

Key Concepts in RL
本文讨论的内容:
- RL中的语言和符号
- 对强化学习算法的作用的上层解释
- RL算法的核心数学公式
简而言之。RL研究agent通过试验和错误(trial and error)来进行学习,它利用奖励或者惩罚agent的行为使其在未来重复或放弃当前的行为。
Key Concepts and Terminology
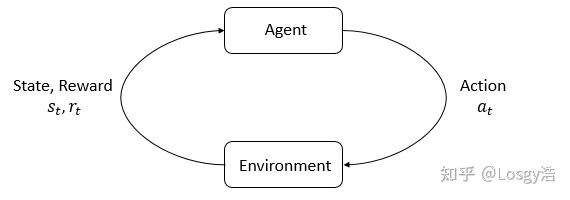
RL中的主要特点是agent和environment, environment是agent存在和交互的世界,每一步交互,agent都会看到当前世界的状态(或一部分),然后决定采取什么动作,当agent对其进行操作时,环境会发生变化,但也可能会自行发生变化。
agent也从environment中获取reward,它是一个告诉agent当前世界状态好坏的数字,agent的目标是最大化累计reward,称为return, RL算法就是agent用来学习行为并且达成这个目标的方法。
为了进一步说明RL做了什么,我们进一步阐述:
- states and observations
- action spaces
- policies
- trajectories
- different formulations of return
- the RL optimization problem
- value functions
states and observations
state s 是对世界状态的完整描述,state的信息是不会隐藏的。 observation o 是状态的部分描述,可能会省略信息。
state是客观存在的,而observation是agent可能部分观察到的
在DRL中,我们几乎总是用实值向量、矩阵或高阶张量来表示states 和 observations。 例如,视觉图像可以由其像素值的 RGB 矩阵表示; 机器人的状态可以用它的关节角度和速度来表示。 当agent能够观察到环境的完整状态时,我们说环境被Fully observed到了。 当智能体只能看到部分观察时,我们说环境被partially observed。
Action Spaces
不同的环境允许不同种类的动作。 给定环境中所有有效动作的集合通常称为动作空间。 一些环境,如 Atari 和 Go,有离散的动作空间,其中只有有限数量的动作可供代理使用。 其他环境,例如代理在物理世界中控制机器人的地方,具有连续的动作空间。 在连续空间中,动作是实值向量。 这种区别对DRL方法有一些非常大的影响。 一些算法系列只能应用于离散情况。
Policies
策略是agent决定采取什么动作的规则,他可以是确定性的(deterministic),表示为:
或是随机性的(stochastic):
因为策略本质上是agent的大脑,所以用“policy”代替“agent”这个词并不少见,例如说“策略试图最大化奖励”。
在RL中,我们处理参数化的policy,其输出是依赖于一组参数(例如神经网络的权重和偏差)的可计算函数,我们可以通过优化算法调整这些参数。
Deterministic policies
下面是确定性策略的连续动作空间 pytorch网络,使用了torch.nn
pi_net = nn.Sequential(
nn.Linear(obs_dim, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, act_dim)
)它构建了多层感知机(MLP),通过obs tensor 可以获取动作
obs_tensor = torch.as_tensor(obs, dtype=torch.float32)
actions = pi_net(obs_tensor)Stochastic polices
DRL中两种主要的随即策略是categorical polices(离散动作) 和 diagonal Gaussian polices(连续动作),以下两种计算对于随即策略是很重要的:
- 此policy进行动作采样
- 计算特定动作的对数似然,
下面分别描述categorical和diagonal Gaussian policies
Categorical polices
一个categorical policy就像是离散动作的分类器,为一个categorical policy构建神经网络与构建分类器一样,输入observation,经过隐藏层,最终的线性层为每一个动作提供logits,再通过softmax转换为概率
- sampling:
给定动作概率,可以使用Categorical distributions in PyTorch, torch.multinomial, tf.distributions.Categorical, or tf.multinomial.
- 计算对数似然
表示最后一层的概率 ,它是一个向量,无论有多少动作都有多少条目,所以我们可以将动作视为向量的索引。 然后可以通过对向量进行索引来获得动作 a 的对数似然。
Diagonal Gaussian Policies
多元高斯分布(或多元正态分布)由均值向量 和协方差矩阵
描述。 对角高斯分布是一种特殊情况,其中协方差矩阵仅在对角线上有数据。 因此,我们可以用一个向量来表示它。
对角线高斯策略总是有一个神经网络,从observation映射到动作的mean, 。 协方差矩阵通常有两种不同的表示方式
第一种
有一个对数标准差向量 ,他不是state的function ,
有独立的参数
第二种
有一个神经网络把states映射到对数标准差 ,它可以与mean网络共享同样的层。
请注意,在这两种情况下,我们都输出对数标准差而不是直接输出标准差。 这是因为 log stds 可以输出 中的任何值,而 stds 必须是非负的。
也就是说,一般而言,随机网络输出的最后一个节点是一个动作的均值,而如果动作是从高斯分布中采样,那么还有标准差需要被确定,一种方案就是这个
- sampling
给定均值 和标准差
,和一个高斯噪声向量z
,动作采样可以被计算为:
表示两个向量元素乘积,标准框架具有生成噪声向量的内置方法,例如 torch.normal 或 tf.random_normal。 或者,您可以构建分布对象,例如通过 torch.distributions.Normal 或 tf.distributions.Normal,并使用它们来生成样本。 (后一种方法的优点是这些对象还可以为您计算对数似然。)
- 对数似然
k维动作a的对数似然 标准差
,由下式给出:
Trajectories
trajectory 是状态动作的序列:
第一个状态s_0 是从初始状态分布随机采样得来的
状态转换是由环境得到的,当环境是确定性时:
或是随机的,以转移概率进行转换的
Reward and Return
reward function R, 定义为:
通常可以简化为: 或
agent的目标是最大化轨迹的累计reward,一种return是有限时间非折扣回报:
另一种是无限时间折扣回报,其中 :
使用折扣,一方面体现了越早的奖励最好,另一外面也会使总的奖励在无限时间域上收敛
The RL Problem
无论选择哪种return方式,或者选择哪种policy,RL目标都是为了最大化expected return,首先我们讨论一条轨迹的分布概率,考虑environment transitions 和 policy 都是随即的情况,T步轨迹的分布概率为:
expected return期望回报 用 来表示为:
RL优化问题表示为:
就是最优策略。
Value Functions
了解状态或状态-动作对的价值通常很有用。几乎所有 RL 算法都以某种方式使用值函数。
有四种主要的functions:
- The On-Policy Value Functions
如果从状态 s 开始并始终根据策略\pi 行动,则它会给出预期回报
- The On-Policy Action-Value Function
从状态 s 开始,执行任意操作 a(可能不是来自策略),然后永远按照策略操作,这将给出预期的回报:
- The Optimal Value Function
从状态s开始,总是以最优策略行动
- The Optimal Action-Value Function
从状态s开始,执行任意动作a, 后续根据最优策略行动
The Optimal Q-Function and the Optimal Action
最优action-value值函数 和最优策略选择的动作a之间有重要的联系,即:
注意:可能有多个动作使 最大化,在这种情况下,它们都是最优的,最优策略可能会随机选择其中的任何一个。 但是总是有一个最优策略可以确定性地选择一个动作。
Bellman Equations
所有四个值函数都遵循称为贝尔曼方程的特殊自洽方程。 贝尔曼方程背后的基本思想是:The value of your starting point is the reward you expect to get from being there, plus the value of wherever you land next.(当前点的价值是,你能从此处获得的期望奖励加上后续状态的价值)
贝尔曼最优函数方程
on-policy 值函数和最优值函数的 Bellman 方程之间的关键区别在于动作上的 max 是否存在。 它反映了这样一个事实,即每当代理选择其动作时,为了采取最佳行动,它必须选择导致最高值的动作。
术语bellman backup 备份一个状态 或是状态动作对,是贝尔曼方程的右边,即reward+next value
Advantage Functions
有时在 RL 中,我们不需要描述一个动作在绝对意义上有多好,而只需要描述它平均比其他动作好多少。 也就是说,我们想知道那个动作的相对优势。 我们通过优势函数使这个概念更加精确。
对应于策略 的优势函数
描述了在状态 s 中采取特定动作 a 比根据
选择一个动作的优劣程度,假设以后永远按照
行动。 在数学上,优势函数定义为
也就是说,当前某个动作的优势,就是保证后续使用了策略\pi的前提下,相对于平均动作的好坏,因为状态值函数本身也是对所有的动作后续奖励求期望,也代表了平均动作的价值。



评论(0)
您还未登录,请登录后发表或查看评论