

1 简介
大部分视觉定位与建图(SLAM)算法假设环境中的物体是静态或者低运动的,对应用环境有严格的限制,这种假设影响了视觉SLAM系统在实际场景中的适用性,当环境中存在动态物体时,例如走动的人,反复开关的门窗等,都会给系统带来错误的观测数据,降低系统的精度和鲁棒性。因此,为了提高系统在动态环境下的性能,需要对动态区域经行检测与处理。
2018年发表在ROBOTICS AND AUTOMATION LETTERS并开源的Dyna-SLAM是一个经典的动态视觉SLAM系统,其以ORB-SLAM2系统为基础,利用实例分割和多视图几何的方法提取动态区域并提出,有效的提升了原系统在动态环境下的性能,后续很多硕士学位论文和中文核心期刊都是基于Dyna-SLAM进行研究的。具体的,使用深学习方法(Mask R-CNN网络进行实例分割)检测潜在运动的物体,利用多视图几何的方法检测动态的特征点,进一步通过区域生长法得到动态区域,二者均有弊端,融合后便可以检测出那些运动的没有先验知识的物体(例如,被人推动的椅子,拿着的书本)。最后只使用静态区域ORB特征点进行相机位姿估计。
论文:DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
代码:https://github.com/BertaBescos/DynaSLAM

2 原理:
对于双目和单目相机,首先利用神经网络Mask R-CNN进行像素级别的实例分割,得到潜在的运动物体(人、汽车等,代码里面其实就是人),然后直接将该区域视为动态区域进行剔除,用余下区域的特征点进行跟踪与建图。最后进行背景修复,将相邻关键帧的图像投影到当前关键帧的动态区域上进行修补。
对于RGB-D相机,利用神经网络Mask R-CNN进行像素级别的实例分割,得到潜在的运动物体;然后将该区域的特征点去除,进行Low-Cost Tracking,得到初始位姿;在此初始位姿的基础上,由多视图几何的方法找到动态的特征点,然后通过在深度图上进行区域增长法得到动态区域;之后两种方法融合得到最终的动态区域,将静态区域的Mask传送给ORB-SLAM进行位姿计算和稀疏点云地图构建;最后对将相邻关键帧的图像投影到当前关键帧的动态区域,进行背景修补。
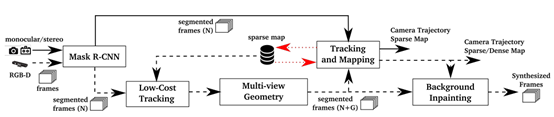
具体的内容如下:
2.1 用CNN分割潜在动态物体
为了检测动态物体,Dyna-SLAM使用Mask R-CNN(2018年提出)获得逐像素的图片语义分割。该想法是分割那些潜在动态或者可能运动的物体(人,自行车,汽车,摩托车,飞机,公交车,火车,货车,船,鸟,猫,狗,马,船,奶牛,大象,熊,斑马和长颈鹿)在实际开源代码中,Dyna-SLAM只是提取到了人的区域,而且并没有将每个人单独区分开来。使用MS COCO数据集训练网络,网上有训练好的模型可以直接使用。
2.2 低成本跟踪(Low-Cost Tracking)
Low-Cost Tracking是指,去除“潜在动态物体”上的特征点之后,用其余的特征点进行跟踪计算相机位姿。实际上Low-Cost Tracking实现过程与ORB-SLAM计算帧间位姿的方法完全相同,或者说就是对ORB-SLAM源码中的Track()函数作为一些调整,具体实现过程会在接下来的博文中介绍。
2.3 分割动态成分使用Mask-RCNN和多视图几何
通过使用Mask R-CNN,大多数动态物体可以被分割并且不被用于跟踪和建图。但是,有一些物体不能被该方法检测到,因为它们不是先验动态的,但是可移动。最典型的例子是某人拿着一本书,一个人坐在椅子上移动,或者甚至是家具在长期建图中的变化。所以需要通过进一步通过多视图几何的方法检测外点,对之前结果进行纠正。
具体的,Dyna-SLAM提出了一种通过多视图几何区分动态特征点的方法,首先找到与当前帧重叠的5个关键帧,同时考虑当前帧与每个关键帧之间的距离和旋转来,来考量该特征点是否属于动态区域。具体细节可参考博文https://zhuanlan.zhihu.com/p/133212711。在得到动态的特征点后,在深度图上以动态特征点作为种子,通过区域增长法蔓延得到动态区域。
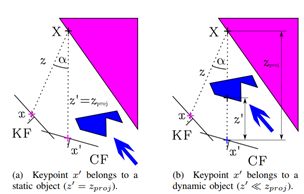
多视图几何的方法由于需要用到多帧图像,初始化比较困难,而且其检测有时检测不到所有的动态物体,如图a中远处的人;CNN只能检测先验特定的物体,对于人手中的书和移动的椅子是检测不到的。将二者融合起来便可以很好的检测到场景中所有的动态物体,如图c所示。在具体实现时,Dyna-SLAM直接将二者的并集去掉了。

2.4 跟踪和建图
由动态区域的Mask筛选得到静态区域的特征点,进而进行跟踪和建图,此过程与ORB-SLAM完全相同。
2.5 背景填充
由于动态物体的存在,图片上会出现孔洞,这对于一些应用场景是不被允许的,比如VR,AR,除此之外,其还会影响重定位和回环检测功能。为此Dyna-SLAM对每帧图像都进行了背景填充。具体的,维护一个大小为20的关键帧的数据库,将关键帧每个像素投影至当前帧的动态区域进行填充。值得注意的是,背景填充并不能保证每个区域都填充完全,当当前点没有出现在关键帧中时,其对应的像素不会被填充上去。当相机位姿计算不准确时,填充效果也会大打折扣。

3 实验结果分析:
3.1 精度性能分析:
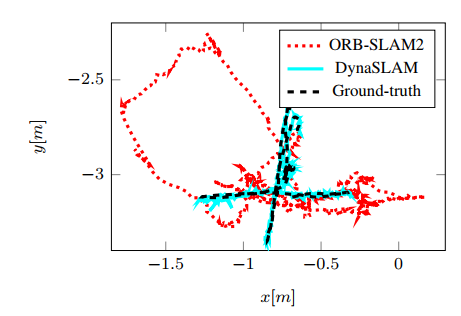
进行了多组对比实验,包括使用单独多视图几何、单独使用CNN以及同时使用二者的对比实验,在TUM、KITTI数据集上Dyna-SLAM与ORB-SLAM的对比实验。实验结果表明在动态环境下Dyna-SLAM的定位精度有了很大提升。
但是由于动态区域的去除会使得特征点的数目大大减少,所以在静态环境下以及低动态环境下Dyna-SLAM的性能未必超过ORB-SLAM,所以原论文在TUM数据集上只测试了两组低动态的数据集,而且并不是每组表现都特别好。
3.2 时间性能分析
需要注意的是,DynaSLAM在Gpu加速的情况下仍然不能达到实时性,可以看到,多视图几何部分消耗了大量时间约300ms,背景修复部分约消耗200ms,此外,在Nvidia Tesla M40 GPU加速的情况下,Mask R-CNN处理每张图片也需要200ms左右。
3.3 思考
为了提高系统运行的速度,可以考虑从以下几个方面改进:1.参考DS-SALM四线程的思想,将Mask R-CNN的处理过程放到单独的线程进行处理2.背景修复不是必须的过程,对定位的精度并不产生影响,可以直接去掉,或者只将特征点投影进来以帮助回环检测3. 可以采用更高效的多视图几何方法检测动态特征点。



评论(0)
您还未登录,请登录后发表或查看评论