

分类目录:《深入理解深度学习》总目录
相关文章:
· Word Embedding(一):word2vec
· Word Embedding(二):连续词袋模型(CBOW, The Continuous Bag-of-Words Model)
· Word Embedding(三):Skip-Gram模型
· Word Embedding(四):Skip-Gram模型的数学原理
· Word Embedding(五):基于哈夫曼树(Huffman Tree)的Hierarchical Softmax优化
· Word Embedding(六):负采样(Negative Sampling)优化
训练一个神经网络意味着要输入训练样本并不断调整神经元的权重,从而不断提高对目标预测的准确性。神经网络每训练一个样本,该样本的权重就会调整一次。正如《Word Embedding(五):基于哈夫曼树(Huffman Tree)的Hierarchical Softmax优化》所讨论的, V 的大小决定了神经网络的权重矩阵的具体规模,所有这些权重需要通过数以亿计的训练样本来进行调整,这是非常消耗计算资源的,并且在实际训练过程中,速度会非常慢。
负采样(Negative Sampling)解决了这个问题,它可以提高训练速度并改善所得到词向量的质量。不同于原本需要更新每个训练样本的所有权重的方法,负采样只需要每次更新一个训练样本的一小部分权重,从而在很大程度上降低了梯度下降过程中的计算量。在Hierarchical Softmax优化方法中,负例是二叉树的其他路径,而对于负采样(Negative Sampling)优化,负例是随机挑选出来的。
对于每个训练样本,中心词是 w ,它周围上下文共有 2 c个词,记为 context ( w )。由于这个中心词 w 的确和 context ( w ) 相关存在,因此它是一个真实的正例。通过负采样(Negative Sampling),我们得到 NEG 个和 w 不同的中心词 w i ( i = 1 , 2 , ⋯ , NEG ) ,这样 context ( w ) 和 w i 就组成了 NEG个并不真实存在的负例。利用这一个正例和 NEG 个负例,我们进行二元Logistic回归,得到负采样对应每个词 w i对应的模型参数 θ i 和每个词的词向量。
从《Word Embedding(五):基于哈夫曼树(Huffman Tree)的Hierarchical Softmax优化》可以看出,负采样(Negative Sampling)优化由于没有采用霍夫曼树,每次只是通过采样 NEG \text{NEG} NEG个不同的中心词做负例,就可以训练模型,因此整个过程要比Hierarchical Softmax简单。
负采样(Negative Sampling)方法
设词汇表的大小为 V ,那么可以将一段长度为1的线段分成 V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。每个词 w 的线段长度由下式决定:

在采样前,我们将这段长度为1的线段划分成 M 等份,这里 M ≫ V ,这样可以保证每个词对应的线段都会划分成对应的小块。而 M 份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从 M个位置中采样出 NEG 个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。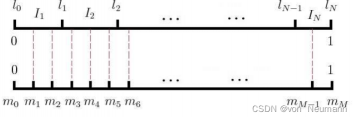



评论(0)
您还未登录,请登录后发表或查看评论