

0. 简介
对于自动驾驶来说语义分割是自动驾驶中理解周围环境的一项常见任务。可行驶区域分割和车道检测对于道路上安全且高效的导航尤为重要。为了满足自动驾驶汽车中可行驶区域和车道分割的高效轻量级,《TwinLiteNet: An Efficient and Lightweight Model for Driveable Area and Lane Segmentation in Self-Driving Cars》提出了一种用于可行驶区域和车道线分割的轻量级模型。TwinLiteNet设计代价低廉,但是可以获得精确且高效的分割结果。TwinLiteNet可以在计算能力有效的嵌入式设备上实时地运行,尤其是因为它在Jetson Xavier NX上实现了60FPS帧率,这使其成为自动驾驶汽车的理想解决方案。具体的开源方案已经在Github上实现了。
1. 主要贡献
本文的主要贡献如下:
-
本文提出了一种用于可行驶区域分割和车道检测的计算高效框架;
-
本文提出的架构基于ESPNet,它是一种可扩展的卷积分割网络,其结合了深度可分离卷积以及双重注意力网络,但是没有使用单个解码模块,而是针对每个任务利用两个解码模块,类似于YOLOP、YOLOPv2;
-
本文实验结果表明,TwinLiteNet在各种图像分割任务上通过较少的参数实现了不错的性能。
2. 主要方法
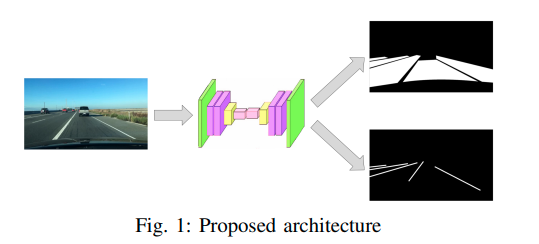
说实话,这个工作目前还是没有脱离Unet框架的,可以作为Unet框架进行了解。首先,我们建议设计一个模型,其输入和输出如图1所示;我们的TwinLiteNet由一个输入和两个输出组成,以便模型学习两个不同任务的表示。然后,我们推荐使用双重注意力模块来提高模型性能。此外,本节还提出了用于训练模型的一些损失函数。我们还介绍了我们使用的训练和推理机制。下面的部分详细展示了我们提出的方法。
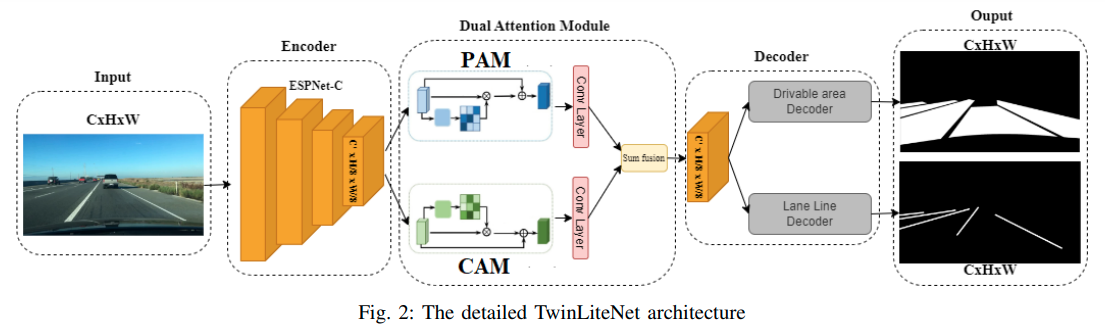
2.1 模型架构
本文提出了一种成本效益高的任务分割架构,称为TwinLiteNet,如图2所示。我们的方法利用ESPNNet-C作为信息编码块,实现了高效的特征图生成。我们将双重注意力模块融入网络中,以捕捉空间和通道维度上的全局依赖关系。这些模块增强了网络感知上下文信息的能力。然后,将得到的特征图通过两个专用于执行两个特定任务的编码器块进行处理:可驾驶区域分割和车道检测。通过采用这种架构,我们旨在以较低的成本实现这些任务的准确和高效的分割结果。
首先,与使用骨干网络和高计算成本方法的方法不同,我们利用了低计算成本但高准确性的ESPNet的强大功能。我们使用ESPNet-C作为编码器从输入图像中提取特征。在ESPNNet-C中,除了通过特征图在ESP模块之间共享信息外,还在架构的不同块之间在不同维度上整合输入信息。从ESPNet-C中获取特征图A ∈ \mathbb{R}^{C ′ × \frac{H}{8} × \frac{W}{8}}后,我们通过双重注意力模块将提取的特征传递。双重注意力模块由位置注意力模块(PAM)和通道注意力模块(CAM)组成。PAM模块旨在将更广泛的上下文信息融入到局部特征中,增强其表示能力。另一方面,CAM模块利用通道映射之间的相互依赖性,突出特征图之间的相互依赖关系,并加强特定语义的表示。我们通过卷积层转换两个注意力模块的输出,并使用逐元素求和操作实现特征融合B ∈ \mathbb{R}^{C ′ × \frac{H}{8} × \frac{W}{8}}。我们的论文针对可驾驶区域和车道分割任务提出了多输出设计。我们不是使用单个输出来进行所有需要分割的对象类型,而是使用两个解码器块来处理特征图,并获得每个任务的最终结果。我们推荐这种多输出设计的原因如下:
- 独立性能优化:通过两个专用的输出模块,我们可以独立地优化每个类别的分割性能。这种方法使我们能够在不受其他类别影响的情况下,分别对可行驶区域和车道进行微调和改进分割结果。
- 提高准确性:使用两个输出模块来分别处理不同层次也可以提高分割准确性。通过独立关注每个层次,我们的模型可以更好地学习和调整与可行驶区域和车道特定特征相关的内容,从而为每个类别提供更准确的分割结果。
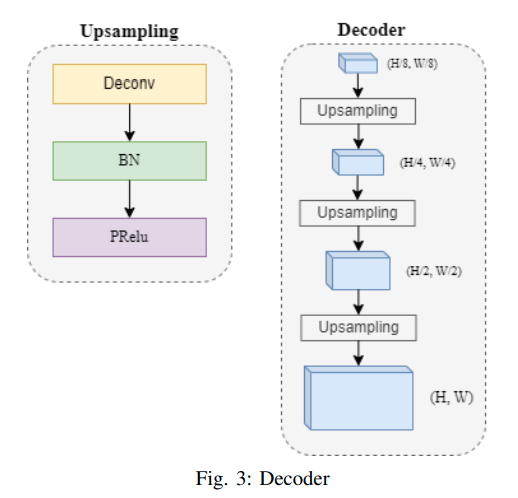
通过采用具有两个独立输出的可行驶区域和车道分割任务的多输出设计,我们实现了独立的性能优化和增强的分割准确性。我们的解码器模块设计简单但高效,依赖于ConvTranspose层、批归一化和pRelu [23]激活函数,如图3所示。在解码后,TwinLiteNet返回两个用于可行驶区域和车道检测任务的分割图像。我们的TwinLiteNet在可行驶区域分割和车道检测任务中以高准确性优化分割性能。
通过利用ESPNet-C和特征分析模块Dual Attention Network,我们增强了模型的特征提取能力。此外,简单的解码器模块有助于降低计算成本并提高模型的效率。
2.2 Loss损失函数
们为所提出的分割模型使用了两个损失函数:Focal Loss [24] 和 Tversky Loss [25]。Focal Loss旨在减少像素之间的分类错误,同时解决易于预测样本的影响,并严厉惩罚难以预测的样本,如方程1所示。另一方面,Tversky Loss借鉴了Dice Loss [26],并解决了分割任务中的类别不平衡问题。然而,与Dice Loss不同的是,Tversky Loss引入了α和β参数来调整计算过程中假阳性和假阴性的重要性,如Tversky方程2所描述。
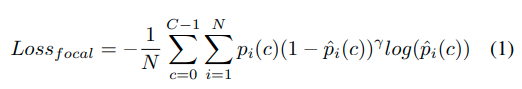
在这里:
- $$N$$:输入图像中的像素数量
- $$C$$:类别数量,在这种情况下,一个类别是可行驶区域或车道,其余类别是背景。
- $$\hat{p}i(c)$$:用于确定像素i属于类别c的预测值
- $$pi(c)$$:像素i属于类别c的真实值
- $$γ$$:平衡校正因子
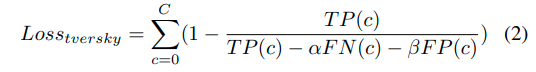
-
TP:真正例(True Positives)
-
FN:假负例(False Negatives)
-
FP:假正例(False Positives)
-
C:类别数量,在这种情况下,一个类别是可行驶区域或车道,其余类别是背景。
-
α,β:控制假正例和假负例的惩罚程度。
每个头部的聚合损失函数采用以下形式:
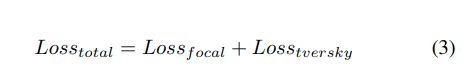
2.3 训练机制和推理机制
我们使用尺寸为640x360的输入图像对TwinLiteNet进行训练。我们使用了Adam [27]优化器,并在训练过程中逐渐降低学习率。TwinLiteNet在100个epochs中进行了训练,批量大小为32。在推理过程中,我们应用了重新参数化技术,将卷积和批量归一化[28]层合并为单个层,从而加快了推理速度。这个合并过程只在推理过程中发生,而在模型训练过程中,它们仍然作为独立的层进行操作:卷积和批量归一化。



评论(0)
您还未登录,请登录后发表或查看评论