

1.池化层的解释
池化层的输入一般来源于上一个卷积层,主要作用是提供了很强的鲁棒性(例如max-pooling是取一小块区域中的最大值,此时若此区域中的其他值略有变化,或者图像稍有平移,pooling后的结果仍不变),并且减少了参数的数量,防止过拟合现象的发生。池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新。1
2.池化层的前向传播
前向计算过程中,我们对卷积层输出map的每个不重叠(有时也可以使用重叠的区域进行池化)的n*n区域(我这里为3*3,其他大小的pooling过程类似)进行降采样,选取每个区域中的最大值(max-pooling)或是平均值(mean-pooling),也有最小值的降采样,计算过程和最大值的计算类似。
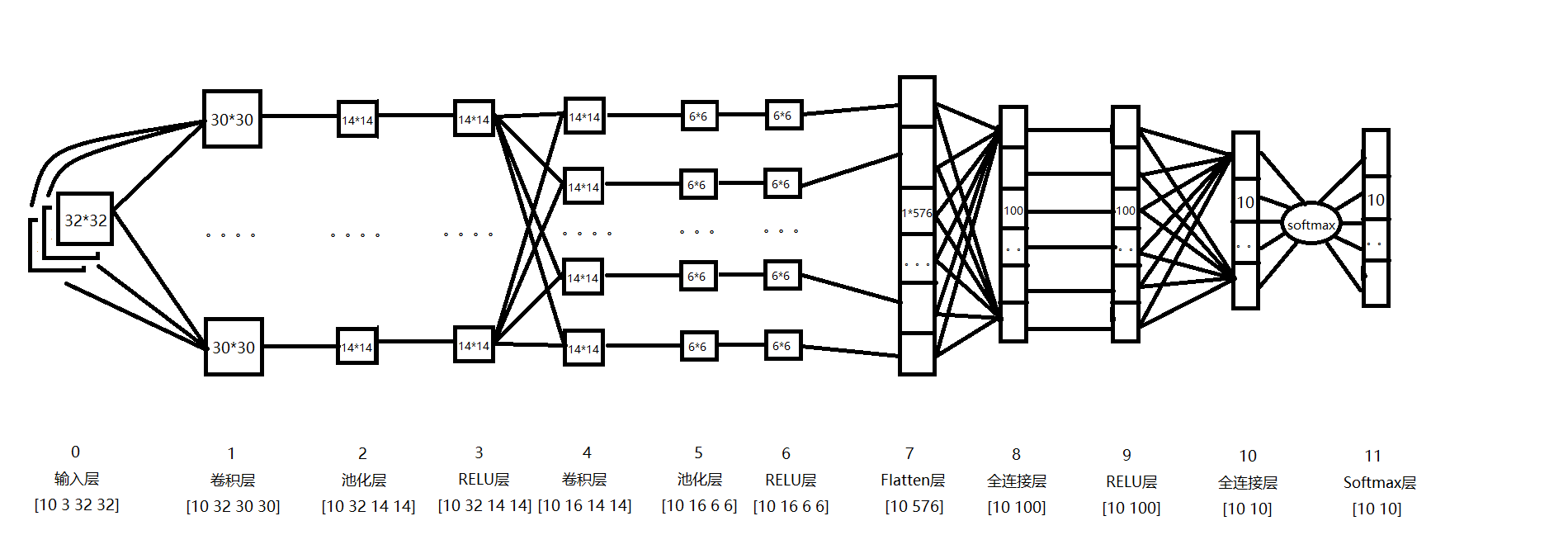
上图中,池化层5的输入为卷积层4的输出,大小为14*14,对每个不重叠的3*3的区域进行降采样。对于max-pooling,选出每个区域中的最大值作为输出。而对于mean-pooling,需计算每个区域的平均值作为输出。最终,根据池化公式:该层输出一个6*6的map。池化层2的计算过程也类似。
2.1 前向传播池化层的输出map大小计算公式
由于池化是降采样,所以池化改变的是输出map的大小,而不改变输出channel的大小。下面是池化层输出map的长H_out和宽W_out的计算公式:
2.2 池化的两种方法:Maxpooling 和 Meanpooling


3 池化层的反向计算
在池化层进行反向传播时,max-pooling和mean-pooling的方式也采用不同的方式。
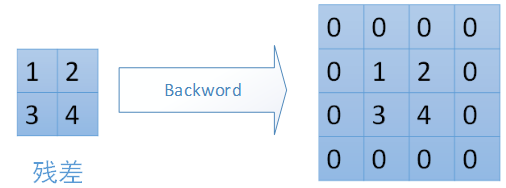
对于max-pooling,在前向计算时,是选取的每个2*2区域中的最大值,这里需要记录下最大值在每个小区域中的位置。在反向传播时,只有那个最大值对下一层有贡献,所以将残差传递到该最大值的位置,区域内其他2*2-1=3个位置置零。具体过程如下图,其中4*4矩阵中非零的位置即为前边计算出来的每个小区域的最大值的位置。
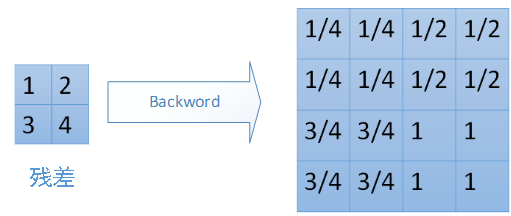
对于 mean-pooling,我们需要把残差平均分成2*2=4份,传递到前边小区域的4个单元即可。具体过程如图:
4 代码
正向传播(正向传播子函数)
def forward(self, in_data):
self.bottom_val = in_data
N, C, H, W = in_data.shape
HH, WW, stride = self.kernel_size, self.kernel_size, self.stride #HH和WW均为kernel_size
H_out = int((H - HH) / stride + 1) #计算纵向需要滑几步
W_out = int((W - WW) / stride + 1) #计算横向需要滑几步
out = np.zeros((N, C, H_out, W_out))
for i in range(H_out):
for j in range(W_out):
x_masked = in_data[:, :, i * stride: i * stride + HH, j * stride: j * stride + WW]
out[:, :, i, j] = np.max(x_masked, axis=(2, 3))
return out反向传播(逐行分解,剖析反向传播过程)
import numpy as np
bottom_data_7 = np.load('./data_pic/con2[10-16-14-14].npy')
print ("Maxpooling层的bottom_data的shape是:")
print (bottom_data_7.shape)
x_masked = bottom_data_7[:, :, 0: 3, 0: 3]
print ("\nbottom_data的第一个batch的第一个3X3区域的数是:")
print (x_masked.shape)
print (x_masked[0][0])
max_x_masked = np.max(x_masked, axis=(2, 3))
print ("\nbottom_data的第一个batch的第一个3X3区域最大的数是:")
print (max_x_masked.shape)
print ((max_x_masked)[:, :, None, None][0][0])
temp_binary_mask = (x_masked == (max_x_masked)[:, :, None, None])
print ("\nbottom_data的第一个batch的第一个3X3区域最大的数在本区域中的位置(true):")
print (temp_binary_mask[0][0])
residual_6_relu = np.load("./data_pic/residual_6_relu[10 16 6 6].npy")
dx = np.zeros_like(residual_6_relu)
print ("\n下层传过来的残差residual的shape是:")
print (residual_6_relu.shape)
print ("\n下层传过来的残差residual的第一个batch的第一个通道的第一个diff是:")
print (residual_6_relu[0, 0, 0,0])
dx[:, :, 0: 3, 0: 3] += temp_binary_mask * (residual_6_relu[:, :, 0,0])[:, :,None, None]
print ("\n将残差传正向传播时取的在3X3区域内的最大数的位置:")
print (dx[0][0][0])输出:
Maxpooling层的bottom_data的shape是:
(10, 16, 14, 14)
bottom_data的第一个batch的第一个3X3区域的数是:
(10, 16, 3, 3)
[[ 5241.0743993 12349.96024235 12688.05480956]
[ 5107.94168207 7228.75050703 8462.73752744]
[ 2468.53560093 5849.12001444 7523.96554065]]
bottom_data的第一个batch的第一个3X3区域最大的数是:
(10, 16)
[[ 12688.05480956]]
bottom_data的第一个batch的第一个3X3区域最大的数在本区域中的位置(true):
[[False False True]
[False False False]
[False False False]]
下层传过来的残差residual的shape是:
(10, 16, 6, 6)
下层传过来的残差residual的第一个batch的第一个通道的第一个diff是:
-1.4552119186e-08
将残差传正向传播时取的在3X3区域内的最大数的位置:
[ 0.00000000e+00 0.00000000e+00 -1.45521192e-08 0.00000000e+00
0.00000000e+00 0.00000000e+00]


评论(0)
您还未登录,请登录后发表或查看评论