

UVTR论文链接:https://arxiv.org/abs/2206.00630
UVTR论文笔记:Unifying Voxel-based Representation with Transformer for 3D Object Detection (UVTR)论文笔记
UVTR代码链接:https://github.com/dvlab-research/UVTR
看本文前建议阅读MMDetection 简单教程之配置文件以及MMDetection3D简单教程:模型定义、注册与搭建。
写在前面:本人正在学习MMDetection3D的过程中,可能有理解错误,欢迎指正。
本文以UVTR的多模态检测方法为例,介绍我是如何阅读MMDetection3D的代码来学习使用MMDetection3D库编程的。注意如果只是为了学习某个部分的细节,或者粗略了解网络结构等,可有所省略而不用完全按照下面的步骤进行。
1.模型相关代码阅读
1.1 阅读配置文件的模型字段
一般来说可以先从配置文件开始读起。
在路径“UVTR/projects/configs/uvtr/multi_modality/”下找到“uvtr_multi_base.py”文件,大体上浏览一遍该配置文件(不必深究细节)。
然后看最关键的模型字段(注意与UVTR的结构图进行比较):
"""代码段1"""
model = dict( # 模型配置
type='UVTR',
...
img_backbone=dict(type='ResNet', ...), # 图像主干
img_neck=dict(type='FPN', ...), # 图像颈部网络
depth_head=dict(type='SimpleDepth', ...), # 深度分类头
pts_voxel_layer=dict(...), # 点体素层
pts_voxel_encoder=dict(type='HardSimpleVFE', ...), # 点体素编码器
pts_middle_encoder=dict(type='SparseEncoderHD', ...), # 点云中间层编码器
pts_backbone=dict(type='SECOND3D', ...), # 点云主干网络
pts_neck=dict(type='SECOND3DFPN', ...), # 点云颈部网络
pts_bbox_head=dict(type='UVTRHead', ...), # 检测头
train_cfg=dict(...) # 训练配置
)
关注模型字段的type值,发现其为UVTR。由于整个模型属于DETECTORS,此时我们去“uvtr/projects/mmdet3d_plugin/models/detectors/”路径下寻找定义UVTR类的代码。
1.2 阅读检测器(DETECTOR)的定义代码
在上面的路径下找到uvtr.py文件,其中定义了UVTR类,这就是我们要读的检测器代码。
"""代码段2"""
@DETECTORS.register_module() # 注册模型
class UVTR(MVXTwoStageDetector): # 继承MVXTwoStageDetector类的方法
"""UVTR."""
def __init__(self, ...): # 重写初始化方法(继承+修改)
super(UVTR, self).__init__(...) # 继承父类初始化方法
... # 修改或新增初始化代码
@property # 加上此修饰,对应方法可以按照访问属性的形式来调用
def with_depth_head(self):
...
@force_fp32() # 该修饰与混合精度训练相关,可暂时置之不理
def extract_pts_feat(self, pts, img_feats, img_metas):
...
def extract_img_feat(self, img, img_metas):
...
@auto_fp16(apply_to=('img')) # 该修饰与混合精度训练相关,可暂时置之不理
def pred_depth(self, img, img_metas, img_feats=None):
...
def forward_pts_train(self, ...):
...
@force_fp32(apply_to=('img', 'points')) # 该修饰与混合精度训练相关,可暂时置之不理
def forward(self, return_loss=True, **kwargs):
...
def forward_train(self, ...):
...
def forward_test(self, img_metas, points=None, img=None, **kwargs):
...
def simple_test_pts(self, pts_feat, img_feats, img_metas, img_depth, rescale=False):
...
def aug_test(self, points, img_metas, imgs=None, rescale=False):
...
def extract_feats(self, points, img_metas, imgs=None):
...
def aug_test_pts(self, pts_feats, img_feats, img_depths, img_metas, rescale=False):
...
与用pytorch继承nn.Module定义的模型相比,读模型文件的阅读方法是相似的(一般来说可以先跳过init函数,读到相应的self.xxx时再回到初始化方法中寻找其定义)。即使有一部分输入现在还并不知道其数据结构(如img_metas),但也基本不影响整体阅读(如果比较在意,可以进行调试观察)。
少数的区别在于,对于其中某些self.xx的参数,可能在初始化方法init函数中不能直接被找到;该类的部分方法在此文件中也找不到。这是因为这些参数的初始化/类内方法的定义继承了其父类(MVXTwoStageDetector)的初始化/定义。遇到这种情况时,可以去其父类的代码中查找,也可以在不影响粗略阅读的情况下跳过。
还有一种情况,例如UVTR类的extract_pts_feat方法中,出现了如
"""代码段3"""
x = self.pts_backbone(x)
这样的代码,但其父类MVXTwoStageDetector中,self.pts_backbone的定义如下:
"""代码段4"""
self.pts_backbone = builder.build_backbone(pts_backbone)
若是继续读builder.build_backbone函数,会发现其中还有不理解的函数,因此不建议这么做。
遇到build_xxx()函数时,往往无需再阅读下去。
实际上,代码段3很容易联想到在forward部分,特征(x)通过某个网络结构(self.pts_backbone)得到输出(x)。因此,在阅读到此处时候,可以先如此理解,读完该类的所有代码之后再去深究。
读完检测器代码后,基本上对模型总体的结构(如组件的先后顺序、级联或并行情况等)以及训练/测试的流程有了一个比较清晰的认识。
1.3 阅读各组件的定义代码(以pts_backbone为例)
检测器各组件相关程序的阅读可以从检测器定义代码出发,其中后者就是在读检测器代码的过程中,记录下需要深入理解的地方(如前面的self.pts_backbone的定义和调用),在读完后进行深究:
从代码段4中可以看到,self.pts_backbone与MVXTwoStageDetector初始化方法的输入pts_backbone相关,而从代码段2中__init__函数的super()语句可以看到,MVXTwoStageDetector初始化方法中输入的pts_backbone就是UVTR初始化方法的输入pts_backbone,其值可以在配置文件的相应位置找到。
代码段1的第22行对应的就是所需的pts_backbone的值。注意到第一项type=”SECOND3D”,这表示我们需要去寻找定义SECOND3D的代码。
在配置文件中,看到type=”xxx”就需要想到去寻找名称为xxx的类的定义代码,以进行深入理解。注意该类可能是MMDetection3D库自带的,也可能是代码作者自己从头编写或者基于某个已有模型编写的。若大体了解其内容,对于MMDetection3D库已有的类可以略过。
实际上更简单的方法是从配置文件出发,直接寻找模型字段中各参数含有type=”xxx”的部分(这些部分通常属于模型组件,如BACKBONE、NECK、MIDDLE_ENCODER等),依次去阅读相关类的定义代码。
从名称pts_backbone可推知,相应的py文件应该放在“uvtr/projects/mmdet3d_plugin/models/backbones/”路径下。 在该路径下找到second_3d.py文件,其中定义的SECOND3D类即为我们要读的代码:
@BACKBONES.register_module()
class SECOND3D(BaseModule):
def __init__(self, ...):
super(SECOND3D, self).__init__(init_cfg=init_cfg)
...
def forward(self, x):
...
上述代码的阅读就更加简单了。其中可能会遇到如
build_conv_layer(conv_cfg, ...)
build_norm_layer(norm_cfg, ...)
的代码,直接理解为nn,Conv或nn.BatchNorm等初始化模型结构的语句就好,不必深究。
诸如BACKBONE、NECK、MIDDLE_ENCODERS、TRANSFORMER、ATTENTION等类型的组件,往往只需要定义__init__函数和forward函数(输出特征)。
DETECTOR类型也一样,只是注意其在训练或者测试时的forward过程不完全相同(训练时需要输出损失、测试时需要输出预测边界框,损失和边界框都来自检测头DENSE_HEAD的方法)。
1.4 阅读检测头的定义代码
由于检测头的代码往往更加复杂,因此单独介绍。
检测头部分也包含了视图变换、边界框分配和编码、以及损失函数的定义;因此,可能也需要阅读视图变换、边界框分配和编码等相关代码。但由于其组件的输出可能不再仅仅是特征,可能更适合从检测头代码出发阅读组件代码以了解输出内容和结构。
例如,在“uvtr/projects/mmdet3d_plugin/models/dense_heads/uvtr_head.py”文件的UVTRHead类下,forward方法中有这样一句话:
hs, init_reference, inter_references = self.transformer(...)
直接看不太能理解输出的含义,因此需要从transformer的代码入手理解。在配置文件中观察到transformer的type=”Uni3DDETR”,则找到Uni3DDETR类进行阅读。
在Uni3DDETR类的forward函数中,又需要阅读decoder(UniTransformerDecoder类)的代码,但UniTransformerDecoder类又继承了TransformerLayerSequence的方法,其中的self.layers又需要在TransformerLayerSequence类中寻找定义:
"""该部分为MMDetection3D官方代码"""
@TRANSFORMER_LAYER_SEQUENCE.register_module()
class TransformerLayerSequence(BaseModule):
def __init__(self, transformerlayers=None, num_layers=None, init_cfg=None):
super().__init__(init_cfg)
if isinstance(transformerlayers, dict):
transformerlayers = [
copy.deepcopy(transformerlayers) for _ in range(num_layers)
]
else:
...
...
for i in range(num_layers):
self.layers.append(build_transformer_layer(transformerlayers[i]))
...
可以看到transformerlayers首先被复制为一个列表,然后依次进行build_transformer_layer(即num_layer层相同的transformer块),此时从配置文件找到transformerlayers:
transformerlayers=dict(
type='BaseTransformerLayer',
attn_cfgs=[
dict(type='MultiheadAttention', ...),
dict(type='UniCrossAtten', ...)
],
ffn_cfgs=dict(type='FFN', ...),
norm_cfg=dict(type='LN'),
operation_order=('self_attn', 'norm', 'cross_attn', 'norm', 'ffn', 'norm'))
此时可以去寻找BaseTransformerLayer类(该类也源自MMDetection3D官方)的定义,但因为transformer不需要我们手动编写程序,所以没有必要去看。若对transformer有所了解的话,将上述参数结合UVTR的结构图应该可以直接猜测每个transformer块的结构:
输入→多头自注意力→LayerNorm→交叉注意力→LayerNorm→前馈网络→LayerNorm→输出
这里的交叉注意力对应UniCrossAtten类,为本代码作者编写,可以参考学习如何自定义transformer中的注意力机制。
DENSE_HEAD类型组件的函数除了编写__init__和forward(输出初步的边界框预测结果)外,往往还需包含损失函数计算以及预测边界框后处理(均以forward函数的输出作为输入)函数。后两者在DETECTOR中被调用。
如果目的是深入理解模型,在读完模型相关代码后就可以停止了。但如果需要了解和学习训练的一些细节,可能还需要阅读数据预处理相关的代码。
2.数据预处理和数据增广相关代码阅读
数据预处理部分在配置文件中对应data字段的pipeline部分,这里以训练时数据预处理流程为例:
train_pipeline = [
dict(type='LoadPointsFromFile', ...),
dict(type='LoadPointsFromMultiSweeps', ...),
dict(type='LoadMultiViewImageFromFiles', ...),
dict(type='PhotoMetricDistortionMultiViewImage'),
dict(type='LoadAnnotations3D', ...),
dict(type='UnifiedObjectSample', ...),
dict(type='UnifiedRotScaleTrans', ...),
dict(type='UnifiedRandomFlip3D', ...),
dict(type='PointsRangeFilter', ...),
dict(type='ObjectRangeFilter', ...),
dict(type='ObjectNameFilter', ...),
dict(type='PointShuffle'),
dict(type='NormalizeMultiviewImage', ...),
dict(type='PadMultiViewImage', ...),
dict(type='DefaultFormatBundle3D', ...),
dict(type='CollectUnified3D', ...)
]
MMDetection3D的官方文档给出了典型的数据预处理流程,如下图所示:
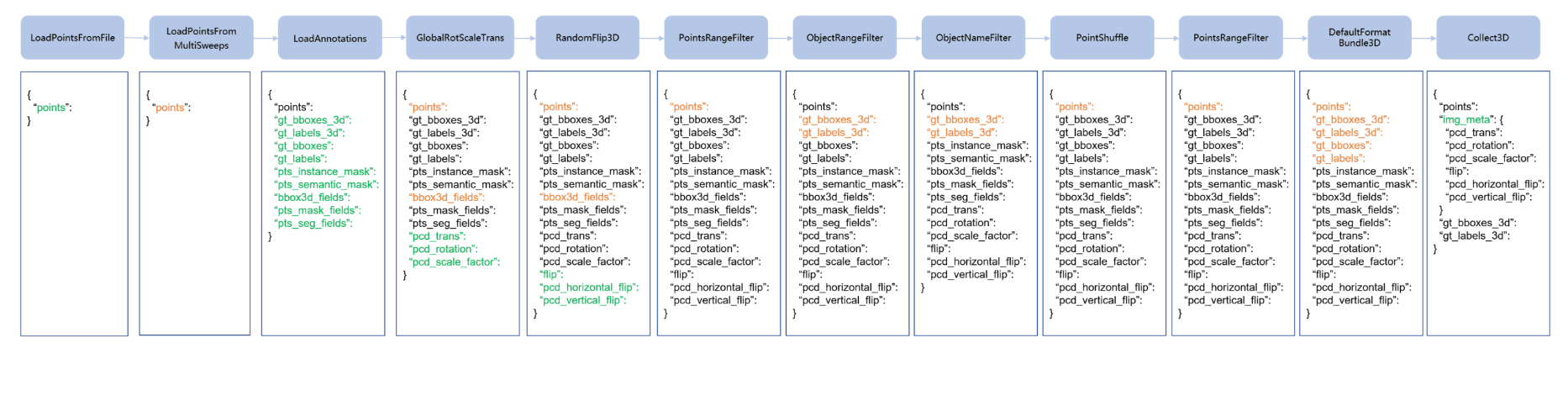
可见本代码的数据预处理流程大体符合上图,但由于是多模态数据,所以添加了图像读取和预处理,并将单一模态数据增广操作修改为论文提到的统一数据增广;此外,字典中可能还需要添加激光雷达坐标到相机坐标或图像坐标的变换矩阵等相关信息。
具体代码的阅读相对来说比较简单,且基本上相互独立,可从配置文件出发依次阅读。这里面唯一有“嵌套”的项为UnifiedObjectSampler,其包含了UnifiedDataBaseSampler类的db_sampler项,且其中的DataBase需要由“uvtr/extra_tools/data_converter/create_unified_gt_database.py”文件生成。
预处理的相关类一般被注册为PIPELINE类型,需要定义init和call函数(输入和输出均为上图中的字典)。预处理步骤的顺序由配置文件中的顺序决定,每进行一个pipeline步骤,上图中的字典就会被更新。
对于多模态数据而言,最终的字典中通常需包含点云和图像数据、标注信息、预处理和数据增广参数,以及各传感器的坐标系变换矩阵等等。
3.数据集相关代码阅读
后续部分暂时未深入理解,仅作参考。
一般来说,MMDetection3D官方提供的数据集代码无需修改,遇到新的数据集可以通过将其格式组织为现有数据集的相同形式来实现,但有时候组织可能比较困难,且有可能需要添加功能或修改功能。因此还是需要学习数据集代码的形式和内容。
阅读该部分代码时,可能需要下载数据集以了解一些文件的数据结构。
数据集代码可直接从其定义NuScenesSweepDataset类的代码出发,即找到“uvtr/projects/mmdet3d_plugin/datasets/nuscenes_dataset.py”文件。这部分代码是在MMDetection3D官方代码的基础上修改的,主要是添加了图像sweep的信息读取操作。
此外,额外的数据准备程序(如create_data.py以及nuscenes_converter.py文件)也是在官方代码上进行修改的。
自定义数据集类往往需要包含init函数、get_data_info函数(输入为数据编号idx,获取第idx个数据的信息;输出为数据信息字典,该字典会作为第2节中的pipeline列表的第一个类__call__函数的输入)和evaluate函数(输入为检测结果以及评估相关设置)
若需要针对一个新的数据集写数据准备和读取代码,可先下载数据集并了解数据集格式和标注信息,找到MMDetection3D已实现的与其最接近的数据集准备和读取代码(或是自己整理数据集文件使其格式与某一现有数据集相似),然后在其基础上,一边调试一边修改:
首先,create_data.py就实现了所有的数据准备工作,在其中找到需要的data_prep函数,输入合适的参数(如数据集类型、数据路径等)开始一边调试一边按需修改(注意检查其中用到的工具函数是否适用于新数据集)。
注意如果选择的data_prep函数最后调用了create_groundtruth_database函数(该函数的作用是创建包含真实物体的数据库,用于复制粘贴数据增广),不管是否需要进行复制粘贴数据增广,都可以调试该函数的前半段,以确保数据集类和数据读取相关pipeline的正确性。观察create_groundtruth_database可发现,其中的重点代码如下:
...
dataset_cfg = dict(type=dataset_class_name, data_root=data_path, ann_file=info_path)
if dataset_class_name=='xxx':
dataset_cfg.update(...,
pipeline=[
dict(type='xxx', ...),
dict(...),
...
])
dataset = bulid_dataset(dataset_cfg)
...
for j in track_iter_progress(list(range(len(dataset)))):
input_dict = dataset.get_data_info(j)
dataset.pre_pipeline(input_dict)
example = dataset.pipeline(input_dict)
...
上述代码包含配置参数设置(配置文件中的字典结构)、数据集建立和数据读取pipeline部分,其中第13行可以调试数据集类中的get_data_info方法,第15行可以调试dataset_cfg中的pipeline(可将断点打在pipeline类的__call__代码上)。
若data_prep函数中没有create_groundtruth_database函数,也可新建一个.py文件写上类似上面的代码进行调试。
4.训练和测试代码阅读
该部分包含train.py和test.py两个文件,基本就是在官方代码的基础上进行少量修改。里面可能会用到一些数据集的操作(在数据集文件中定义),所以放在最后进行阅读。
train.py中前面较多的语句都是在读取配置文件、设置环境、建立日志并记录信息等操作,比较关键的语句如下:
...
model = build_model(cfg.model, train_cfg=cfg.get('train_cfg'),
test_cfg=cfg.get('test_cfg')) # 建立模型
model.init_weights() # 初始化权重
...
datasets = [build_dataset(cfg.data.train)] # 读取并预处理数据,建立训练集
...
train_model(model, datasets, cfg, ...) # 训练模型
test.py类似,比较关键的语句如下:
...
dataset = build_dataset(cfg.data.test) # 读取数据并进行预处理,建立测试集
data_loader = build_dataloader(dataset, ...) # 建立测试数据读取器
...
model = build_model(cfg.model, test_cfg=cfg.get('test_cfg')) # 建立模型
...
checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu') # 读取已有模型参数
...
if not distributed:
...
outputs = single_gpu_test(model, data_loader, ...) # 单一GPU测试
else:
...
outputs = multi_gpu_test(model, data_loader, ...) # 多GPU测试
...
if ...:
dataset.format_results(outputs, **kwargs) # 结果保存为评估所需格式
...
print(dataset.evaluate(outputs, **eval_kwargs)) # 评估测试性能并打印



评论(0)
您还未登录,请登录后发表或查看评论