

Sigmoid函数
我们想定义一个函数,即能够接受所有特征输入(自变量)然后预测出类别(因变量)。在二分类的情况下,可以定义输出为0和1。比如要预测一个动物是不是鸟类,是则为1,不是则为0。具有这种性质的函数,比较简单的就是单位阶跃函数(Heaviside step function)。但是该函数在x=0处从0瞬间跳变到1,这样就很难处理。换句话讲,阶跃函数在x=0处不可微,这就不利于后面使用梯度上升或下降的方法。此时另一个函数就满足类似的性质,即可以输出0或1,这就是Sigmoid函数,如下

如图5-1,当x=0时,Sigmoid函数值为0.5,随着x增大,对应的值将逼近于1;而随着x减小,Sigmoid值将逼近于0。如果横坐标刻度足够大,如图5-1下图,Sigmoid函数看起来就很像一个阶跃函数。

Logistic回归
而Logistic回归就是上面Sigmoid函数的输入z定义为以下形式:

其中x 1 , x 2 , . . . , x n 是输入的特征即自变量,w 1 , w 2 , . . . w n 就是特征对应的权重,或者叫回归系数,而通常b = w 0 x 0 是偏移量设为1,上面公式可以简写为:

即Logistic回归的模型,剩下的我们只需要求出参数w和b。
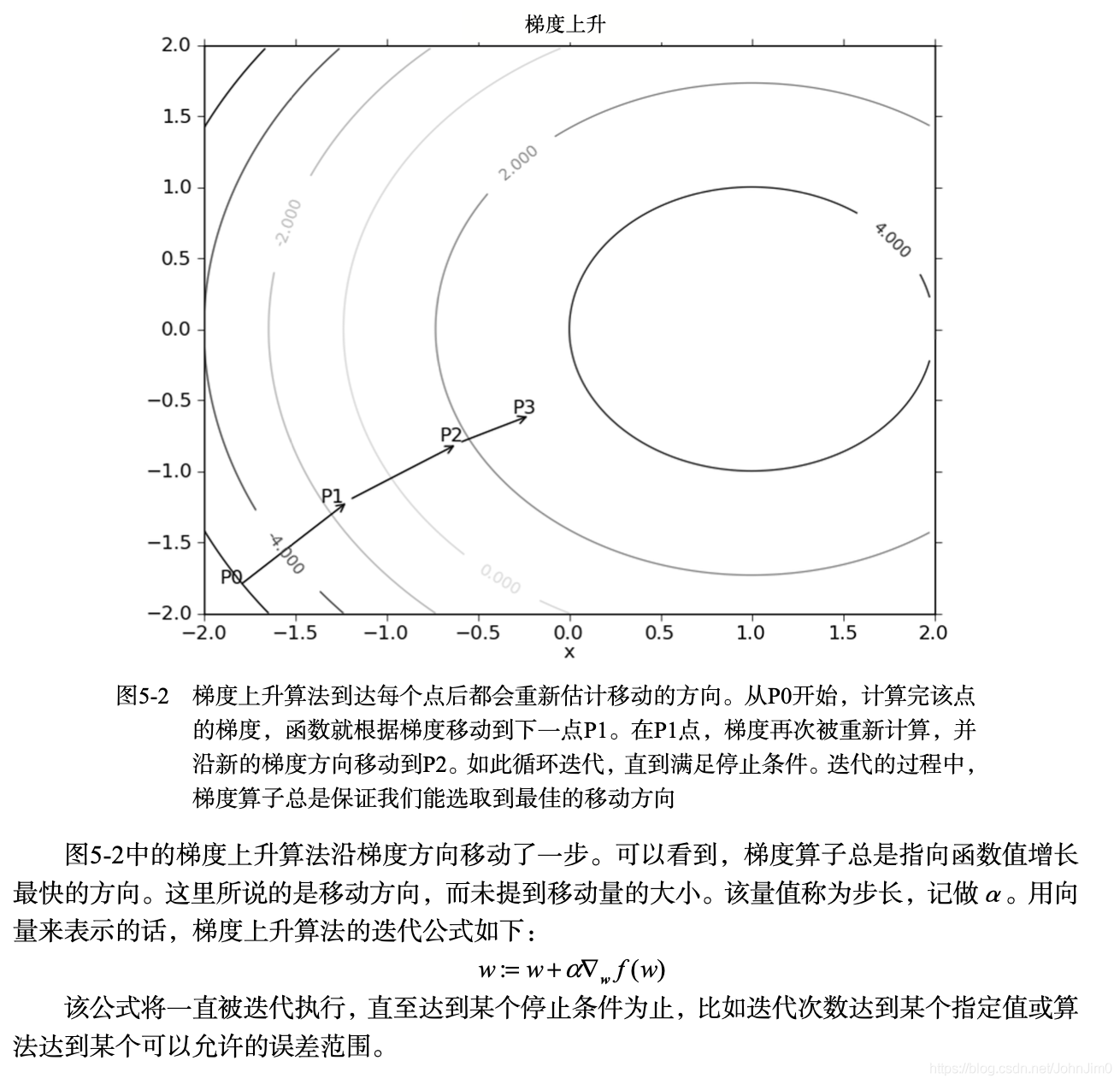
梯度上升法
怎么求出参数w和b呢?书中给出了梯度上升法,随机梯度上升以及改进的随机梯度上升,梯度上升跟下降类似,只不过前者就局部最大值,后者求的是最小值。原理的雏形可结合导数与极值的关系,比较容易理解,参考:

随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
需要理解批量梯度,也就是书中给出了第一种梯度上升,以及mini-batch梯度下降,和随机梯度下降,简单来讲就是随机梯度一次仅用一个样本点来更新回归系数,mini-batch使用一小部分,批量梯度则是全部,这样的话训练速度更新会很慢,所以随机梯度比较流行。并且随机梯度是一个在线算法,可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批处理运算。
代码
以下是基于梯度上升的Logistic回归算法,其中alpha就是机器学习中常讲的学习率,也就是机器学习实战这本书所讲的步长。
import numpy as np
def sigmoid(inX):
'''sigmoid函数
'''
return 1.0/(1+np.exp(-inX))
def gradAscent(dataMat,labelMat):
'''批量梯度上升
'''
dataMat=np.mat(dataMat)
labelMat=np.mat(labelMat).transpose()
m,n=np.shape(dataMat) # m cannot be deleted
alpha=0.001
maxCycles=500
weights=np.ones((n,1)) #weights[3*1]
for k in range(maxCycles):
h=sigmoid(dataMat*weights)
error=(labelMat-h) #error[100*1]
weights=weights+alpha*dataMat.transpose()*error
print(weights)
return weights
def stocGradAscent0(dataMat,labelMat):
'''随机梯度上升
'''
m,n=np.shape(dataMat) #dataMat[100*3]
alpha=0.01
weights=np.ones(n) #weights[1*3]
dataArr=np.array(dataMat)
for i in range(m):
h=sigmoid(sum(dataMat[i]*weights)) # dataMat[i]表示一个样本
error=labelMat[i]-h
weights=weights+alpha*error*dataArr[i]
return weights
def stocGradAscent1(dataMat,labelMat,iteration=150):
'''改进的随机梯度上升
'''
m,n=np.shape(dataMat)
weights=np.ones(n)
dataArr=np.array(dataMat)
for j in range(iteration):
dataIndex=dataMat.copy() # initially dataIndex=range(m),but a range cannot be operated by del() at line 75
for i in range(m):
alpha=4/(1.0+j+i)+0.01 #apha decreases with iteration, does not
randIndex=int(np.random.uniform(0,len(dataIndex))) #go to 0 because of the constant
h=sigmoid(sum(dataMat[randIndex]*weights))
error=labelMat[randIndex]-h
weights=weights+alpha*error*dataArr[randIndex]
del(dataIndex[randIndex])
return weights
def classifyVector(inX,weights):
prob=sigmoid(sum(inX*weights))
if prob>0.5: return 1.0
else: return 0.0
相关问题
以下问题提供思考:
- Logistic回归与多重线性回归的区别?



评论(0)
您还未登录,请登录后发表或查看评论