

除了文本分类和结构预测问题,还有很多自然语言处理问题可以归为序列到序列(Sequence-to-Sequence,Seq2seq)问题。机器翻译问题就是典型的代表,其中,输入为源语言句子,输出为目标语言句子。将其推广到序列到序列问题,输入就是一个由若干词组成的序列,输出则是一个新的序列,其中,输入和输出的序列不要求等长,同时也不要求词表一致。使用传统的机器学习技术解决序列到序列问题是比较困难的,而基于深度学习模型,可以直接将输入序列表示为一个向量,然后,通过该向量生成输出序列。其中,对输入序列进行表示的过程又叫作编码,相应的模型则被称为编码器(En-coder);生成输出序列的过程又叫作解码,相应的模型则被称为解码器(Decoder)。因此,序列到序列模型也被称为编码器–解码器(Encoder-Decoder)模型。下图以机器翻译问题为例,展示了一个编码器–解码器模型的示例。本书将在第4章详细介绍序列到序列模型的具体实现。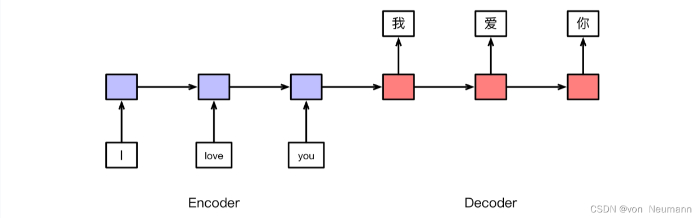
除了机器翻译,还有很多自然语言处理问题可以被建模为序列到序列问题,如对话系统中,用户话语可被视为输入序列,机器的回复则可被视为输出序列,甚至文本分类问题也可以被建模为序列到序列问题。首先,使用编码器对输入文本进行表示,然后,解码器只输出一个“词”,即文本所属的类别。结构预测问题也类似,首先,也需要使用编码器对输入文本进行表示,然后,在处理序列标注问题时,使用解码器生成输出标签序列(需要保证输出序列与输入序列长度相同);在处理序列分割问题时,直接输出结果序列;在处理图结构生成问题时,需要将图表示的结果进行序列化,即通过一定的遍历顺序,将图中的节点和边转换为一个序列,然后再执行解码操作。不过,由于输入和输出有较强的对应关系,而序列到序列模型很难保证这种对应关系,所以结构预测问题较少直接使用序列到序列模型加以解决。但是无论如何,由于序列到序列模型具备强大的建模能力,其已成为自然语言处理的大一统框架,越来越多的问题都可以尝试使用该模型加以解决。也就是说,可以将复杂的自然语言处理问题转化为编码、解码两个子问题,然后就可以分别使用独立的模型建模了。
参考文献:
[1] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[2] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[3] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[4] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[5] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.



评论(0)
您还未登录,请登录后发表或查看评论