时性最好的 ORB也需要近 20 ms/Frame;
b) 特征点法仅仅使用了图像中几百个特征点,占整个图像几十万个像素的很小部分, 丢弃了大量可以利用的图像信息;
c) 特征点的寻找是根据人类自己设计的检测算法,并不完善,有些图像没有明显的纹理,有些图像的纹理比较相似,这种情况下特征点法的 VSLAM 就很难运行;
d) 特征点法只能得到空间的稀疏三维点云。离稠密地图尚有一定的距离,与用于机器人导航的地图差距就更大了。
2 直接法
2.1直接法
直接法根据像素灰度信息估计相机的运动,几乎不用计算关键点和描述子,省去了计算关键点和描述子的时间,可以在特征点缺失但是有图像灰度梯度的场合(当然对于一张白墙, 它也无能为力)。相比于特征点法只能构建稀疏点云地图(构建半稠密或稠密需要采取其他技巧),直接法具备构建半稠密和稠密地图的能力。
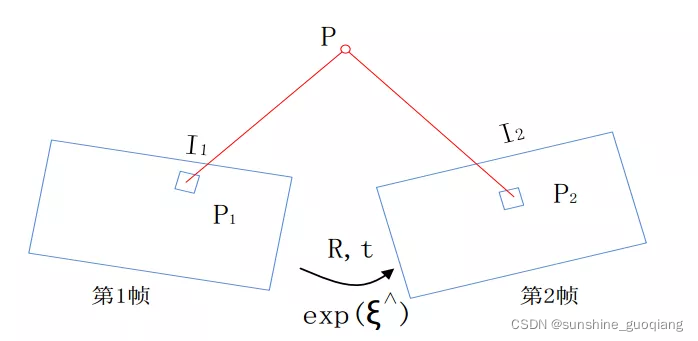
直接法的不变量是对应像素点的灰度值。首先假设两个像素点在第一帧与第二帧之间灰度值保持不变,如下图所示, P1 和 P2 的灰度值是一样的,直接法的思路是根据当前相机的位姿估计来寻找 P2 的位置,如果相机位姿不好, P2 和 P1 的外观会有明显差别。为了减少这个差别, 直接法优化相机位姿,寻找与 P1更相似的 P2。**这就是在灰度不变假设下,直接采用两帧图像中的匹配像素的灰度值,构建光度误差的优化函数,改变相机位姿使之最小化。**根据图像像素 P 的情况,直接法分为稀疏、半稠密和稠密直接法。P 如果是稀疏关键点, 称之为稀疏直接法;P 如果是图像中梯度明显的点, 称之为半稠密法;P 如果是图像中的所有像素, 称之为稠密法。
2.2 光流法
光流法保留特征点,但只计算关键点,不计算描述子。同时,使用光流法来跟踪特征点的运动。
光流描述了像素在图像中的运动,跟踪源图像某个点在其他图像中的运动。遵循灰度不变假设:同一个空间点的像素灰度值,在各个图像中是固定不变的(强假设,不一定成立)。
计算部分像素运动的称为稀疏光流(LK),计算所有像素的称为稠密光流(HS)。LK光流中,假设某一个窗口内的像素具有相同的运动。
可以看成最小化像素误差的非线性优化;每次使用泰勒一阶近似。在离优化点较远时效果不佳,往往需要迭代多次,运动较大时需要使用金字塔;LK光流可以用于跟踪图像中稀疏关键点的运动轨迹,得到匹配点后,后续计算与特征点法VO相同;按方法可以分为正向/反向+平移/组合的方式。
光流法可以加速基于特征点的视觉里程计算法,避免计算和匹配描述子的过程,但要求相机运动较慢(或采集频率较高)。
2.3 直接法
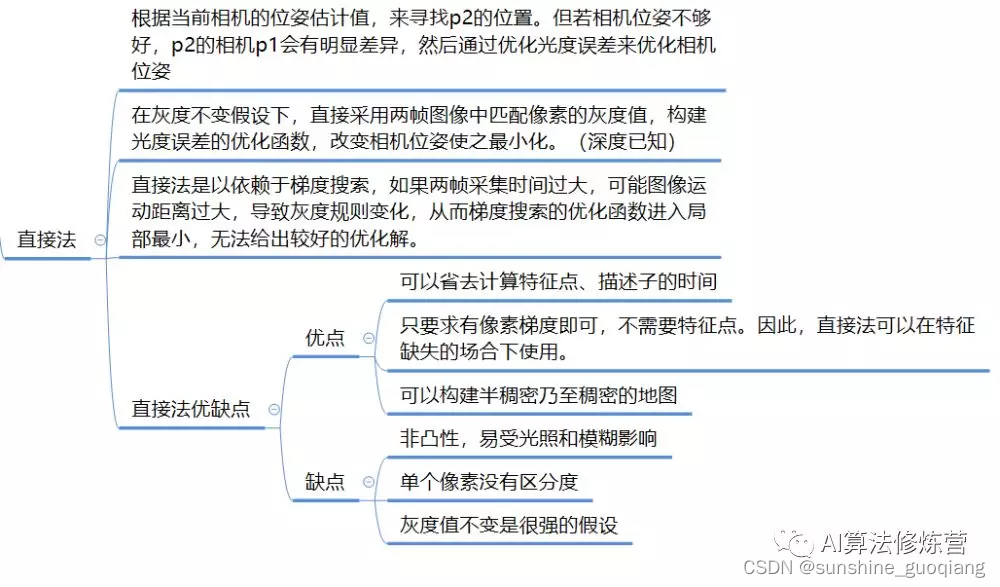
直接法也有自己的局限,首先它需要满足光度不变性假设,这对相机提出了很高的要求, 而且稠密法因为需要计算图像的所有像素(640*480 就是 30 万个像素),很难在现有 CPU 上实时运行。
在前端,特征点法和直接法最大的区别在于,直接法是依赖于梯度搜索,如果两帧采集时间过大,可能图像运动距离过大,导致灰度不规则变化,从而梯度搜索的优化函数进入局部最小,无法给出较好的优化解;而特征点法对运动和光照有一定的鲁棒性, 是根据特征点对距离和光照的鲁棒性来决定的,这也是未来 SLAM 发展的决定因素之一。
3 回环检测
回环检测就是利用传感器有效地检测出以前经过这里,它对于 SLAM 系统意义非常重要,因为无论你的数据多么的精确,模型多么的优秀,系统的累积误差始终存在。如果能正确地检测到回环,对构建全局一致性地图是非常有帮助的;从另一方面,可以利用回环检测对跟踪失败后的情况进行重定位。
在 VLSAM 中回环检测大多数做法是基于外观,比较图像间的相似性。如果用特征点的方式,比如采用 SIFT 特征描述一幅图像,首先每个 SIFT 矢量都是 128 维的,假设每幅图像通常都包含 1 000 个 SIFT 特征,在进行图像相似度计算时,这个计算量非常大,所以通常不会直接采用特征点,而是采用词袋模型。
词袋模型通过提取图像特征,再将特征进行分类构建视觉字典,然后采用视觉字典中的单词集合可以表征任一幅图像。换句话说,通过 BoW 可以把一张图片表示成一个向量。这对判断图像间的关联很有帮助,所以目前比较流行的回环解决方案都是采用的 BoW 及其基础上衍生的算法 IAB-MAP。
回环检测主要由 BoW 模块、 算法模块、 验证模块三个部分组成。
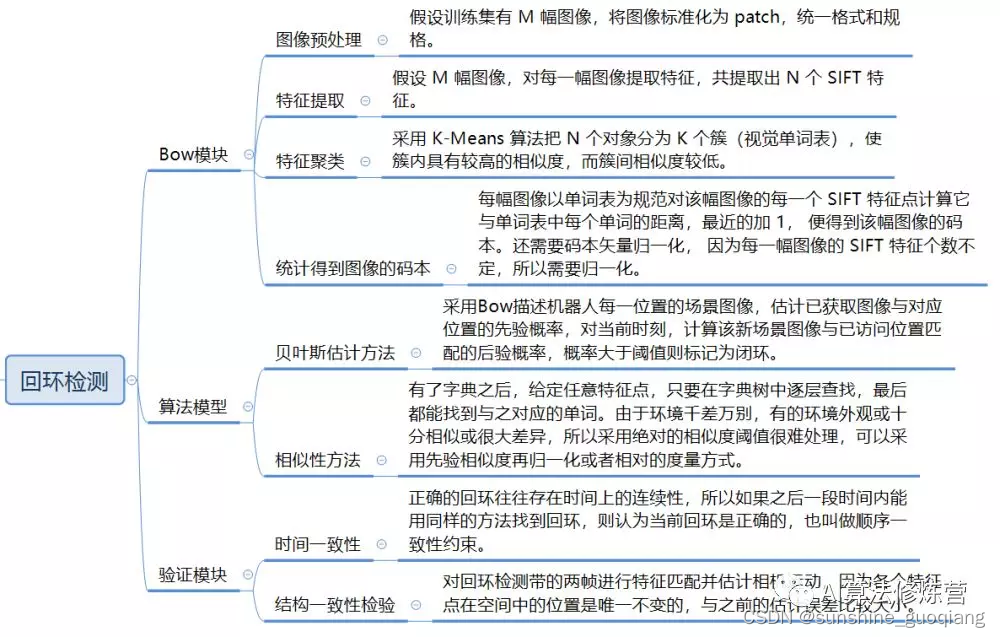 目前还没有专门针对直接法的回环检测方法,主流的回环检测都是利用特征点采取 BOW 方式。换句话说回环检测还是依赖于特征点,从这个角度来看,特征点法有很大的优势:特征点法已经提取了特征,直接用这些特征去做回环检测;**而直接法没有提取特征,如果想做回环检测,必须要另外提取特征。
目前还没有专门针对直接法的回环检测方法,主流的回环检测都是利用特征点采取 BOW 方式。换句话说回环检测还是依赖于特征点,从这个角度来看,特征点法有很大的优势:特征点法已经提取了特征,直接用这些特征去做回环检测;**而直接法没有提取特征,如果想做回环检测,必须要另外提取特征。
**这也是 ORBSLAM 和 LSDSLAM 中的回环检测采取的不同的方式。
ORBSLAM 中的回环检测与整个系统结合得比较紧密,整个系统都是采用的 ORB 特征,首先离线训练得到 ORB 词典,在搜索时因为ORBSLAM 本身就已经计算了特征点和描述,可以直接用特征来搜索,而且 ORBSLAM 采用正向和反向两种辅助指标:反向指标在节点(单词)上储存到达这个节点的图像特征的权重信息和图像编号,因此可用于快速寻找相似图像。正向指标则储存每幅图像上的特征以及其对应的节点在词典树上的某一层父节点的位置,因此可用于快速特征点匹配(只需要匹配该父节点下面的单词)。
LSDSLAM 是采用 OpenFABMAP(OpenCV 上实现的FAB-MAP)来完成回环功能。FAB-MAP 在贝叶斯框架下,采用 Chou-Liu tree估计单词的概率分布,能够完成大规模环境下的闭环检测问题,但是它通过连续的当前帧数据与历史帧数据比较,效率较低,不能满足实时地回环检测。个人感觉 LSDSLAM 中的回环检测是为了完成这个大的系统,额外添加的模块,其实与系统契合度不是很高。
参考:
1.视觉十四讲 高翔
2.https://www.cnblogs.com/gaoxiang12/p/3695962.html
3.https://zhuanlan.zhihu.com/p/64720052



评论(0)
您还未登录,请登录后发表或查看评论