

分类目录:《深入理解机器学习》总目录
相关文章:
机器学习中的数学——信息熵(Information Entropy)
基于决策树的模型(一)分类树和回归树
基于树的模型(二):集成学习之Bagging和Random Forest
基于树的模型(三):集成学习之GBDT和XGBoost
基于树的模型(四):随机森林的延伸——深度森林(gcForest)
基于树的模型(五):从零开始用Python实现ID3决策树
基于树的模型(六):Python实现CART决策树并利用Tkinter构建GUI对决策树进行调优
基于树的模型(七):RF/XGBoost等算法实践与决策树Scala实践等(材料准备中)
决策树(Decision Tree)是一种基本的分类与回归方法,当决策树用于分类时称为分类树,用于回归时称为回归树。本文主要讨论决策树中的分类树与回归树的一些基本理论,后续文章会继续讨论决策树的Boosting和Bagging相关方法。
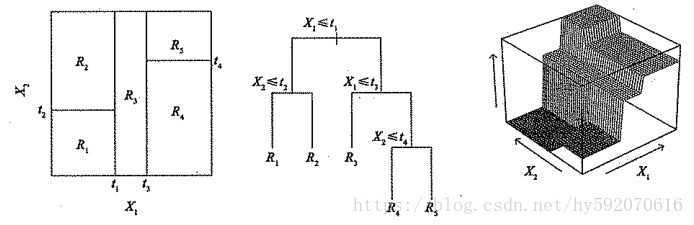
决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点,其中内部结点表示一个特征或属性,叶结点表示一个类。一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点则对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果被划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定测试序列。在下图中,圆和方框分别表示内部结点和叶结点。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。
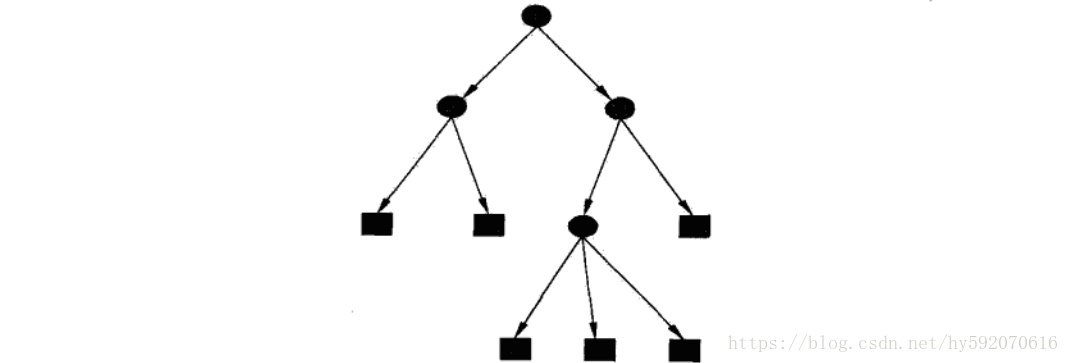
分类树
分类树是一种描述对实例进行分类的树形结构。在使用分类树进行分类时,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点。这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分到叶结点的类中。
假设给定训练数据集:
D={(x1,y1),(x2,y2),...,(xN,yN)}

决策树学习本质上是从训练数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能有多个,也可能一个也没有。我们需要的是一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。从另一个角度看,决策树学习是由训练数据集估计条件概率模型。基于特征空间划分的类的条件概率模型有无穷多个,我们选择的条件概率模型应该不仅对训练数据有很好的拟合,而且对未知数据有很好的预测。
决策树学习用损失函数表示这一目标,其损失函数通常是正则化的极大似然函数,决策树学习的策略是以损失函数为目标函数的最小化。当损失函数确定以后,学习问题就变为在损失函数意义下选择最优决策树的问题。因为从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题。这样得到的决策树是次最优的。


决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。开始,构建根结点,将所有训练数据都放在根结点。选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点中去,如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的结点。如此递归地进行下去,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止。最后每个子集都被分到叶结点上,即都有了明确的类。这就生成了一棵决策树。
从上述过程中就可以看出,决策树的生成是一个递归过程。在决策树基本算法中,有三种情形会导致递归返回
- 当前结点包含的样本全属于同一类别,无需划分
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
- 当前结点包含的样本集合为空,不能划分
在第二种情形下,我们把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别。在第三种情形下,同样把当前结点标记为叶结点,但将其类别设定为其父结点所含样本最多的类别。这两种情形的处理实质不同:第二种情况是在利用当前结点的后验分布,而第三种情况则是把父结点的样本分布作为当前结点的先验分布。
以上方法生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力,即可能发生过拟合现象。我们需要对已生成的树自下而上进行剪枝,将树变得更简单,从而使它具有更好的泛化能力。具体地,就是去掉过于细分的叶结点,使其回退到父结点,甚至更高的结点,然后将父结点或更高的结点改为新的叶结点。如果特征数量很多,也可以在决策树学习开始的时候,对特征进行选择,只留下对训练数据有足够分类能力的特征。
可以看出,决策树学习算法包含特征选择、决策树的生成与决策树的剪枝过程。由于决策树表示一个条件概率分布,所以深浅不同的决策树对应着不同复杂度的概率模型。决策树的生成对应于模型的局部选择,决策树的剪枝对应于模型的全局选择。决策树的生成只考虑局部最优,相对地,决策树的剪枝则考虑全局最优。
决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。分类树具有良好的可读性与分类速度快的优点。分类树在学习时,利用训练数据,根据损失函数最小化的原则建立分类树模型,在预测时,对新的数据,利用分类树模型进行分类。决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
决策树与if-then规则
可以将决策树看成一个if-then规则的集合:由决策树的根结点到叶结点的每一条路径构建一条规则,路径上内部结点的特征对应着规则的条件,而叶结点的类对应着规则的结论。决策树的路径或其对应的if-then规则集合具有一个重要的性质——互斥并且完备。这就是说,每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖。这里所谓覆盖是指实例的特征与路径上的特征一致或实例满足规则的条件。
决策树与条件概率分布
决策树还表示给定特征条件下类的条件概率分布。这一条件概率分布定义在特征空间的一个划分上。将特征空间划分为互不相交的单元或区域,并在每个单元定义一个类的概率分布就构成了一个条件概率分布。决策树的一条路径对应于划分中的一个单元。决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。
假设X为表示特征的随机变量,Y 为表示类的随机变量,那么这个条件概率分布可以表示为P ( Y ∣ X )。X取值于给定划分下单元的集合,Y 取值于类的集合。各叶结点(单元)上的条件概率往往偏向某一个类,即属于某一类的概率较大。决策树分类时将该结点的实例强行分到条件概率大的那一类去。
决策树的优缺点
计算复杂度不高
对中间缺失值不敏感
解释性强,在解释性方面甚至比线性回归更强
与传统的回归和分类方法相比,决策树更接近人的决策模式
可以用图形表示,非专业人士也可以轻松理解
可以直接处理定性的预测变量而不需创建哑变量
决策树的预测准确性一般比回归和分类方法弱,但可以通过用集成学习方法组合大量决策树,显著提升树的预测效果
特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。比如,我们希望构建一棵决策树来根据不同人的各种属性来预测每个人性别,那么对于属性“头发的长度”可能就要比属性“头发的颜色”所能包含的信息更多。因为一般来说,男生的头发要比女生的头发短,所以我们希望“头发的长度”这个属性处于决策树的上部。随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
信息增益
为了便于说明信息增益,先给出熵与条件熵的定义。在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设X 是一个取有限个值的离散随机变量,其概率分布为:
P(X=xi)=pi,i=1,2,⋯,n
则随机变量X 的熵定义为:

由此可见,熵越大,随机变量的不确定性就越大。从熵的定义可验证
0≤H(p)≤logn
当随机变量只取两个值,例如1,0时,即X 的分布为:
P(X=1)=p,P(X=0)=1−p,0≤p≤1
其熵为:
H(p)=−plog2p−(1−p)log2(1−p)
这时,熵H ( p ) 随概率p 变化的曲线如下图所示(单位为比特):
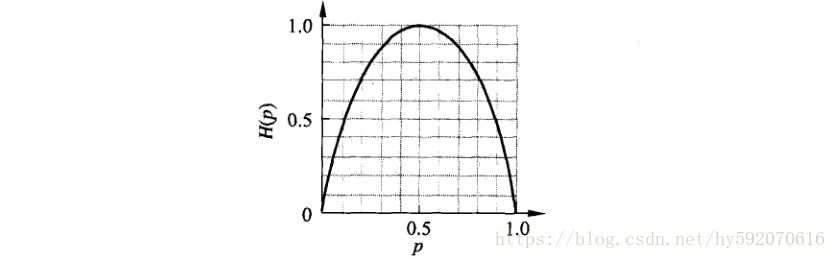
当p = 0 或p = 1 时H ( p ) = 0 ,随机变量完全没有不确定,当p = 0.5时,H ( p ) = 1 ,熵取值最大,随机变量不确定性最大。
设有随机变量( X , Y ),其联合概率分布为:

其中,p i = P ( X = x i ) , i = 1 , 2 , ⋯ , n 。
当熵和条件熵中的概率由数据估计(如极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。此时,如果有0概率,令0 log 0 = 0 。
信息增益(information gain)表示得知特征X 的信息而使得类Y 的信息的不确定性减少的程度。特征a ∗对训练数据集D 的信息增益g ( D , a ∗ ) ,定义为集合D 的经验熵H ( D ) 与特征a ∗ 给定条件下D的经验条件熵H ( D ∣ a ∗ ) 之差,即:
g(D,a∗)=H(D)−H(D∣a∗)
一般地,熵H ( Y ) 与条件熵H ( Y ∣ X )之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
决策树学习应用信息增益准则选择特征。给定训练数据集D 和特征a ∗ ,经验熵H ( D ) 表示对数据集D 进行分类的不确定性。而经验条件熵H ( D ∣ a ∗ ) 表示在特征a ∗ 给定的条件下对数据集D 进行分类的不确定性。那么它们的差,即信息增益,就表示由于特征a ∗而使得对数据集D 的分类的不确定性减少的程度。显然,对于数据集D 而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益,信息增益大的特征具有更强的分类能力。
根据信息增益准则的特征选择方法:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。


一般而言,信息增益越大,则意味着使用特征a ∗ 来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择,即在上述决策树分类算法第10行使用a ∗ = arg max a ∈ A g ( D , a ) 选择最优划分属性。著名的ID3决策树学习算法就是以信息增益为准则来选择划分属性。
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点。之后,再对子结点递归地调用以上方法,构建决策树,直到所有特征的信息增益均很小或没有特征可以选择为止,最终得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。

信息增益率
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。在训练数据集的经验熵大的时候,信息增益值会偏大。反之,信息增益值会偏小。使用信息增益率(information gain ratio)可以对这一问题进行校正。这是特征选择的另一准则。特征a ∗ 对训练数据集D DD的信息增益率g g ( D , a ∗ )
定义为其信息增益g ( D , a ∗ ) 与训练数据集D的经验熵H ( D )之比:
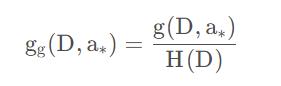
如前文所说,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法不直接使用信息增益来选择划分属性,而是使用信息增益率来选择最优划分属性。

需注意的是,信息增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式的方法选择最优划分属性:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的.。
连续值处理
实际的任务中常会遇到连续属性,对于全部为连续属性的样本来说,我们一般使用回归决策树来处理。C4.5算法则采用了二分法对连续属性进行处理。由于连续属性的可取值数目不再有限,因此,不能直接根据连续属性的可取值来对结点进行划分。此时,连续属性离散化技术可派上用场。最简单的策略是采用二分法对连续属性进行处理。

其中Gain(D,a,t)是样本集D基于划分点t 二分后的信息增益。于是,我们就可选择使Gain(D,a,t)最大化的划分点。
缺失值处理
现实任务中常会遇到不完整样本,即样本的某些属性值缺失。且在属性数目较多的情况下,有时会有大量样本出现缺失值。如果简单地放弃不完整样本,仅使用无缺失值的样本来进行学习,显然是对数据信息极大的浪费。显然,有必要考虑利用有缺失属性值的训练样例来进行学习。
划分属性的选择

对样本进行划分
根据上面的定义,若样本x 在划分属性a上的取值已知,则将x 划入与其取值对应的子结点,且样本权值在子结点中保持为ω x。若样本x 在划分属性a 上的取值未知,则将x同时划入所有子结点,且样本权值在与属性值a^v对应的子结点中调整为r ~ v × ω x 。直观地看,这就是让同一个样本以不同的概率划入到不同的子结点中去。
基尼指数
数据集D 的纯度还可用基尼值来度量:

在二类分类问题中,基尼指数Gini(D)、熵H(p)的一半,和分类误差率的关系:
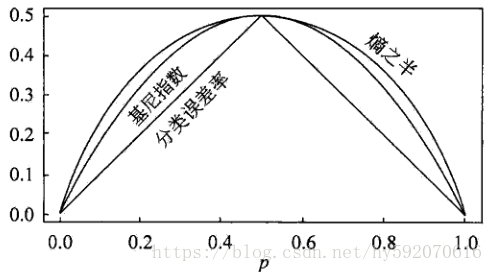
其中,横坐标表示概率p ,纵坐标表示损失。可以看出基尼指数和熵的一半的曲线很接近,都可以近似地代表分类误差率。
分类树的剪枝
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因为对训练样本学习得“太好”了,以致于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。决策树剪枝的基本策略有预剪枝和后剪枝。
预剪枝
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。停止决策树生长常用方法:
1.定义一个高度,当决策树达到该高度时就停止决策树的生长
2.达到某个节点的实例具有相同的特征向量,即使这些实例不属于同一类,也可以停止决策树的生长。这个方法对于处理数据的数据冲突问题比较有效。
3.定义一个阈值,当达到某个节点的实例个数小于阈值时就可以停止决策树的生长
4.定义一个阈值,通过计算每次扩张对系统性能的增益,并比较增益值与该阈值大小来决定是否停止决策树的生长。
后剪枝
后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。相比于预剪枝,后剪枝更常用,因为在预剪枝中精确地估计何时停止树增长很困难。
错误率降低剪枝(REP,Reduced-Error Pruning)
错误率降低剪枝方法是一种比较简单的后剪枝的方法。在该方法中,可用的数据被分成两个样例集合:首先是训练集,它被用来形成学习到的决策树,另一个是与训练集分离的验证集,它被用来评估这个决策树在后续数据上的精度,确切地说是用来评估修剪这个决策树的影响。学习器可能会被训练集中的随机错误和巧合规律所误导,但验证集合不大可能表现出同样的随机波动。所以验证集可以用来对过度拟合训练集中的虚假特征提供防护检验。
错误率降低剪枝方法考将树上的每个节点作为修剪的候选对象,再决定是对该节点进行剪枝:
- 删除以此结点为根的子树
- 使其成为叶子结点
- 当修剪后的树对于验证集合的性能不比修剪前的树的性能差时,则确认删除该结点,否则恢复该节点
因为训练集合的过拟合,使得验证集合数据能够对其进行修正,反复进行上面的操作,从底向上的处理结点,删除那些能够提高验证集合的精度的结点,直到进一步修剪会降低验证集合的精度为止。
错误率降低剪枝方法是最简单的后剪枝方法之一,不过由于使用独立的测试集,原始决策树相比,修改后的决策树可能偏向于过度修剪。这是因为一些不会再次在测试集中出现的很稀少的训练集实例所对应的分枝在剪枝过程中往往会被剪枝。尽管错误率降低剪枝方法有这个缺点,不过错误率降低剪枝方法仍然作为一种基准来评价其它剪枝算法的性能。它对于两阶段决策树学习方法的优点和缺点提供了一个很好的学习思路。由于验证集合没有参与决策树的构建,所以用错误率降低剪枝方法剪枝后的决策树对于测试样例的偏差要好很多,能够解决一定程度的过拟合问题。
悲观错误剪枝(PEP,Pesimistic-Error Pruning)
悲观错误剪枝方法是根据剪枝前后的错误率来判定子树的修剪。它不需要像错误率降低修剪方法那样,需要使用部分样本作为测试数据,而是完全使用训练数据来生成决策树,并进行剪枝,即决策树生成和剪枝都使用训练集。
该方法引入了统计学中连续修正的概念弥补错误率降低剪枝方法中的缺陷,在评价子树的训练错误公式中添加了一个常数,即假定每个叶子结点都自动对实例的某个部分进行错误的分类。
把一颗具有多个叶子节点的子树的分类用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是我们把子树的误判计算加上一个经验性的惩罚因子来做是否剪枝的考量指标。对于一个叶子节点,它覆盖了N 个样本,其中有E 个错误,那

代价复杂度剪枝(CCP,Cost-Complexity Pruning)
代价复杂度剪枝算法为子树T t 定义了代价和复杂度,以及一个可由用户设置的衡量代价与复杂度之间关系的参数α 。其中,代价指在剪枝过程中因子树T t 被叶节点替代而增加的错分样本,复杂度表示剪枝后子树T t 减少的叶结点数,α 则表示剪枝后树的复杂度降低程度与代价间的关系,定义为:

2.从子树序列中,根据真实的误差估计选择最佳决策树

回归树
建立回归树的过程大致可以分为两步:
1.将预测变量空间(X 1 , X 2 , X 3 , ⋯ , X p )的可能取值构成的集合分割成J 个互不重叠的区域{ R 1 , R 2 , R 3 , ⋯ , R J }
2.对落入区域R j 的每个观测值作同样的预测,预测值等于R j 上训练集的各个样本取值的算术平均数。

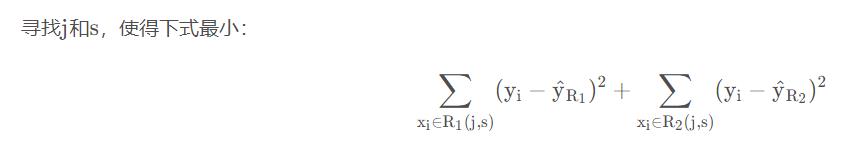
重复上述步骤,寻找继续分割数据集的最优预测变量和最优分割点,使随之产生的区域中的RSS达到最小。此时被分割的不再是整个预测变量空间,而是之前确定的两个区域之一。如此一来就能得到3个区域。接着进一步分割3个区域之一以最小化RSS。这一过程不断持续,直到符合某个停止准则,如我们在分类决策树中讨论到的前剪枝中的停止准则。
区域{ R 1 , R 2 , R 3 , ⋯ , R J }产生后,就可以确定某一给定的测试数据所属的区域,并用这一区域训练集的各个样本取值的算术平均数作为与测试进行预测。
回归树的剪枝
上述方法生成的回归树会在训练集中取得良好的预测效果,却很有可能造成数据的过拟合,导致在测试集上效果不佳。原因在于这种方法产生的树可能过于复杂。一棵分裂点更少、规模更小(区域{ R 1 , R 2 , R 3 , ⋯ , R J }的个数更少的树会有更小的方差和更好的可解释性(以增加微小偏差为代价)。
针对上述问题,一种可能的解决办法是:仅当分裂使残差平方和RSS的减小量超过某阈值时,才分裂树结点。这种策略能生成较小的树,但可能产生过于短视的问题,一些起初看来不值得的分裂却可能之后产生非常好的分裂。也就是说在下一步中,RSS会大幅减小。
因此,更好的策略是生成一棵很大的树T 0 ,然后通过后剪枝得到子树。直观上看,剪枝的目的是选出使测试集预测误差最小的子树。子树的测试误差可以通过交叉验证或验证集来估计。但由于可能的子树数量极其庞大,对每一棵子树都用交叉验证来估计误差太过复杂。因此需要从所有可能的子树中选出一小部分再进行考虑。在回归树中,我们一般使用代价复杂度剪枝(CCP,Cost-Complexity Pruning),也称最弱联系剪枝(Weakest Link Pruning)。这种方法不是考虑每一棵可能的子树,而是考虑以非负调整参数α 标记的一系列子树。每一个α的取值对应一棵子树T ∈ T 0 ,当α 一定时,其对应的子树使下式最小:
 中训练集的平均值。调整系数α在子树的复杂性和与训练数据的契合度之间控制权衡。当α = 0 时,子树T 等于原树T 0 ,因为此时上式只衡量了训练误差。而当α增大时,终端结点数多的树将为它的复杂付出代价,所以使上式取到最小值的子树会变得更小。
中训练集的平均值。调整系数α在子树的复杂性和与训练数据的契合度之间控制权衡。当α = 0 时,子树T 等于原树T 0 ,因为此时上式只衡量了训练误差。而当α增大时,终端结点数多的树将为它的复杂付出代价,所以使上式取到最小值的子树会变得更小。
当α 从0开始逐渐增加时,树枝以一种嵌套的、可预测的模式被修剪,因此获得与α对应的所有子树序列是很容易的。可以用交又验证或验证集确定α,然后在整个数据集中找到与之对应的子树:

决策树的基础即是上文所述的分类决策树与回归决策树,其预测准确性一般比回归和分类方法弱,但可以通过用集成学习方法组合大量决策树,显著提升树的预测效果,这些方法我将会在接下来的文章中继续阐述,欢迎关注学习讨论!



评论(0)
您还未登录,请登录后发表或查看评论