

0. 简介
对于3d bounding box而言,近几年随着自动驾驶的火热,其标注工具也日渐多了起来,本篇文章不讲具体的算法,这里主要聚焦于这些开源的3d bounding box标注工具,以及他们是怎么使用的。这里借鉴了我想静静,博主的博客作为基础,然后再结合自己的使用与了解完成扩充。
1. 3d-bat
在本文中,我们专注于在新型 3D 边界框注释工具箱 (3D BAT) 的帮助下获取 2D 和 3D 标签,以及道路上物体的轨迹 ID。 我们基于 Web 的开源 3D BAT 包含多项智能功能,以提高可用性和效率。例如,此注释工具箱支持使用插值对轨迹进行半自动标记,这对于跟踪、运动规划和运动预测等下游任务至关重要。
此外,通过将注释从 3D 空间投影到图像域中,可以自动获得所有相机图像的注释。除了原始图像和点云馈送外,还提供由顶视图(鸟瞰图)、侧视图和前视图组成的主视图,可用于从不同角度观察感兴趣的对象。 我们的方法与其他公开可用的注释工具的比较表明,使用我们的工具箱可以更快、更有效地获得 3D 注释。支持点云渲染,2D 俯视图,立方体标注,下面这篇文章讲了具体的使用与安装方法
2. point-cloud-annotation-tool
为了标注点云数据,根据使用要求和方便程度最终选择了这款可以在Windows下编译安装的point-cloud-annotation-tool,基于QT和vtk和PCL进行编译。其主要可以支持以下几种标注格式
- 支持点云数据加载、保存与可视化
- 支持点云数据选择
- 支持3D BOX框生成
- 支持KITTI-bin格式数据
下面这篇文章讲了在Windows下具体的使用与安装方法,而对于Ubuntu的用户来说,可以参考这个文章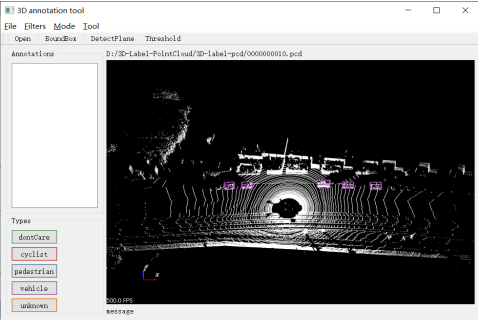
3. SUSTechPoints
在得到图像数据,激光雷达数据,标定数据之后,需要进行3D目标框标注。本文采用的标注工具采用的是:SUSTechPOINTS。这个工具是2020年IEEE收录的,是一个比较好的开源项目,可以使得激光雷达和图像数据联合标注。其主要可以完成点云渲染, 3视图, 2D 相机图, 交互较流畅,半自动框注释(需要额外的包)自动对象跟踪 ID 生成,具体的安装使用可以看这篇文章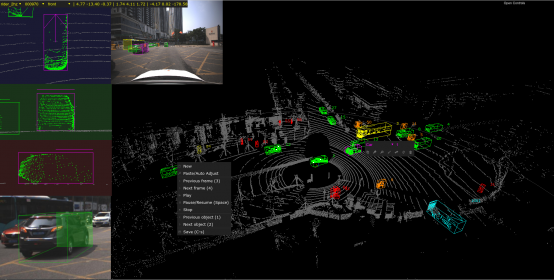
4. annotate
感知算法的评估需要标记的地面真实数据。受监督的机器学习算法需要标记的训练数据。“annotate”是在ROS/RViz中创建三维标记边界框的工具。它的标记数据既可以作为机器学习算法的训练数据,也可以作为评估的基础数据。具体的使用可以参考这篇文章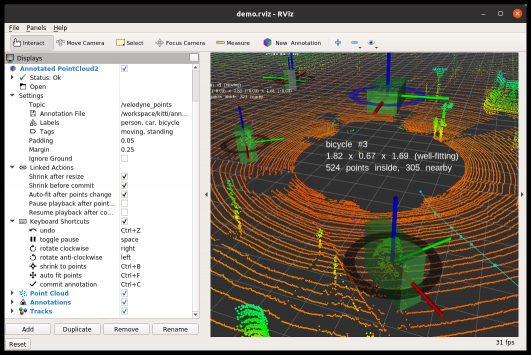
5. Label家族
5.1 Labelhub
Labelhub作为一个支持网页端标注的标注软件。其支持所有类型的图片标注,支持2D图像(.jpg和.png文件)的3视图映射。还支持LIDAR生成的3D点云(.pcd文件)中目标的标注,支持3D BOX框生成。最好用的还是其可以通过预置训练模型可进行目标自动识别,贴边等。免费体验地址如下http://labelhub.cn/。如果需要具体使用这个软件,可以参考这个博客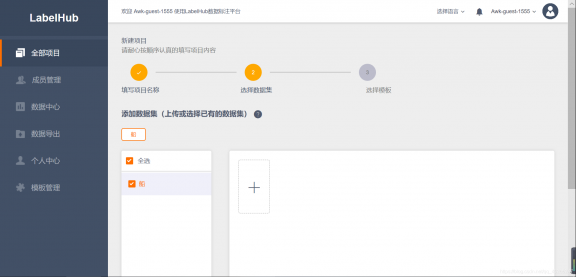
5.2 labelImg-kitti(bev)
使用该软件可以直接提供bev视角的标注,得到kitti格式,这个就是在传统的IabelImg上进行了扩充,增加了bev视角下深度点云的标注,具体使用可以参考这篇文章

6. 在线标注annotate.photo
https://annotate.photo/#tools-section这个网站也是一个比较小众的标注网站,它们提供了一套完整的工具,用于在2D和3D图像上标注对象。最后会生成标注的json文件,这类标注文件都默认可以通过下述的代码完成json到kitti的转化
import json
import os
import math
import numpy as np
import random
import shutil
random.seed(0)
np.random.seed(0)
label_path = './data/20210409/label/'
calibFile = './data/20210409/calib/front.json'
sourceImagePath = './data/20210409/image/front/'
sourceVelodynePath = './data/20210409/bin/'
kittiLabelPath = '/home/.../catkin_ws/src/pcdetection/src/data/kitti/training/label_2/'
kittiCalibPath = '/home/.../catkin_ws/src/pcdetection/src/data/kitti/training/calib/'
imageSetsPath = '/home/.../catkin_ws/src/pcdetection/src/data/kitti/ImageSets/'
trainingPath = '/home/.../catkin_ws/src/pcdetection/src/data/kitti/training/'
testingPath = '/home/.../catkin_ws/src/pcdetection/src/data/kitti/testing/'
errorFlag = 0
def calibLabelFileGen(Path, fname, istrain=True):
if istrain:
if os.path.exists(Path + "label_2/" + fname.replace('json', 'txt')):
os.remove(Path + "label_2/" + fname.replace('json', 'txt'))
with open(label_path + fname)as fp:
# json content
jsonContent = json.load(fp)
if (len(jsonContent) == 0):
print("the json annotation file is empty, please check file: ", fname)
return 1
else:
for i in range(len(jsonContent)):
content = jsonContent[i]
psr = content["psr"]
position = psr["position"]
scale = psr["scale"]
rotation = psr["rotation"]
#lidar -> camera
pointXYZ = np.array([position["x"], position["y"], position["z"], 1]).T
camPosition = np.matmul(Tr_velo_to_cam, pointXYZ) #Tr_velo_to_cam @ pointXYZ camera coordinate position
#print(invExtrinsic @ pointXYZ)
# kitti content
kittiDict = {}
kittiDict["objectType"] = content["obj_type"]
kittiDict["truncated"] = "1.0"
kittiDict["occluded"] = "0"
kittiDict["alpha"] = "0.0"
kittiDict["bbox"] = [0.00, 0.00, 50.00, 50.00] # should be higher than 50
kittiDict["diamensions"] = [scale['z'], scale['y'], scale['x']] #height, width, length
kittiDict["location"] = [camPosition[0], camPosition[1] + float(scale["z"])/2 , camPosition[2] ] # camera coordinate
kittiDict["rotation_y"] = -math.pi/2 - rotation["z"]
# write txt files
with open(Path + "label_2/" + fname.replace('json', 'txt'), 'a+') as f:
for item in kittiDict.values():
if isinstance(item, list):
for temp in item:
f.writelines(str(temp) + " ")
else:
f.writelines(str(item)+ " ")
f.writelines("\n")
# write calibration files
with open(Path + "calib/" + fname.replace('json', 'txt'), 'w') as f:
P2 = np.array(intrinsic).reshape(3,3)
P2 = np.insert(P2, 3, values=np.array([0,0,0]), axis=1)
f.writelines("P0: ")
for num in P2.flatten():
f.writelines(str(num)+ " ")
f.writelines("\n")
f.writelines("P1: ")
for num in P2.flatten():
f.writelines(str(num)+ " ")
f.writelines("\n")
f.writelines("P2: ")
for num in P2.flatten():
f.writelines(str(num)+ " ")
f.writelines("\n")
f.writelines("P3: ")
for num in P2.flatten():
f.writelines(str(num)+ " ")
f.writelines("\n")
f.writelines("R0_rect: ")
for num in np.eye(3,3).flatten():
f.writelines(str(num)+ " ")
f.writelines("\n")
f.writelines("Tr_velo_to_cam: ")
for temp in Tr_velo_to_cam[:3].flatten():
f.writelines(str(temp) + " ")
f.writelines("\n")
f.writelines("Tr_imu_to_velo: ")
for temp in Tr_velo_to_cam[:3].flatten():
f.writelines(str(temp) + " ")
return 0
# SUST image coordinate, kitti camera coordinate
def getCalibMatrix():
with open(calibFile) as fp:
calib = json.load(fp)
return calib["extrinsic"], calib["intrinsic"]
extrinsic, intrinsic = getCalibMatrix()
Tr_velo_to_cam = np.array(extrinsic).reshape(4,4)
print("Tr_velo_to_cam Extrinsic: ", Tr_velo_to_cam)
# read all annotation json files
files = os.listdir(label_path)
total_num = len(files)
testing_num = 4
training_num = total_num - testing_num
print("total files num:", total_num)
print("training files num:", training_num)
print("testing files num:", testing_num)
fileLists = ["test.txt", "train.txt", "trainval.txt", "val.txt"]
for fileName in fileLists:
if fileName == "test.txt":
with open(imageSetsPath + fileName, 'w') as f:
for i in range(training_num,total_num):
errorFlag = calibLabelFileGen(testingPath ,files[i], istrain=False)
if errorFlag:
pass
else:
shutil.copy(sourceImagePath + files[i].replace("json", "png"), testingPath + 'image_2/' + files[i].replace("json", "png")) # copy Image
shutil.copy(sourceVelodynePath + files[i].replace("json", "bin"), testingPath + 'velodyne/' + files[i].replace("json", "bin")) # copy bin
f.writelines(files[i].strip(".json") + "\n")
elif fileName == "train.txt":
with open(imageSetsPath + fileName, 'w') as f:
for i in range(training_num):
errorFlag = calibLabelFileGen(trainingPath , files[i], istrain=True)
if errorFlag:
pass
else:
shutil.copy(sourceImagePath + files[i].replace("json", "png"), trainingPath + 'image_2/' + files[i].replace("json", "png")) # copy Image
shutil.copy(sourceVelodynePath + files[i].replace("json", "bin"), trainingPath + 'velodyne/' + files[i].replace("json", "bin")) # copy bin
f.writelines(files[i].strip(".json") + "\n")
else:
shutil.copy(imageSetsPath + 'train.txt', imageSetsPath + fileName)
7. KITTI-360 Annotation Tool
KITTI-360 Annotation Tool是一个基于python(cherrypy+jinja2+sqlite3)作为服务器端和javascript+WebGL作为前端开发的框架。它是用于注释KITTI-360数据集的注释工具。如果想要进一步了解这个工具的使用可以参考这篇文档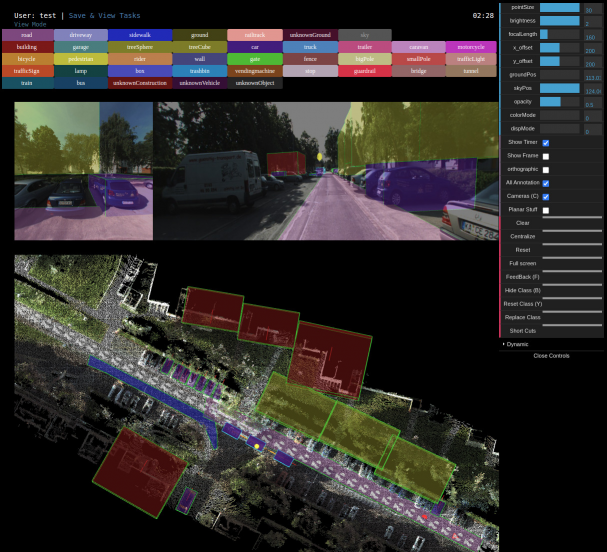
8. 坐标变换并转化为2D标注(bev)
3D bounding box 可以用在2D图像上标注,在nuscenes,KITTI都有,它的目的是利用2D图像学习出深度信息。同时 标注方式和采用的模型是解耦的,因此可以对2D视频、图像进行2D,3D bounding box 的标注,对点云进行3D boundingbox 标注。再把它们转换成bev坐标。一般来说采用的多传感器融合算法的最新方法是bev方法,它属于中融合,也就是特征级别的融合。这里我们可以看一下https://github.com/kuixu/kitti_object_vis这个项目,其可以完成图像与激光的鸟瞰转换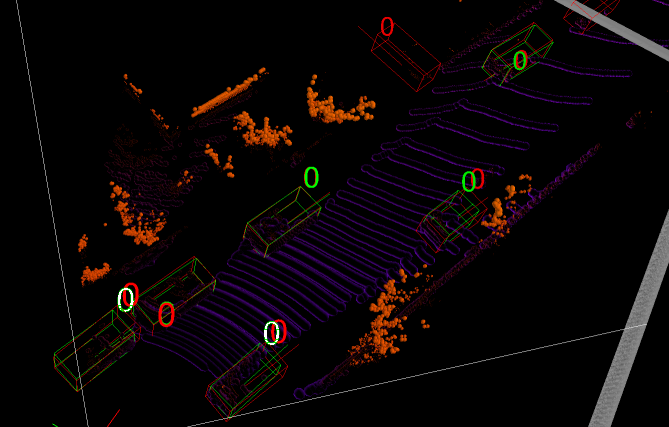
参考链接
https://blog.csdn.net/rhyijg/article/details/108385676
https://zhuanlan.zhihu.com/p/402530977
https://blog.csdn.net/qq_32097577/article/details/120458715
https://blog.csdn.net/qq_30460905/article/details/104349571
https://zhuanlan.zhihu.com/p/402530977



评论(0)
您还未登录,请登录后发表或查看评论