

5. Head
head部分总共有五百多行代码,将分为
- 初始化、构造、前向传播
- priors获取、标签分配、loss计算
- 检测框转换、后处理
这三个部分进行讲解。中间会穿插一下来自其他module的函数或class的介绍,如QFL、DFL、用于从框分布得到框位置的Integral,还有GIoU loss。
5.1. 初始化、层构造和前向传播
5.1.1. 参数初始化
class NanoDetPlusHead(nn.Module):
"""Detection head used in NanoDet-Plus.
Args:
num_classes (int): Number of categories excluding the background
category.不包括背景类,可以认为全部类的输出低于某个阈值视为背景
loss (dict): Loss config.
input_channel (int): Number of channels of the input feature.
刚送入检测头的通道数量,需要和PAN的输出通道数量保持一致
feat_channels (int): Number of channels of the feature. 经过检测头卷积后的通道数
Default: 96.
stacked_convs (int): Number of conv layers in the stacked convs. 堆叠的卷积层数
Default: 2.
kernel_size (int): Size of the convolving kernel. Default: 5.
strides (list[int]): Strides of input multi-level feature maps. 下采样步长
Default: [8, 16, 32].
conv_type (str): Type of the convolution.
Default: "DWConv".
norm_cfg (dict): Dictionary to construct and config norm layer.
Default: dict(type='BN').
AGM中使用GN,但是GN对于CPU型设备不友好,BN可以直接和卷积一同参数化而不需要额外计算
reg_max (int): The maximal value of the discrete set. Default: 7.
参见GFL的论文,用于建模框的任意分布,而不是得到一个Dirac分布
在第四部分的AGM中也介绍过,请查看往期博客
activation (str): Type of activation function. Default: "LeakyReLU".
assigner_cfg (dict): Config dict of the assigner. Default: dict(topk=13).
"""
def __init__(
self,
num_classes,
loss,
input_channel,
feat_channels=96,
stacked_convs=2,
# 选择5x5的卷积大核
kernel_size=5,
# 输入特征相对原图像的下采样率,因为PAN中采用了extra_layer-
# 从配置文件也可以看到这里实际有四层:[8,16,32,64]
strides=[8, 16, 32],
conv_type="DWConv",
norm_cfg=dict(type="BN"),
reg_max=7,
activation="LeakyReLU",
assigner_cfg=dict(topk=13),
**kwargs
):
super(NanoDetPlusHead, self).__init__()
self.num_classes = num_classes
self.in_channels = input_channel
self.feat_channels = feat_channels
self.stacked_convs = stacked_convs
self.kernel_size = kernel_size
self.strides = strides
self.reg_max = reg_max
self.activation = activation
# 必然是使用深度可分离卷积了,DepthwiseConvModule来自MMDetection,请直接看源码
self.ConvModule = ConvModule if conv_type == "Conv" else DepthwiseConvModule
self.loss_cfg = loss
self.norm_cfg = norm_cfg
# 第四部分介绍的动态分配器,稍后计算loss会使用到
self.assigner = DynamicSoftLabelAssigner(**assigner_cfg)
# 根据输出的框分布进行积分,得到最终的位置值
self.distribution_project = Integral(self.reg_max)
# 联合了分类和框的质量估计表示
self.loss_qfl = QualityFocalLoss(
beta=self.loss_cfg.loss_qfl.beta,
loss_weight=self.loss_cfg.loss_qfl.loss_weight,
)
# 初始化参数中reg_max的由来,在对应模块中进行了详细的介绍
self.loss_dfl = DistributionFocalLoss(
loss_weight=self.loss_cfg.loss_dfl.loss_weight
)
# IoU loss的一种改进,IoU loss家族还有CIoU/DIoU等
self.loss_bbox = GIoULoss(loss_weight=self.loss_cfg.loss_bbox.loss_weight)
self._init_layers()
self.init_weights()5.1.2. 构造和权重设置
下面是_buid_not_shared_head、_init_layers()和init_weights():
def _buid_not_shared_head(self):
cls_convs = nn.ModuleList()
# stacked_convs是参数中设定的卷积层数
for i in range(self.stacked_convs):
# 第一层要和PAN的输出对齐通道
chn = self.in_channels if i == 0 else self.feat_channels
cls_convs.append(
self.ConvModule(
chn,
self.feat_channels,
self.kernel_size,
stride=1,
# 加大小为卷积核一般的padding使得输入输出feat有相同尺寸
padding=self.kernel_size // 2,
norm_cfg=self.norm_cfg,
bias=self.norm_cfg is None,
activation=self.activation,
)
)
return cls_convs
def _init_layers(self):
self.cls_convs = nn.ModuleList()
for _ in self.strides:
# 为每个stride的创建一个head,cls和reg共享这些参数
cls_convs = self._buid_not_shared_head()
self.cls_convs.append(cls_convs)
# 同样,为每个头增加gfl卷积
self.gfl_cls = nn.ModuleList(
[
nn.Conv2d(
self.feat_channels,
# 每个位置需要num_classes个通道用于预测类别分数,还有4*(reg_max+1)来回归位置
# 用同一组卷积来获得,输出结果时再split成两份即可
self.num_classes + 4 * (self.reg_max + 1),
1,
padding=0,
)
for _ in self.strides
]
)还有平平无奇的权重初始化:
# 采用norm初始化
def init_weights(self):
for m in self.cls_convs.modules():
if isinstance(m, nn.Conv2d):
normal_init(m, std=0.01)
# init cls head with confidence = 0.01
bias_cls = -4.595
for i in range(len(self.strides)):
normal_init(self.gfl_cls[i], std=0.01, bias=bias_cls)
print("Finish initialize NanoDet-Plus Head.")5.1.3. 前向传播
# head的推理方法
def forward(self, feats):
# 有一个为了兼容onnx的方法
if torch.onnx.is_in_onnx_export():
return self._forward_onnx(feats)
# 输出默认有4份,是一个list
outputs = []
# feats来自fpn,有多组,且组数和self.cls_cons/self.gfl_cls的数量需保持一致
# 默认的参数设置是4组
for feat, cls_convs, gfl_cls in zip(
feats,
self.cls_convs,
self.gfl_cls,
):
# 对每组feat进行前向推理操作
for conv in cls_convs:
feat = conv(feat)
output = gfl_cls(feat)
# 所有head的输出会在展平后拼接成一个tensor,方便后处理
# output是一个四维tensor,第一维长度为1
# 长为W宽为H(其实长宽相等)即feat的大小,高为80 + 4 * (reg_max+1)即cls和reg
# 按照第三个维度展平,就是排成一个长度为W*H的tensor,另一个维度是输出的cls和reg
outputs.append(output.flatten(start_dim=2)) # 变成1x112x(W*H)维了,80+4*8=112
# 把不同head的输出交换一下维度排列顺序,全部拼在一起
# 按照第三维拼接,就是1x112x2125(对于nanodet-m)
outputs = torch.cat(outputs, dim=2).permute(0, 2, 1)
return outputs因为第一个维度长度为1的维度没有消除掉,所以很多读者初看认为这是一个三维的向量,这造成了一些困惑。对于训练或者批量推理的时候,第一个向量的长度就不会为1了!我们直接看看NanoDet-m转成onnx后的可视化:
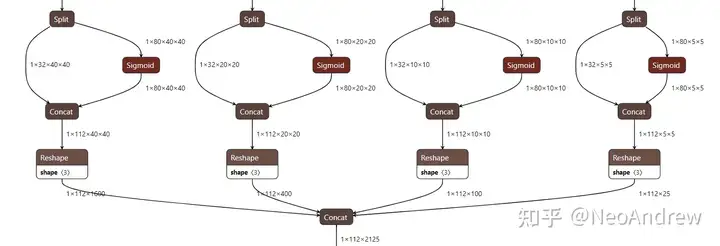
split操作不需要理会,这是在推理的时候拆分分类输出和位置输出使用到的算子。我们会在介绍完训练后介绍部署和推理。



评论(0)
您还未登录,请登录后发表或查看评论