

上一章我们搭建了Atari的强化学习环境,这一期我们来搭建MUJOCO强化学习环境
那么我们为什么要“多此一举”呢?
一、概述
MuJoCo和Atari对比
Atari:
- 类型:Atari游戏是一系列的经典视频游戏。
- 简单性:Atari游戏通常有相对简单的视觉和动作空间。例如,游戏”Breakout”中的动作可能仅限于将挡板向左或向右移动。
- 离散动作空间:Atari游戏中的动作通常是离散的(即非连续的),意味着在任何给定的时间点,代理(Agent)可以采取有限集合中的一个动作。
- 视觉处理:强化学习在Atari游戏中的应用往往涉及图像识别和处理,因为输入通常是以像素为基础的游戏画面。
- 研究重点:Atari环境在强化学习中常用来测试算法的能力,以在高度随机的环境中从视觉输入学习策略。
MuJoCo:
- 类型:MuJoCo是一种用于模拟连续动力学和接触机制的物理引擎。
- 复杂性:MuJoCo环境通常模拟机器人和其他动态系统,这些系统的动力学比Atari游戏要复杂得多。
- 连续动作空间:MuJoCo环境通常具有连续的动作空间,这意味着代理可以采取一系列连续值作为动作。
- 物理仿真:MuJoCo的强化学习应用更多地涉及到理解和控制物理动力学,如力、扭矩、关节角度等。
- 研究重点:在MuJoCo环境中,强化学习通常被用来解决控制和机器人学问题,如步行、跳跃或操纵物体。
Atari环境在强化学习中通常用于测试代理的决策和图像处理能力,而MuJoCo环境更多地用于测试代理处理复杂物理交互和连续控制的能力。Atari环境的问题通常是模式识别和反应时间的问题,而MuJoCo环境的问题则是控制论和动力学问题。两者提供了强化学习环境,为强化学习算法的研究提供了另一种不同的测试场景。
MuJoCo详细介绍
MuJoCo(Multi-Joint dynamics with Contact)是一个高度优化的物理引擎,它对连续动力学系统的仿真具有高效率和高精度,尤其擅长处理复杂的机械结构和接触动力学。MuJoCo广泛应用于机器人学、仿生学、生物力学和强化学习等领域。
游戏效果图:
MuJoCo的关键特性
- 快速且精确的仿真:MuJoCo设计了专门的算法,最小化数值误差,同时提供快速的仿真速度,这对于强化学习中的大量样本生成非常重要。
- 稳健的接触动力学:MuJoCo能够处理多体系统中的复杂接触场景,包括软硬接触、摩擦和碰撞。
- 基于物理的控制:对于需要精确控制力和扭矩的应用场景,MuJoCo提供了强大的物理基础。
- 灵活的模型定义:用户可以使用XML或其自有的MJCF(MuJoCo专用的XML格式)来定义复杂的机械模型。
- 优化和自动微分:MuJoCo支持自动微分,这对于机器学习中的梯度计算和模型参数优化非常有用。
强化学习训练案例
MuJoCo在强化学习领域的应用非常广泛,尤其是在控制任务和机器人学习中。以下是一些使用MuJoCo的强化学习训练案例和成果:
-
机器人步行:使用强化学习训练模拟的双足或四足机器人步行是MuJoCo的一个典型应用。例如,OpenAI通过MuJoCo训练了模型,使得机器人可以在不同的地形上行走。
-
操作任务:OpenAI的Dactyl机器人利用MuJoCo进行仿真,学习了如何使用其多关节手进行物体操作任务,如旋转一个玩具魔方。
-
人类动作模仿:研究人员利用MuJoCo仿真环境和强化学习算法训练代理模仿人类动作或进行体操动作。
-
复杂动作序列:DeepMind的Parkour项目中,使用MuJoCo模拟的代理学会了一系列复杂的动作,包括跳跃、翻滚和攀爬,以通过障碍课程。
-
多智能体协作:MuJoCo也被用于多智能体系统的研究,例如多个机器人协作搬运物体或进行足球比赛。
算法发展:
如TRPO(Trust Region Policy Optimization)、PPO(Proximal Policy Optimization)和DDPG(Deep Deterministic Policy Gradient)等现代强化学习算法在MuJoCo环境中得到了大量测试和改进。
环境安装
这里我们安装 mujoco>=2.2.0版本(2.0之前的版本安装比较复杂)
pip install mujoco
pip install gym
安装检验
import gym
env = gym.make('Hopper-v3')
obs = env.reset()
print(obs.shape) # (11, )
运行一下,显示以下界面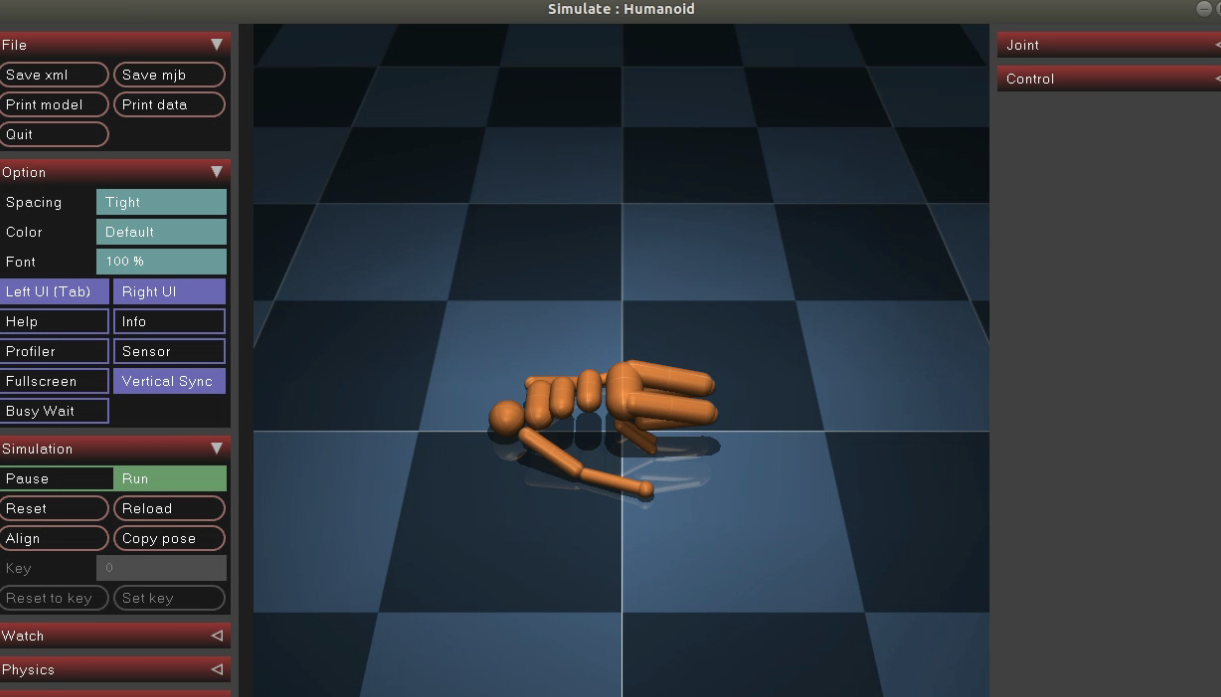
原始环境分析
在MuJoCo环境中,变换前的空间指的是仿真开始之前设定的初始环境状态。包括所有物体的初始位置、速度、加速度等物理属性,它们构成了观察空间、动作空间和奖励空间的基础。以下是详细说明:
观察空间(Observation Space)
- 物理信息向量:在观察空间中,智能体接收到的信息通常是一个由物理属性组成的向量,包括物体的3D位置、方向(使用欧拉角或四元数表示)、关节角度等。
- 向量尺寸:向量的具体尺寸
N是根据不同的环境而变化的。例如,在某个环境中,如果有三个关节,每个关节有位置、速度和扭矩传感器,那么向量的尺寸可能是9(3个关节 × 3种类型的传感器信息)。 - 数据类型:观察向量中的数据通常是
float64类型。
动作空间(Action Space)
- 物理信息向量:动作空间定义了智能体可以执行的动作,通常是由扭矩或力的大小组成的向量。
- 向量尺寸:动作空间的尺寸
N也是根据环境的具体情况来确定的。在Hopper环境中,N的大小为3,意味着智能体可以控制三个动作维度。 - 数据类型和范围:动作向量中的数据类型是
np.float32,代表着每一动作的精度。动作的取值范围通常在[-1, 1]之间,这意味着智能体可以对每个关节施加正向或反向的最大扭矩。
奖励空间(Reward Space)
- 游戏得分:奖励是一个浮点数值,表示智能体在当前步骤或者整个episode中的表现。奖励的设计与特定的任务目标相关
- 奖励计算:奖励通常基于智能体的表现来计算。对于Hopper来说,可能是保持平衡、移动速度、移动距离等因素
补充
- Episode结束:游戏结束即为当前环境 episode 结束
在所有这些空间中,变换前的空间或原始环境是智能体开始学习之前的初始状态。MuJoCo通过这些初始设定来模拟物理世界的动力学,而观察空间、动作空间和奖励空间则分别定义了智能体如何感知这个世界、如何在其中进行操作和如何评价自己的表现。
变换后的空间(RL 环境)
-
观察空间
基本无变换 -
动作空间
基本无变换,依然是大小为N的连续动作空间,取值范围[-1, 1],尺寸为(N, ),数据类型为np.float32 -
奖励空间
基本无变换
上述空间使用gym环境空间定义则可表示为:
import gym
obs_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(11, ), dtype=np.float64)
act_space = gym.spaces.Box(low=-1, high=1, shape=(3, ), dtype=np.float32)
rew_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(1, ), dtype=np.float32)
补充:
- 环境step方法返回的info必须包含eval_episode_return键值对,表示整个 episode 的评测指标,在 Mujoco 中为整个 episode 的奖励累加和
- 随机种子设定及训练和测试环境的区别同上一章
游戏录像保存
from easydict import EasyDict
from dizoo.mujoco.envs import MujocoEnv
env = MujocoEnv(EasyDict({'env_id': 'Hoopper-v3' }))
env.enable_save_replay(replay_path='./video')
obs = env.reset()
while True:
action = env.random_action()
timestep = env.step(action)
if timestep.done:
print('Episode is over, eval episode return is: {}'.format(timestep.info['eval_episode_return']))
break
训练代码示例
from easydict import EasyDict
hopper_sac_default_config = dict(
env=dict(
env_id='Hopper-v3',
norm_obs=dict(use_norm=False, ),
norm_reward=dict(use_norm=False, ),
collector_env_num=1,
evaluator_env_num=8,
use_act_scale=True,
n_evaluator_episode=8,
stop_value=6000,
),
policy=dict(
cuda=True,
on_policy=False,
random_collect_size=10000,
model=dict(
obs_shape=11,
action_shape=3,
twin_critic=True,
actor_head_type='reparameterization',
actor_head_hidden_size=256,
critic_head_hidden_size=256,
),
learn=dict(
update_per_collect=1,
batch_size=256,
learning_rate_q=1e-3,
learning_rate_policy=1e-3,
learning_rate_alpha=3e-4,
ignore_done=False,
target_theta=0.005,
discount_factor=0.99,
alpha=0.2,
reparameterization=True,
auto_alpha=False,
),
collect=dict(
n_sample=1,
unroll_len=1,
),
command=dict(),
eval=dict(),
other=dict(replay_buffer=dict(replay_buffer_size=1000000, ), ),
),
)
hopper_sac_default_config = EasyDict(hopper_sac_default_config)
main_config = hopper_sac_default_config
hopper_sac_default_create_config = dict(
env=dict(
type='mujoco',
import_names=['dizoo.mujoco.envs.mujoco_env'],
),
env_manager=dict(type='base'),
policy=dict(
type='sac',
import_names=['ding.policy.sac'],
),
replay_buffer=dict(type='naive', ),
)
hopper_sac_default_create_config = EasyDict(hopper_sac_default_create_config)
create_config = hopper_sac_default_create_config
if __name__ == '__main__':
from ding.entry import serial_pipeline
serial_pipeline((main_config, create_config), seed=0)
代码分析
这段代码是一个基于Soft Actor-Critic (SAC)算法的强化学习实验,目标是训练一个智能体在MuJoCo模拟环境中的Hopper-v3任务上进行学习。
首先,通过easydict库,将参数字典转换为一个可以通过属性访问其键的对象,这样可以更方便地访问配置字典中的参数。
from easydict import EasyDict
下面是hopper_sac_default_config字典,它定义了实验的主要配置:
hopper_sac_default_config = dict(
# ...
)
hopper_sac_default_config = EasyDict(hopper_sac_default_config)
main_config = hopper_sac_default_config
在这个配置字典中包含了环境设置、策略配置、学习过程、数据收集和其他必要的设置。这里是一些关键的配置项:
env_id: 使用的环境ID,这里是’Mujoco’的’Hopper-v3’。collector_env_num: 用于收集数据的环境数量。evaluator_env_num: 用于评估策略性能的环境数量。n_evaluator_episode: 每次评估时运行的episode数量。stop_value: 训练停止的性能阈值。cuda: 是否使用CUDA加速。on_policy: 是否使用on-policy算法。random_collect_size: 随机收集的样本数量用于初始化回放缓冲区。model: 定义智能体模型的参数,如观测形状、动作形状、是否使用双重评论家网络等。learn: 定义学习过程中的参数,如批处理大小、学习率、折扣因子等。replay_buffer: 定义重放缓冲区的大小。
接下来是hopper_sac_default_create_config字典,它定义了创建环境和策略所需的组件和相关的导入路径:
hopper_sac_default_create_config = dict(
# ...
)
hopper_sac_default_create_config = EasyDict(hopper_sac_default_create_config)
create_config = hopper_sac_default_create_config
hopper_sac_default_create_config涉及到环境的类型、管理器、策略的类型以及重放缓冲区的类型。
最后,如果这个脚本作为主程序运行:
if __name__ == '__main__':
from ding.entry import serial_pipeline
serial_pipeline((main_config, create_config), seed=0)
这里导入serial_pipeline函数,该函数是启动训练流程的入口点。函数接受之前定义的配置对象main_config和create_config,以及一个随机种子seed,它决定了一些随机过程的初始状态,以确保实验的可复现性。
在整体上,这段代码的目的是通过一个序列化的训练流程,使用SAC算法来训练一个在Hopper-v3任务上表现良好的智能体。SAC算法是一种强化学习算法,它通过最大化一个熵正则化的策略目标函数来工作,以此来鼓励探索,并且可以在连续动作空间中学习稳定的策略。
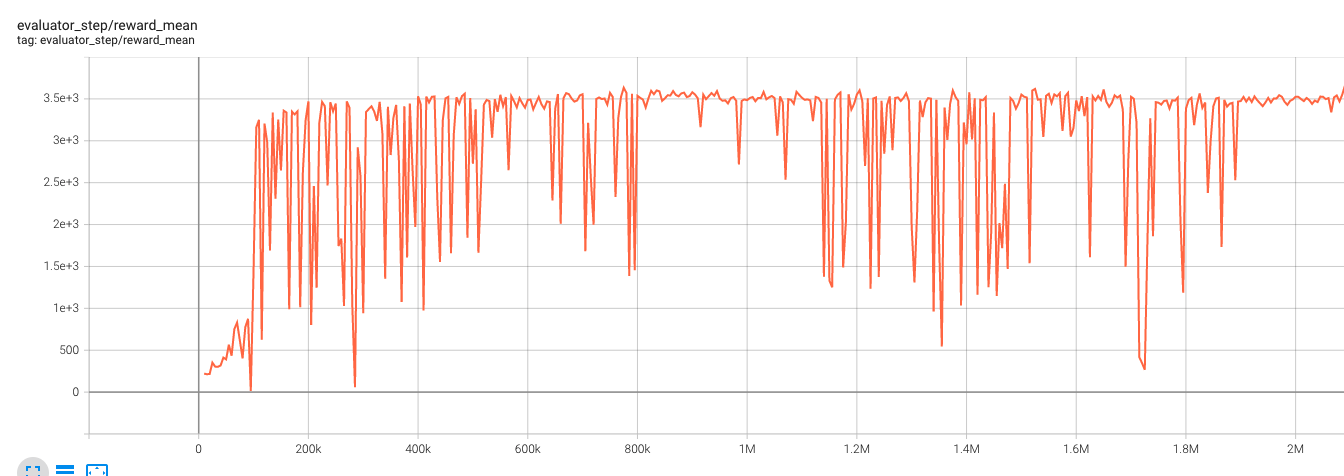
基准算法性能参考图



评论(0)
您还未登录,请登录后发表或查看评论