

分类目录:《深入理解深度学习》总目录
相关文章:
· Word Embedding(一):word2vec
· Word Embedding(二):连续词袋模型(CBOW, The Continuous Bag-of-Words Model)
· Word Embedding(三):Skip-Gram模型
· Word Embedding(四):Skip-Gram模型的数学原理
· Word Embedding(五):基于哈夫曼树(Huffman Tree)的Hierarchical Softmax优化
· Word Embedding(六):负采样(Negative Sampling)优化
Skip-Gram模型与连续词袋模型(CBOW)类似,同样包含三层:输入层、映射层和输出层。具体架构如下图所示:
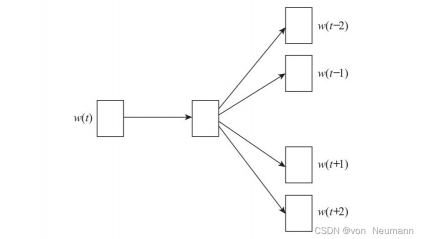
Skip-Gram模型中的w(t)为输入词,在已知词w(t)的前提下预测词w(t)的上下文w(t−n)、⋯、w(t−2)、w(t−1)、w(t+1)、(t+2)、⋯ w(t+n),条件概率写为p(context(w)∣w)。目标
函数为:
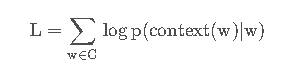
我们通过一个简单的例子来说明Skip-Gram的基本思想。假设有一句话:
The quick brown fox jumped over the lazy dog.
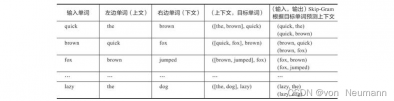
接下来,我们根据Skip-Gram模型的基本思想,按这条语句生成一个由序列(输入,输出)构成的数据集。首先,我们对一些单词以及它们的上下文环境建立一个数据集。可以以任何合理的方式定义“上下文”,这里是把目标单词的左右单词视作一个上下文,使用大小为1的窗口定义,也就是说,仅选输入词前后各1个词和输入词进行组合,就得到一个由(上下文,目标单词)组成的数据集,具体如下图所示:



评论(0)
您还未登录,请登录后发表或查看评论