

深度学习Pytorch框架学习之Mnist数据识别简单程序
代码
平台notebooks
#!/usr/bin/env python
# coding: utf-8
# In[31]:
import numpy as np
from torch import nn,optim
from torch.autograd import Variable
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
import torch
# In[32]:
#训练集
train_dataset = datasets.MNIST(root='./',train=True,transform=transforms.ToTensor(),download=True)
#测试集
test_dataset = datasets.MNIST(root='./',train=True,transform=transforms.ToTensor(),download=True)
# In[33]:
#批次大小
batch_size = 64
#装载数据集
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
#装载测试集
test_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
# In[34]:
for i,data in enumerate(train_loader):
inputs,labels = data
print(inputs.shape)
print(labels.shape)
break
# In[35]:
labels
# In[36]:
inputs
# In[37]:
len(train_loader)
# In[38]:
#定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(784,10)
self.softmax = nn.Softmax(dim=1)
def forward(self,x):
#([64, 1, 28, 28])->(64,784)
x = x.view(x.size()[0],-1)#获得形状的第0个值,-1代表自动匹配,view代表reshape
x = self.fc1(x)
x = self.softmax(x)
return x
# In[39]:
LR = 0.5
#定义模型
model = Net()
#定义代价函数
mse_loss = nn.MSELoss()
#定义优化器
optimizer = optim.SGD(model.parameters(),LR)
# In[40]:
def train():
for i,data in enumerate(train_loader):
#获得一次批次的数据和标签
inputs,labels = data
#获得模型预测的结果(64,10)
out = model(inputs)
#to onehot,把数据标签变成独热编码
#(64) - (64,1)
labels = labels.reshape(-1,1)
#tensor.sactter_(dim,index,src)
#dim:对哪个维度进行独热编码
#index:要将src中对应的值放到tensor的哪个位置
#src:插入index的数值
one_hot = torch.zeros(inputs.shape[0],10).scatter(1,labels,1)
#计算loss,mse_loss的两个数据的shape要一致
loss = mse_loss(out,one_hot)
#梯度清零
optimizer.zero_grad()
#计算梯度
loss.backward()
#修改权值
optimizer.step()
def test():
correct = 0;
for i,data in enumerate(test_loader):
#获得一次批次的数据和标签
inputs,labels = data
#获得模型预测的结果(64,10)
out = model(inputs)
#获得最大值以及最大值所在的位置
_,predicted = torch.max(out,1)
#表示预测正确的数量
correct += (predicted == labels).sum()
print("Test acc:{0}".format(correct.item()/(len(test_dataset))))
# In[ ]:
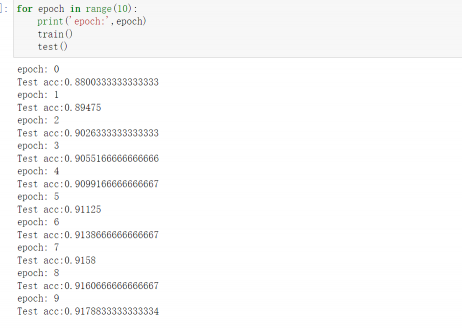
for epoch in range(10):
print('epoch:',epoch)
train()
test()
# In[ ]:
# In[ ]:
现象



评论(0)
您还未登录,请登录后发表或查看评论