

观前提醒:本章内容为训练一个强化学习模型,并使用强化学习模型控制月球着陆器。安装和运行DI-engine示例。
什么是DI-engine?
DI-engine 是一个由 OpenDILab 提供的开源强化学习(Reinforcement Learning,简称RL)库,它旨在提供一个易于使用、灵活且高效的RL算法研究和应用平台。DI-engine 不仅支持多种RL算法,还提供了易于扩展的接口,可以帮助研究人员和开发者快速开发和测试自己的RL算法。
它将为我们的强化学习算法研究和开发工作提供最专业最便捷的帮助,主要包括:
-
完整的算法支持,例如 DQN,PPO,SAC 以及许多研究子领域的相关算法——多智能体强化学习中的 QMIX,逆强化学习中的 GAIL,探索问题中的 RND 等等。
-
友好的用户接口,我们抽象了强化学习任务中的大部分常见对象,例如环境,策略,并将复杂的强化学习流程封装成丰富的中间件,让您随心所欲的构建自己的学习流程。
-
弹性的拓展能力,利用框架内集成的消息组件和事件编程接口,您可以灵活的将基础研究工作拓展到工业级大规模训练集群中,例如星际争霸智能体 DI-star。
DI-engine 的特点
- 丰富的算法支持:DI-engine 实现了众多经典和现代的强化学习算法。
- 模块化设计:组件化的设计使得算法、环境、网络结构等模块可以自由组合。
- 易于扩展:提供了简单的接口来添加新的算法、环境或其他组件。
- 分布式训练:支持多进程或多机训练,提升了训练效率。
- 多环境适应性:可以与OpenAI Gym、DM Control等多种环境接口兼容。
安装DI-engine
在安装DI-engine之前,请确保你的计算环境满足以下条件:
- Python 3.6+
- PyTorch 1.4+
- 其它依赖库
你可以通过Python的包管理工具pip来安装DI-engine:
pip install DI-engine
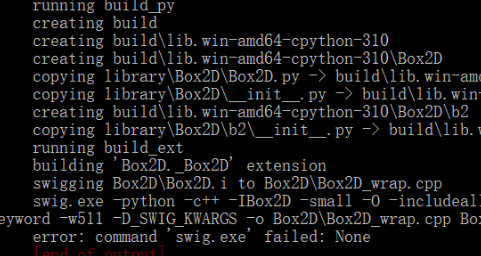
踩坑提醒:gym在安装时会报错。gym是一个强化学习的Python库,它依赖box2d,box2d是一个游戏领域的2D图形引擎,它在运行时又会依赖到swig,swig是一个将c/c++代码封装为Python库的工具(是Python调用c/c++库的一种常见手段)。不过现在swig可以通过pip安装,所以我们只需提前运行:
pip install swig
控制程序

import gym # 载入 gym 库,用于标准化强化学习环境
import torch # 载入 PyTorch 库,用于加载 Tensor 模型,定义计算网络
from easydict import EasyDict # 载入 EasyDict,用于实例化配置文件
from ding.config import compile_config # 载入DI-engine config 中配置相关组件
from ding.envs import DingEnvWrapper # 载入DI-engine env 中环境相关组件
from ding.policy import DQNPolicy, single_env_forward_wrapper # 载入DI-engine policy 中策略相关组件
from ding.model import DQN # 载入DI-engine model 中模型相关组件
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config # 载入DI-zoo lunarlander 环境与 DQN 算法相关配置
def main(main_config: EasyDict, create_config: EasyDict, ckpt_path: str):
main_config.exp_name = 'lunarlander_dqn_deploy' # 设置本次部署运行的实验名,即为将要创建的工程文件夹名
cfg = compile_config(main_config, create_cfg=create_config, auto=True) # 编译生成所有的配置
env = DingEnvWrapper(gym.make(cfg.env.env_id), EasyDict(env_wrapper='default')) # 在gym的环境实例的基础上添加DI-engine的环境装饰器
env.enable_save_replay(replay_path='./lunarlander_dqn_deploy/video') # 开启环境的视频录制,设置视频存放位置
model = DQN(**cfg.policy.model) # 导入模型配置,实例化DQN模型
state_dict = torch.load(ckpt_path, map_location='cpu') # 从模型文件加载模型参数
model.load_state_dict(state_dict['model']) # 将模型参数载入模型
policy = DQNPolicy(cfg.policy, model=model).eval_mode # 导入策略配置,导入模型,实例化DQN策略,并选择评价模式
forward_fn = single_env_forward_wrapper(policy.forward) # 使用简单环境的策略装饰器,装饰DQN策略的决策方法
obs = env.reset() # 重置初始化环境,获得初始观测
returns = 0. # 初始化总奖励
while True: # 让智能体的策略与环境,循环交互直到结束
action = forward_fn(obs) # 根据观测状态,决定决策动作
obs, rew, done, info = env.step(action) # 执行决策动作,与环境交互,获得下一步的观测状态,此次交互的奖励,是否结束的信号,以及其它环境信息
returns += rew # 累计奖励回报
if done:
break
print(f'Deploy is finished, final epsiode return is: {returns}')
if __name__ == "__main__":
main(main_config=main_config, create_config=create_config, ckpt_path='./final.pth.tar')
示例的代码里,通过使用 torch.load 可以获得模型的 PyTorch 对象的参数。 然后使用 load_state_dict 即可将模型加载至 DI-engine 的 DQN 模型中,这样就可以完整地恢复该模型。 然后将 DQN 模型加载到 DQN 策略中,使用评价模式的 forward_fn 函数,即可让智能体对环境状态 obs 产生反馈的动作 action 。 智能体的动作 action 会和环境进行一次互动,生成下一个时刻的环境状态 obs (observation) ,此次交互的奖励 rew (reward),环境是否结束的信号 done 以及其他信息 info (information) 。
控制程序详尽分析
导入依赖
import gym
import torch
from easydict import EasyDict
from ding.config import compile_config
from ding.envs import DingEnvWrapper
from ding.policy import DQNPolicy, single_env_forward_wrapper
from ding.model import DQN
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config
gym: 一个提供多种强化学习环境的库。torch: PyTorch深度学习框架,用于构建和训练神经网络。EasyDict: 一个提供字典属性访问方式的库。compile_config: DI-engine的函数,用于编译和合并配置文件。DingEnvWrapper: DI-engine的环境包装器,用于在Gym环境上添加附加功能。DQNPolicy: DI-engine中实现的DQN策略。single_env_forward_wrapper: 一个函数,用于简化策略在单个环境上的应用。DQN: DI-engine中定义的DQN模型。lunarlander_dqn_config: 包含LunarLander环境和DQN算法配置的模块。
main函数
def main(main_config: EasyDict, create_config: EasyDict, ckpt_path: str):
main 函数是程序的入口点,它接受配置和模型检查点路径作为参数。
配置和环境设置
main_config.exp_name = 'lunarlander_dqn_deploy'
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
env = DingEnvWrapper(gym.make(cfg.env.env_id), EasyDict(env_wrapper='default'))
env.enable_save_replay(replay_path='./lunarlander_dqn_deploy/video')
main_config.exp_name: 设置实验名称,通常用于日志和保存文件的命名。cfg: 通过编译主配置和创建配置来生成最终的配置。env: 创建一个Gym环境,并使用DingEnvWrapper进行包装以添加额外的DI-engine功能。env.enable_save_replay: 开启环境的视频录制功能,指定视频保存的路径。
模型和策略加载
model = DQN(**cfg.policy.model)
state_dict = torch.load(ckpt_path, map_location='cpu')
model.load_state_dict(state_dict['model'])
policy = DQNPolicy(cfg.policy, model=model).eval_mode
forward_fn = single_env_forward_wrapper(policy.forward)
model: 实例化DQN模型。state_dict: 从给定路径加载模型权重。model.load_state_dict: 将加载的权重应用到模型。policy: 创建一个DQN策略实例,并设置为评估模式。forward_fn: 使用single_env_forward_wrapper将策略的前向函数包装起来,以便于在环境中使用。
与环境交互
obs = env.reset()
returns = 0.
while True:
action = forward_fn(obs)
obs, rew, done, info = env.step(action)
returns += rew
if done:
break
env.reset(): 重置环境到初始状态,获取初始观测。returns: 初始化累计奖励。- 在一个无限循环中,使用包装过的策略函数根据当前观测计算动作,执行动作,并获取新的观测、奖励和结束信号。
- 如果环境返回
done为True,表示一次完整的episode结束,此时退出循环。
结果输出
print(f'Deploy is finished, final epsiode return is: {returns}')
在环境交互结束后,打印出累计的奖励,表示这个episode的总回报程序的主要目标是利用深度强化学习算法(具体为深度Q网络,DQN)来控制Gym环境中的LunarLander。
程序的主要的执行流程如下:
-
导入库和模块:程序开始时导入所需的库和模块,包括Gym环境库、PyTorch深度学习框架、EasyDict辅助工具类库、DI-engine的配置、环境、策略、模型组件,以及预定义的LunarLander环境配置。
-
定义
main函数:主函数接收主配置文件、创建配置文件和模型检查点文件路径作为输入参数。 -
设置实验名称:通过修改
main_config.exp_name来设置实验名称,这通常用于日志记录和文件保存。 -
编译配置:调用
compile_config函数将主配置文件和创建配置文件编译成一个完整的配置,这个配置包含了环境、模型和策略等相关设置。 -
环境初始化:使用Gym库创建LunarLander环境实例,并通过
DingEnvWrapper进行包装以适配DI-engine的环境接口。 -
启用视频录制:通过
env.enable_save_replay启用环境的视频录制功能,可以将智能体的表现记录成视频文件。 -
模型和策略初始化:实例化DQN模型,并使用PyTorch的
torch.load函数加载预训练的模型权重。之后,创建一个DQN策略实例并设置为评估模式,这样可以在不进行进一步学习的情况下评估模型的性能。 -
策略执行函数:使用
single_env_forward_wrapper将策略的forward方法包装起来,这样在单环境下可以更方便地使用。 -
运行环境与策略交互循环:初始化环境并获取初始观测值,然后在一个循环中连续执行策略,直到环境返回一个完成信号(
done为True)。每一步都会根据当前的观测值选择并执行一个动作,并接收环境返回的新观测值、即时奖励和完成状态。 -
累计奖励:在每一步中,将环境返回的即时奖励添加到累计奖励中。
-
输出结果:当环境返回完成信号时,结束循环,并打印最终的累计奖励作为智能体性能的指标。
-
主入口:如果程序作为主模块执行,将会调用
main函数并传入主配置、创建配置和模型检查点路径。
整体上,这个程序是一个典型的强化学习部署流程,用于在一个特定的任务(此处为LunarLander)上运行和评估一个预训练的模型。
运行模型训练程序
import gym
from ditk import logging
from ding.model import DQN
from ding.policy import DQNPolicy
from ding.envs import DingEnvWrapper, BaseEnvManagerV2, SubprocessEnvManagerV2
from ding.data import DequeBuffer
from ding.config import compile_config
from ding.framework import task, ding_init
from ding.framework.context import OnlineRLContext
from ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, \
eps_greedy_handler, CkptSaver, online_logger, nstep_reward_enhancer
from ding.utils import set_pkg_seed
from dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_config
def main():
logging.getLogger().setLevel(logging.INFO)
cfg = compile_config(main_config, create_cfg=create_config, auto=True)
ding_init(cfg)
with task.start(async_mode=False, ctx=OnlineRLContext()):
collector_env = SubprocessEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.collector_env_num)],
cfg=cfg.env.manager
)
evaluator_env = SubprocessEnvManagerV2(
env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.evaluator_env_num)],
cfg=cfg.env.manager
)
set_pkg_seed(cfg.seed, use_cuda=cfg.policy.cuda)
model = DQN(**cfg.policy.model)
buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)
policy = DQNPolicy(cfg.policy, model=model)
task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))
task.use(eps_greedy_handler(cfg))
task.use(StepCollector(cfg, policy.collect_mode, collector_env))
task.use(nstep_reward_enhancer(cfg))
task.use(data_pusher(cfg, buffer_))
task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_))
task.use(online_logger(train_show_freq=10))
task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))
task.run()
if __name__ == "__main__":
main()
将生成的.tar文件复制到示例程序的同级目录下,即final.path.tar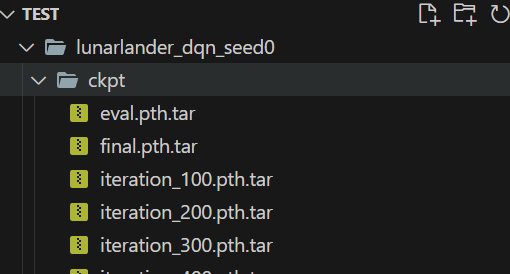
运行控制程序

使用了强化学习模型运行效果如下:



评论(0)
您还未登录,请登录后发表或查看评论