

CUDA编程,从某种意义而言,可以划分为异构系统编程,其实是一个CPU+GPU模式。其中,CPU被称为Host,而GPU被称为Device。
#include <cuda_runtime.h>
#include <stdio.h>
int main(int argc,char** argv)
{
int deviceCount = 0;
cudaError_t error_id = cudaGetDeviceCount(&deviceCount);
if(error_id!=cudaSuccess)
{
printf("cudaGetDeviceCount returned %d\n ->%s\n",
(int)error_id,cudaGetErrorString(error_id));
printf("Result = FAIL\n");
exit(EXIT_FAILURE);
}
if(deviceCount==0)
{
printf("There are no available device(s) that support CUDA\n");
}
else
{
printf("Detected %d CUDA Capable device(s)\n",deviceCount);
}
int dev=0, driverVersion=0, runtimeVersion=0;
cudaSetDevice(dev);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp,dev);
printf("Device %d:\"%s\"\n",dev,deviceProp.name);
cudaDriverGetVersion(&driverVersion);
cudaRuntimeGetVersion(&runtimeVersion);
printf(" CUDA Driver Version / Runtime Version %d.%d / %d.%d\n",
driverVersion/1000,(driverVersion%100)/10,
runtimeVersion/1000,(runtimeVersion%100)/10);
printf(" CUDA Capability Major/Minor version number: %d.%d\n",
deviceProp.major,deviceProp.minor);
printf(" Total amount of global memory: %.2f GBytes (%llu bytes)\n",
(float)deviceProp.totalGlobalMem/pow(1024.0,3),deviceProp.totalGlobalMem);
printf(" GPU Clock rate: %.0f MHz (%0.2f GHz)\n",
deviceProp.clockRate*1e-3f,deviceProp.clockRate*1e-6f);
printf(" Memory Bus width: %d-bits\n",
deviceProp.memoryBusWidth);
if (deviceProp.l2CacheSize)
{
printf(" L2 Cache Size: %d bytes\n",
deviceProp.l2CacheSize);
}
printf(" Max Texture Dimension Size (x,y,z) 1D=(%d),2D=(%d,%d),3D=(%d,%d,%d)\n",
deviceProp.maxTexture1D,deviceProp.maxTexture2D[0],deviceProp.maxTexture2D[1]
,deviceProp.maxTexture3D[0],deviceProp.maxTexture3D[1],deviceProp.maxTexture3D[2]);
printf(" Max Layered Texture Size (dim) x layers 1D=(%d) x %d,2D=(%d,%d) x %d\n",
deviceProp.maxTexture1DLayered[0],deviceProp.maxTexture1DLayered[1],
deviceProp.maxTexture2DLayered[0],deviceProp.maxTexture2DLayered[1],
deviceProp.maxTexture2DLayered[2]);
printf(" Total amount of constant memory %lu bytes\n",
deviceProp.totalConstMem);
printf(" Total amount of shared memory per block: %lu bytes\n",
deviceProp.sharedMemPerBlock);
printf(" Total number of registers available per block:%d\n",
deviceProp.regsPerBlock);
printf(" Wrap size: %d\n",deviceProp.warpSize);
printf(" Maximun number of thread per multiprocesser: %d\n",
deviceProp.maxThreadsPerMultiProcessor);
printf(" Maximun number of thread per block: %d\n",
deviceProp.maxThreadsPerBlock);
printf(" Maximun size of each dimension of a block: %d x %d x %d\n",
deviceProp.maxThreadsDim[0],deviceProp.maxThreadsDim[1],deviceProp.maxThreadsDim[2]);
printf(" Maximun size of each dimension of a grid: %d x %d x %d\n",
deviceProp.maxGridSize[0],
deviceProp.maxGridSize[1],
deviceProp.maxGridSize[2]);
printf(" Maximu memory pitch %lu bytes\n",deviceProp.memPitch);
printf("----------------------------------------------------------\n");
printf("Number of multiprocessors: %d\n", deviceProp.multiProcessorCount);
printf("Total amount of constant memory: %4.2f KB\n",
deviceProp.totalConstMem/1024.0);
printf("Total amount of shared memory per block: %4.2f KB\n",
deviceProp.sharedMemPerBlock/1024.0);
printf("Total number of registers available per block: %d\n",
deviceProp.regsPerBlock);
printf("Warp size %d\n", deviceProp.warpSize);
printf("Maximum number of threads per block: %d\n",
deviceProp.maxThreadsPerBlock);
printf("Maximum number of threads per multiprocessor: %d\n",
deviceProp.maxThreadsPerMultiProcessor);
printf("Maximum number of warps per multiprocessor: %d\n",
deviceProp.maxThreadsPerMultiProcessor/32);
return EXIT_SUCCESS;
}
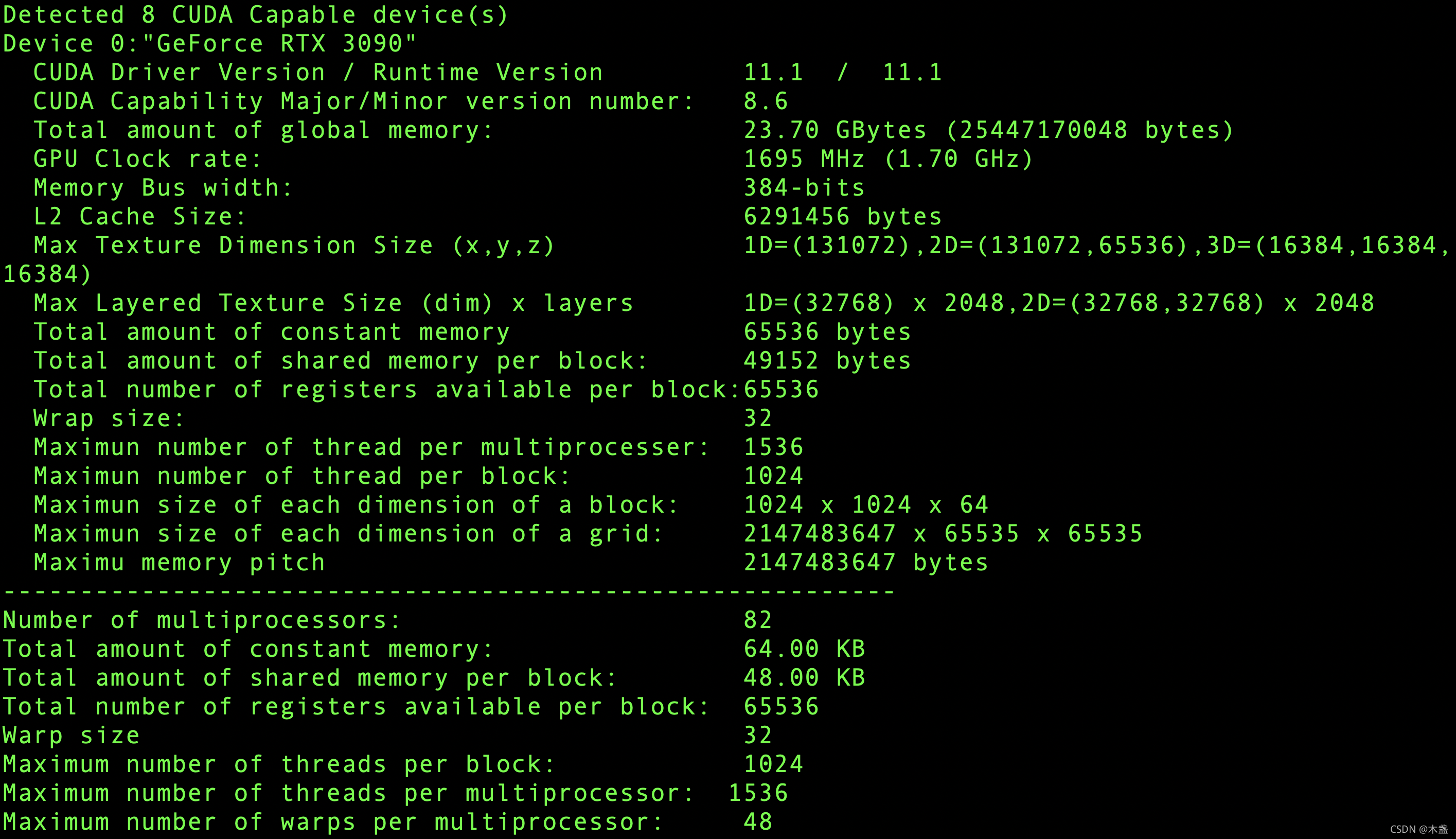
将上述代码保存为device_info.cu,然后编译运行:
nvcc -o device_info device_info.cu
./device_info
输出为:
")


评论(0)
您还未登录,请登录后发表或查看评论