

前言
本文主要详细介绍一些关于张量压缩感知方面的内容,包括相关的基础概念和一些算法原理,并给出具体的Python代码实现过程。
基本概念
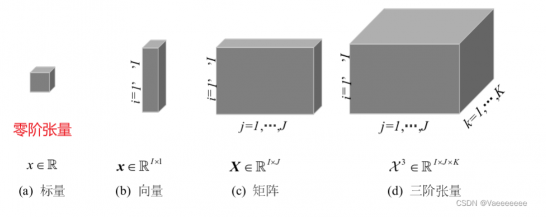
1.1 什么是张量
用一张图可以很好的理解:
1.2 张量的“积”运算
1.2.1 张量内积
含义:两个相同阶的张量之间的运算,是两个张量位置相对应的元素乘积之后的总和。
符号表示:<a,b>
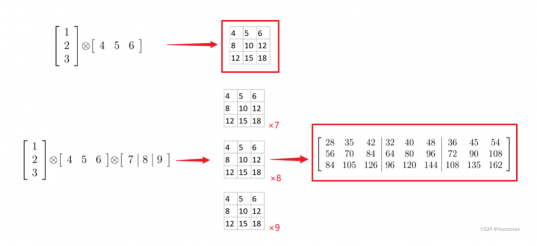
1.2.2 张量外积
含义:张量的外积是对应的向量元素的乘积。
符号表示:A∘B
秩1张量:若某个张量 X 可以表示为n 个向量的外积时,则X 的秩为1。例如下图中的两个张量,都是秩1张量。
</a,b>
1.2.3 kronecker积

1.2.4 Hadamard积
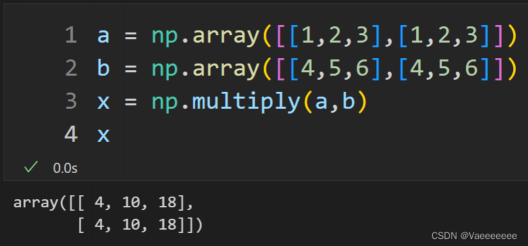
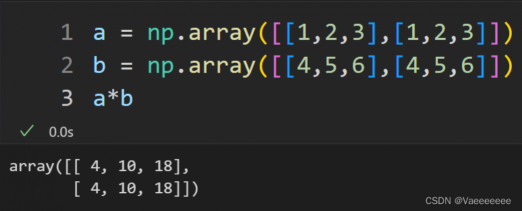
含义:就是两个矩阵对应元素相乘,即矩阵间的点乘,要求两个矩阵的大小相等。
符号表示:A ⊛ B
1.2.5 Khatri-Rao积
含义:又称为列分解相乘(CP)积。

符号表示:A⊙B
1.2.6 n模张量-矩阵积(模态积)

1.2.7 Numpy中的“积”运算
1.内积——np.vdot()函数

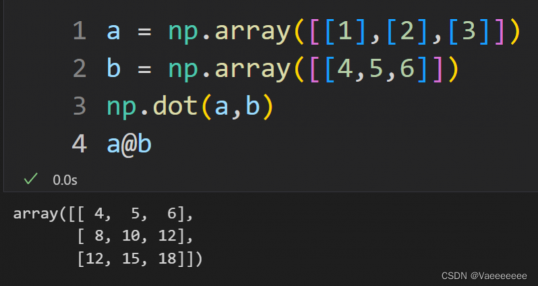
对于两个向量的内积,也可以使用np.inner()或者np.dot函数

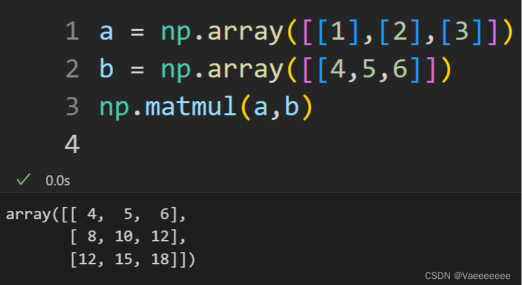
2.外积——np.matmul函数或者直接使用 @ 运算符
3.kronecker积——np.kron()
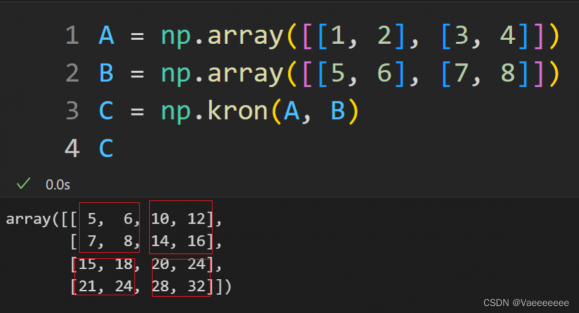
4.Hadamard积——np.multiply函数和 * 运算符
5.模态积——np.einsum()

1.3 张量的分解运算
1.3.1CP分解
种基于高阶张量的矩阵分解方法,简单点说就是将N阶张量分解成多个形状相同的秩一张量的和。
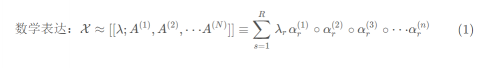
λ:为了将A(1)−A(N)中每列值归一化时,引入的参数列
R:CP秩
当X阶数为3时的分解示意图如下:
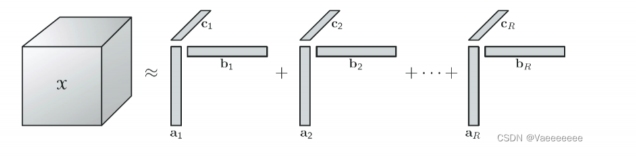
我们把通过外积组成秩1张量元素的向量集合为因子矩阵,例如令
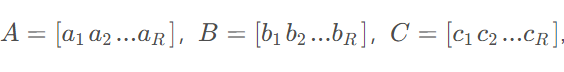
不难发现因子矩阵存在一个共同点,那就是他们的列维度肯定是相同的。
上面( 1 )式可用因子矩阵表示为
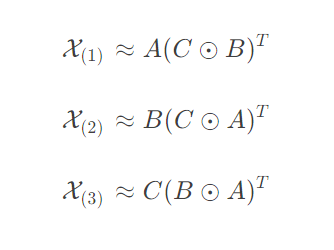
X(n):表示张量以第n nn模态展开得到的矩阵。
1.3.1.1 CP分解算法——ALS-CP(交替最小二乘法)
现在已经知道分解的方法和原理,那么接下来的问题就是如何进行有效分解,其实就是寻找R( X的CP秩) 个秩一向量使得其估计得到的张量最接近初始张量,即待优化的问题为:
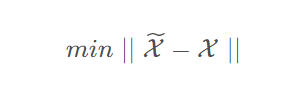
而A L S的思想很简单,以三阶张量分解为例,对应的因子矩阵为A 、 B 、 C,算法流程为:
1.初始化:随机生成一个三维张量X和一个rank为R的分解矩阵集合{A,B,C}。
2.交替更新A、B、C三个矩阵:
a. 固定B和C,通过最小化目标函数来更新A矩阵。
b. 固定A和C,通过最小化目标函数来更新B矩阵。
c. 固定A和B,通过最小化目标函数来更新C矩阵。
3.重复步骤2直到收敛,即当目标函数达到一定精度或迭代次数达到一定值时停止。
4.输出分解矩阵集合{A,B,C},即为原始张量X的CP分解结果
其中,目标函数为:
在每次更新A、B、C矩阵时,可以使用最小二乘法(Least squares)来求解目标函数的最小值,即:

- a. 对于A矩阵,固定B和C,最小化问题被写成:
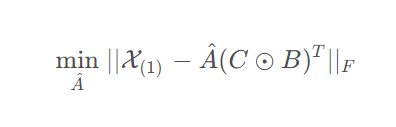
故 A ^的最优解为:

其中,上式又可以根据 Khatri-Rao积的性质写成:
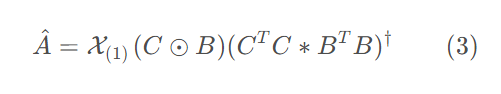
- b. 类似地,对于B矩阵作同样操作:
B^ 的最优解为:
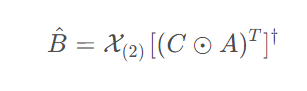
或者
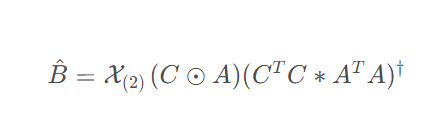
- c. C矩阵的更新公式:
C^ 的最优解为:
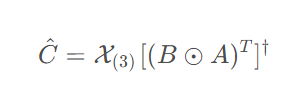
或者
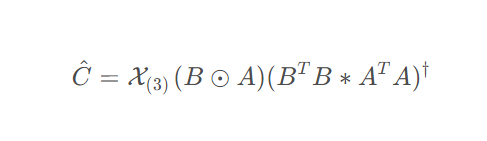
下面是具体实现代码
import numpy as np
from numpy.linalg import norm
from scipy.linalg import khatri_rao
def tensor_mode_unfold(T, p): #函数功能:将张量tensor按模式p展开成矩阵
"""
Unfold tensor T along mode p
"""
T = np.moveaxis(T, p-1, 0)
new_shape = (T.shape[0], np.prod(T.shape[1:]))
T = np.reshape(T, new_shape)
return T
def als_cp(X, R, max_iter=100, tol=1e-6):
"""
ALS-CP算法对三维张量X进行CP分解
:param X: 三维张量
:param R: 分解矩阵集合{A,B,C}的rank
:param max_iter: 最大迭代次数
:param tol: 收敛精度
:return: 分解矩阵集合{A,B,C}
"""
#随机初始化A,B,C
n1, n2, n3 = X.shape
A = np.random.rand(n1, R)
B = np.random.rand(n2, R)
C = np.random.rand(n3, R)
# X按照不同模式展开
X_1 = tensor_mode_unfold(X,1)
X_2 = tensor_mode_unfold(X,2)
X_3 = tensor_mode_unfold(X,3)
# 迭代更新A、B、C
for i in range(max_iter):
# 更新A矩阵
BtB = np.dot(B.T, B)
CtC = np.dot(C.T, C)
# A = X_1 @ khatri_rao(C,B) @ (np.linalg.pinv(CtC*BtB)) #另一种更新公式
A = X_1 @ (np.linalg.pinv(khatri_rao(C,B).T))
A = np.round(A,2) #保留两位小数
# 更新B矩阵
AtA = np.dot(A.T, A)
CtC = np.dot(C.T, C)
# B = X_2 @ khatri_rao(C,A) @ (np.linalg.pinv(CtC*AtA))
B = X_2 @ (np.linalg.pinv(khatri_rao(C,A).T))
B = np.round(B,2)
# 更新C矩阵
AtA = np.dot(A.T, A)
BtB = np.dot(B.T, B)
# C = X_3 @ khatri_rao(B,A) @ (np.linalg.pinv(BtB*AtA))
C = X_3 @ (np.linalg.pinv(khatri_rao(B,A).T))
C = np.round(C,2)
# 计算目标函数值
X_pred = np.einsum('ir,jr,kr->ijk', A, B, C)
err = norm(X - X_pred) / norm(X)
# err = norm(X - X_pred)
if err < tol:
print(err)
print(X_pred)
print(i)
break
return A, B, C
X =np.array([[[21, 26, 31, 36], [43, 54, 65, 76], [65, 82, 99, 116]], [[43, 54, 65, 76], [89, 114, 139, 164], [135, 174, 213, 252]]])
print(als_cp(X, 2, max_iter=2000, tol=0.05))
这里收敛精度取的很低,运行过程中发现如果收敛精度设置的较高,最终分解得到的全是零矩阵。
运行结果如下:
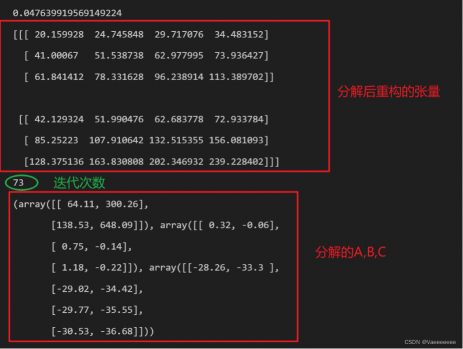
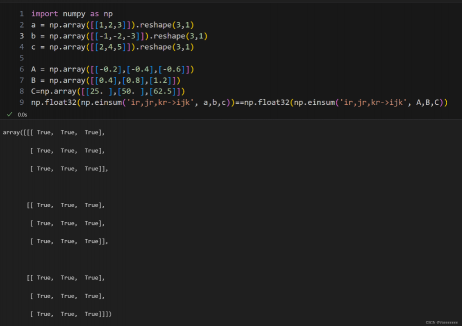
需要注意的是某些张量的分解结果不一定是唯一的,例子如下:
1.3.1.2 CP分解函数——parafac
直接看代码:
import numpy as np
import tensorly as tl
from tensorly.decomposition import parafac #CP分解
X = np.array(
[[[ -2, -4, -5],
[ -4, -8, -10],
[ -6, -12, -15]],
[[ -4, -8, -10],
[ -8, -16, -20],
[-12, -24, -30]],
[[ -6, -12, -15],
[-12, -24, -30],
[-18, -36, -45]]])
factors = parafac(X, rank=1)
print(factors.factors) #打印出分解的矩阵
print('还原结果:',tl.kruskal_to_tensor(factors))
# 或者使用 np.einsum('ir,jr,kr->ijk', factors.factors[0], factors.factors[1], factors.factors[2])
>>>[array([[-25.0998008 ],
[-50.19960159],
[-75.29940239]]), array([[0.26726124],
[0.53452248],
[0.80178373]]), array([[0.2981424 ],
[0.59628479],
[0.74535599]])]
还原结果: [[[ -2. -4. -5.]
[ -4. -8. -10.]
[ -6. -12. -15.]]
[[ -4. -8. -10.]
[ -8. -16. -20.]
[-12. -24. -30.]]
[[ -6. -12. -15.]
[-12. -24. -30.]
[-18. -36. -45.]]]
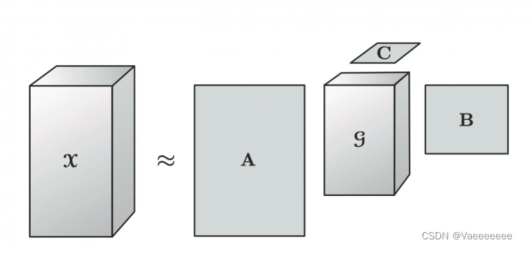
1.3.2 Tucker分解
- 一句话解释:Tucker分解算法将张量分解为核心张量在每个mode上与矩阵的乘积。
- 以一个三维张量X∈R I×J×K分解为一个核心张量G∈R P×Q×R和一组矩阵A∈R I×P,B∈R J×Q,C∈R K×R的乘积:
这里我们直接使用已有函数tensorly.decomposition.tucker实现:
import tensorly as tl
import numpy as np
from tensorly.decomposition import tucker
X =np.array([[[21, 26, 31, 36], [43, 54, 65, 76], [65, 82, 99, 116]], [[43, 54, 65, 76], [89, 114, 139, 164], [135, 174, 213, 252]]])
core, factors = tucker(X, rank=[2,2,2]) #rank的值 = 核张量的大小
print(core)
print(core.shape)
for i in factors:
print(i)
print(i.shape)
>>>[[[ 5.40004250e+02 4.78055587e-04]
[ 1.10588415e-03 2.27895261e+00]]
[[ 8.60894313e-04 2.92055972e+00]
[ 1.28242147e+00 -2.05226289e-01]]]
(2, 2, 2)
[[ 0.42364875 0.90582655]
[ 0.90582655 -0.42364875]]
(2, 2)
[[ 0.24937424 0.87814909]
[ 0.52995313 0.22909171]
[ 0.81053203 -0.41996567]]
(3, 2)
[[ 0.34397247 0.76268141]
[ 0.44018534 0.32593997]
[ 0.53639821 -0.11080146]
[ 0.63261107 -0.5475429 ]]
(4, 2)
验证一下,看一下还原结果:
tl.tucker_to_tensor((core,factors))
#或者使用: X = np.einsum('ijk,ai,bj,ck->abc',core,factors[0],factors[1],factors[2])
>>>array([[[ 21., 26., 31., 36.],
[ 43., 54., 65., 76.],
[ 65., 82., 99., 116.]],
[[ 43., 54., 65., 76.],
[ 89., 114., 139., 164.],
[135., 174., 213., 252.]]])
1.3.2 t-SVD(张量奇异值分解)
Tucker 分解能够将高维张量分解为互不重叠的低维矩阵和核张量的乘积,是一种常用的张量分解方法。但是,Tucker 分解存在着许多问题:例如难以处理高阶张量、储存核张量需要大量空间等。t−SVD(tensor singular value decomposition)分解就是用来解决这些问题的一种改进方法。
首先了解一下SVD(奇异值分解)的基本概念:
对于矩阵A m×n ,A的SVD为:
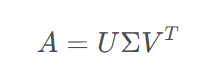
其中U m×m,V n×n都是正交矩阵,Σm×n除主对角线上的元素以外全为0
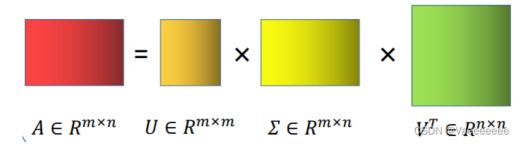
t−SVD 算法也很类似,以三阶张量X i×j×k为例,经过t−SVD分解(其中,S是对角张量)

算法步骤:

1.4 什么是张量压缩感知
介绍完前面的基础知识,再进入正题,了解一下张量压缩感知的概念。- 张量压缩感知(Tensor Compressed Sensing)是一种利用稀疏性和低秩性信息来压缩张量的方法。与传统的向量或矩阵压缩感知不同,张量压缩感知可以对高阶张量进行压缩,例如视频、音频等多维信号。
-
张量压缩感知假设张量本身具有某种结构,例如低秩性或矩阵结构,从而可以使用较少的数据来恢复原始张量。这种方法在处理高维数据时具有很大的优势,可以显著减少存储和计算的成本。
-
张量压缩感知的核心就是张量分解,常用的分解方法在前文已经介绍了一些。通过在低维空间中进行张量分解,并利用稀疏表示和优化算法来实现压缩和恢复操作,可以高效地实现张量压缩感知。
- 张量压缩感知在计算机视觉、信号处理、语音识别等领域有着广泛的应用,可以大大提高数据的存储和传输效率。
")


评论(0)
您还未登录,请登录后发表或查看评论