@[toc]
1. POMDP用途
常用的简称:
- Markov decision processes (MDP)
- partially observable Markov decision processes (POMDPs)
2. POMDP简介
当面对一个决定时,你可以有许多不同的选择(动作)。通常每做出一个选择(动作),就有相对应的效果(奖励/收益)。这个奖励可以是长期的,也可以是短期的,这里做下区分:
- 即时收益:当前的收益,做完选择(动作)后,立即可以看到的效果,因此即时收益是直观、透明的;
- 长期收益:未来的收益,可能现在看不太出来所做的选择有什么用途,但是经过一段时间后可以看出来效果,因此长期收益不是那么直观,也不透明;
那到底应该关注即使收益还是长期收益那,这个还是要根据模型的情况来定?有时,即时收益较差的操作可能会产生更好的长期收益。因此可以在立即收益和未来收益之间进行权衡,以便做出更好的选择。但是按照各种论文和个人经验来说,通常还是比较在意即时收益。因为关于未来存在很多不确定性,将来某些动作的结果并不完全可预测,有时甚至不知道将来的行动是否会变得重要。
其实和人生也差不多,过好现在就行,想太多并不见得是件好事,且行且珍惜。
马尔可夫决策过程是对问题建模的一种方法,可以在不确定的环境中自动执行决策过程,选择合适的动作来最大化收益。在机器人或者其他领域中,如果可以将问题建模为MDP,那么可以使用多种算法来求解决策问题。
3. MDP模型
在讲解POMDP之前,先介绍下最基本的、最经典的MDP。
假设状态和动作的集合是离散的,MDP模型的四个组成部分是:一组状态(states),一组动作(actions),这些动作的后果(可以理解为选择了某个动作后,会从当前状态转移到下一时刻的状态,Transitions)以及这些动作的即时收益(value)。
\bullet 状态(states)
从世界角度来看,状态是机器人在世界环境中存在的状态;从机器人角度来看,状态就是自己所处的环境。做出决定时,您需要考虑自己的行为将如何影响事物。状态是当前世界的存在方式,而行为将具有改变世界状态的效果。如果我们考虑所有可能的状态,那么这就是世界状态的集合。这些状态中的每个状态都是MDP中的状态。
\bullet 动作(actions)
一系列可以选择的动作组成的集合,eg:运动方向{前,后,左,右},也可以是速度大小{1m/s,2m/s…km/s}等。解决MDP的主要问题就是找到在世界每个特定状态下找到最佳的动作。
\bullet 状态转移函数(Transitions)
当选择不同的动作时,会导致从当前状态转移到下一个状态。例如,机器人开始在是位置
s_1(0,0),选择动作向右移动一步a1(1,0),随后到达位置s2(1,0),这个转换过程就是T。
MDP最强大的方面是,动作的效果可能是概率性的。假设我们要指定在状态“s1”中执行操作“a1”的效果。如果没有关于“a1”如何改变世界的疑问,我们可以说“a1”的作用是使进程处于状态“s2”。但是,许多决策过程的动作并非如此简单。有时,一个动作通常会导致状态为“s2”,但偶尔也可能会导致状态为“s3”。 MDP通过允许您指定一组结果状态以及每个状态产生的概率,可以指定这些更复杂的操作。
\bullet 收益(value)
如果我们要使决策过程自动化,那么我们必须能够对一项行动的成本或状态价值进行某种程度的衡量,以便我们可以长期比较不同的替代行动政策。我们为在每个状态下执行每个动作指定一些立即值。
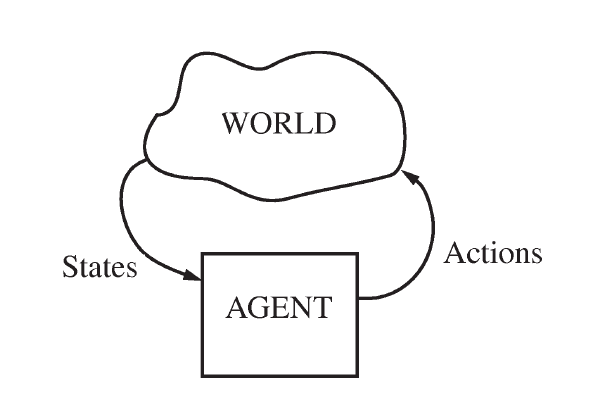
这几个概念之间的关系如上图所示,机器人(AGENT)根据所处环境(WORLD)的状态(States)选择合适的动作(Actions),而机器人所作的动作又会影响环境,这就形成了一个闭环,两者不断的相互影响着。在MDP框架中,虽然agent的行为的影响有很大的不确定性,但是对于agent的当前状态没有任何不确定性,因为agent具有完整和完美的感知能力。
4. 求解MDP
MDP的解决方案称为策略,它仅指定针对每个州采取的最佳措施。就本教程而言,我们将只考虑在假设寿命有限的情况下寻找最佳策略的问题。例如,假设我们每天醒来都必须对某件事做出决定。我们要做出决定的前提是我们只需要在固定的天数内做出决定。这种类型的解决方案称为有限范围解决方案,而我们将要做出决策的天数称为范围长度。
尽管我们遵循的是政策,但实际上我们将计算一个价值函数。无需赘述,只要我们具有价值功能就可以轻松推导该政策。因此,我们将重点放在寻找这个价值函数上。值函数与策略类似,不同之处在于,它为每个状态指定一个数值,而不是为每个状态指定一个动作。
拓展
可能很多朋友想问:马尔可夫家伙是谁?
这个人的身份现在并不重要,但在这里我们尝试解释就MDP而言,他的名字的含义。
当我们谈论模型的转换时,我们说过,我们只需要为每个开始状态和动作指定结果的下一个状态。假设下一个状态仅取决于当前状态(和操作)。在某些情况下,动作的效果可能不仅取决于当前状态,还取决于最近的几个状态。 MDP模型将不允许您直接为这些情况建模。 MDP模型做出的假设是,下一个状态仅由当前状态(和当前动作)确定。这称为马尔可夫假设。
我们可以说过程的动力学是马尔可夫式的,这对于解决问题具有重要的影响。最重要的是,我们的政策或价值功能可以采用简单的形式。结果是我们可以仅根据当前状态来选择我们的操作。




评论(1)
您还未登录,请登录后发表或查看评论