

分类目录:《深入理解深度学习》总目录
相关文章:
· Word Embedding(一):word2vec
· Word Embedding(二):连续词袋模型(CBOW, The Continuous Bag-of-Words Model)
· Word Embedding(三):Skip-Gram模型
· Word Embedding(四):Skip-Gram模型的数学原理
· Word Embedding(五):基于哈夫曼树(Huffman Tree)的Hierarchical Softmax优化
· Word Embedding(六):负采样(Negative Sampling)优化
· 机器学习中的数学——激活函数(七):Softmax函数
· 算法设计与分析——哈夫曼树/赫夫曼树(Huffman Tree)和哈夫曼编码/赫夫曼编码(Huffman Coding)
在文章《Skip-Gram模型的数学原理》中,我们需要更新两个矩阵W和 ’ ,但这两个矩阵涉及的词汇量较大(即V较大),所以更新时需要消耗大量资源,尤其是更新矩阵W ’ 。正如前面一直提到的,无论是CBOW模型还是Skip-Gram模型,每个训练样本(或者Mini Batch)从梯度更新时都需要对W ’ 的所有V×N个元素进行更新,这个计算成本是巨大的。此外,在计算Softmax函数时,计算量也很大。为此,人们开始思考如何优化这些计算。考虑到计算量大的部分都是在隐藏层到输出层阶段,尤其是W ’ 的更新。因此word2vec使用了两种优化策略:Hierarchical Softmax和Negative Sampling。二者的出发点一致,即在每个训练样本中,不再完全计算或者更新W ′ 矩阵,换句话说,两种策略中均不再显式使用W’ 这个矩阵。同时,考虑到上述训练和推理的复杂度高是因Softmax分母上的求和过程导致,因此上述的两种优化策略是对Softmax的优化,而不仅仅是对word2vec的优化通过优化,word2vec的训练速度大大提升,词向量的质量也几乎没有下降,这也是word2vec在NLP领域如此流行的原因。Hierarchical SoftMax并不是由word2vec首先提出的,而是由Yoshua Bengio在2005年最早提出来的专门用于加速计算神经语言模型中的Softmax的一种方式。下面主要介绍如何在word2vec中使用 Hierarchical Softmax优化。 Hierarchical Softmax的实质是基于哈夫曼树(一种二叉树)将计算量大的部分变为一种二分类问题。如下图所示,原来的模型在隐藏层之后通过W ′ W^′W ′ 连接输出层,经过Hierarchical Softmax优化后则去掉了W ′ ,由隐藏层h直接与下面的二叉树的根节点相连:
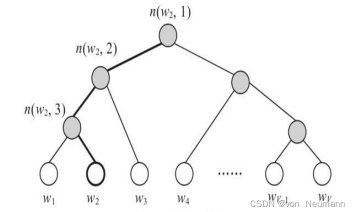
其中,白色的叶子节点表示词汇表中的所有词(这里有V个),灰色节点表示非叶子节点,每一个叶子节点其实就是一个单词,且都对应唯一的一条从根节点出发的路径。图中用n(w,j)表示从根节点到叶子节点w的路径上的第j个非叶子节点,并且每个非叶子节点都对应一个向量 ,其维度与h相同。

连续词袋模型(CBOW)的Hierarchical Softmax优化
连续词袋模型(CBOW)是已知上下文,估算当前词语的语言模型。其学习目标是最大化对数似然函数:

其中,w表示语料库C中任意一个词。对于连续词袋模型,输入层是上下文的词语的词向量,投影层对其求和,所谓求和,就是简单的向量加法,输出层则输出最可能的w。由于语料库中词汇量是固定的∣C∣个,所以上述过程其实可以看做一个多分类问题。即给定特征后从∣C∣个分类中挑一个最可能的词语输出。
对于神经网络模型多分类,最朴素的做法是Softmax回归:
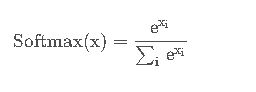
而Softmax回归需要对语料库中每个词语都计算一遍输出概率并进行归一化,在超大词汇量的语料上效率是十分低下的。根据上图,非叶子节点相当于一个神经元(Logistic回归),二分类决策输出1或0,分别代表向下左转或向下右转,而每个叶子节点代表语料库中的一个词语,于是每个词语都可以被0和1唯一地编码,并且其编码序列对应一个事件序列,于是我们可以计算条件概率p(w∣context(w))。
根据上述定义,我们可以写出基于Hierarchical Softmax优化的连续词袋模型(CBOW)的条件概率:
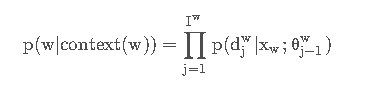
其中,每一项都是一个Logistic回归:
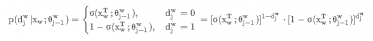
则我们的目标函数可以写为:
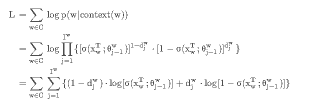
我们可以把为词汇w求和过程中的第j项记为:
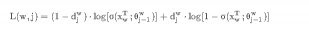
由于Sigmoid函数的导数:
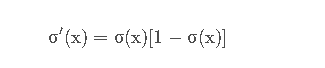
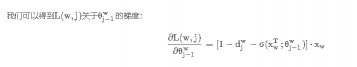
所以θj −1w 在梯度下降法中的更新表达式为:
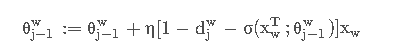
其中η为学习率。同理x w的更新表达式为:
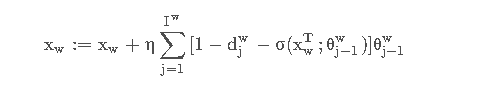
不过x w 是上下文的词向量的和,不是上下文单个词的词向量,word2vec采取的是直接将x w的更新量应用到每个单词的词向量上去:
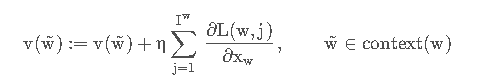
Skip-Gram的Hierarchical Softmax优化
Skip-Gram与 连续词袋模型(CBOW)类似,这两个模型的区别在于:输入层不再是多个词向量,而是一个词向量,输出层同理。所以我们引入一个新的记号u用来表示w上下文中的一个词语,这概率可以写为:
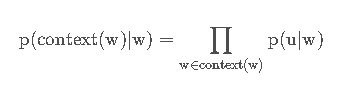
这里面的每个u都是无序的,或者说说相互独立的。则在Hierarchical Softmax思想下,每个u都可以编码为一条路径:
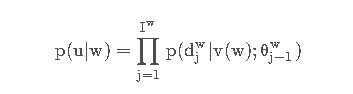
与连续词袋模型(CBOW)类似:

所以目标函数为,其中C(x)表示context(x):
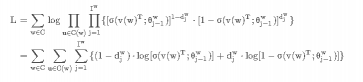
与连续词袋模型(CBOW)类似,我们可以将每一项简记为:

虽然上式对比连续词袋模型(CBOW)多了一个u,但在给定训练实例时,u也是固定的。所以上式其实依然只有两个变量x w 和θ j−1w,对其求偏导数:
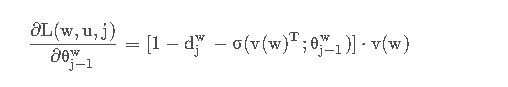
所以我们可以得到Skip-Gram的更新表达式:
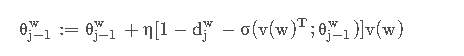
同理x w的更新表达式为:
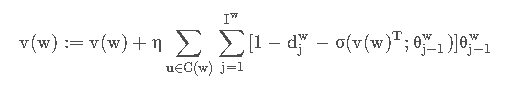



评论(0)
您还未登录,请登录后发表或查看评论