

pybullet进行UR5机械臂环境的搭建,搭建的环境一般用于强化学习训练,这里采用gym框架结构。也就是需要有env.step,env.reset等。接下来我将分块介绍每个部分的内容。
env.reset
这个部分实现的功能就是在每次训练开始的时候初始化环境以及类的成员变量。第一块主要是导入pybullet的环境设置,第二部分首先设置一个离目标点差不多远的位置,第三部分我设置了一个随机落点的函数,用于训练时随机化初始位置,第四部分初始化力传感器,并将数值转换到末端坐标系下,第五部分为初始化状态。
def reset(self):
p.resetSimulation()
p.configureDebugVisualizer(p.COV_ENABLE_RENDERING,0)
p.setGravity(0,0,0)
p.setAdditionalSearchPath(pybullet_data.getDataPath())
p.loadURDF("plane.urdf",basePosition=[0,0,-0.65])
self.UR5=p.loadURDF("ur5_robot_long.urdf",useFixedBase=True)
orientation = p.getQuaternionFromEuler([math.pi / 2., -math.pi, 0])
self.hole = p.loadURDF("127.SLDPRT/urdf/7.SLDPRT.urdf",basePosition=[0.355,0,0],baseOrientation=orientation,useFixedBase=True)
p.loadURDF("table/table.urdf",basePosition=[0.5, 0, -0.65])
rest_poses = [-0.3126234800457983, -1.7637849264515224, 2.359807527441387, -2.166797511227157, -1.5707963265831946, -1.883423206411051]
for i in range(6):
p.resetJointState(self.UR5,i+1,rest_poses[i])
p.stepSimulation()
init_pos = self.random_position()
init_pusture = p.getQuaternionFromEuler([-math.pi / 2., 0.0,0.0])
jointPoses = p.calculateInverseKinematics(self.UR5, 6, init_pos, init_pusture,maxNumIterations = 100)
for i in range(6):
p.resetJointState(self.UR5, i + 1, jointPoses[i])
p.stepSimulation()
p.enableJointForceTorqueSensor(self.UR5, 7)
tmp = p.getQuaternionFromEuler([0., 0.0,math.pi / 2.])
self.rotate = np.array(p.getMatrixFromQuaternion(tmp),dtype=float).reshape(3,3)
p.stepSimulation()
self.force_init = np.array(p.getJointState(self.UR5,7)[2][0:3],dtype=float).reshape(3,1)
self.force_past = np.dot(self.rotate,self.force_init)
p.configureDebugVisualizer(p.COV_ENABLE_RENDERING,1)
observation = []
for i in range(PARAMS['seq_state']):
observation.append([0.0,0.0,0.0])
self.observation_seq = observation
return np.array(observation,dtype=float)env.fixed_reset
这个函数的功能主要在第二部分,因为训练时我们是随机取初始点开始,但是测试的时候,我们期望能够用固定的几个点测试,因此在进入测试函数时,我们的初始化函数将会被换成这个,用来测试。
def fixed_reset(self,number):
p.resetSimulation()
p.configureDebugVisualizer(p.COV_ENABLE_RENDERING, 0)
p.setGravity(0,0,0)
p.setAdditionalSearchPath(pybullet_data.getDataPath())
p.loadURDF("plane.urdf",basePosition=[0,0,-0.65])
self.UR5=p.loadURDF("ur5_robot_long.urdf",useFixedBase=True)
orientation = p.getQuaternionFromEuler([math.pi / 2., -math.pi, 0])
self.hole = p.loadURDF("127.SLDPRT/urdf/7.SLDPRT.urdf",basePosition=[0.355,0,0],baseOrientation=orientation,useFixedBase=True)
p.loadURDF("table/table.urdf",basePosition=[0.5, 0, -0.65])
rest_poses = self.reset_place[number]
for i in range(6):
p.resetJointState(self.UR5, i + 1, rest_poses[i])
p.stepSimulation()
self.x = init_pos[0]
self.y = init_pos[1]
self.z = init_pos[2]
p.enableJointForceTorqueSensor(self.UR5, 7)
tmp = p.getQuaternionFromEuler([0., 0.0, math.pi / 2.])
self.rotate = np.array(p.getMatrixFromQuaternion(tmp),dtype=float).reshape(3, 3)
p.stepSimulation()
self.force_init = np.array(p.getJointState(self.UR5, 7)[2][0:3],dtype=float).reshape(3, 1)
self.force_past = np.dot(self.rotate, self.force_init)
p.configureDebugVisualizer(p.COV_ENABLE_RENDERING, 1)
observation = []
for i in range(PARAMS['seq_state']):
observation.append([0.0,0.0,0.0])
self.observation_seq = observation
return np.array(observation,dtype=float)env.step()
这个函数接受强化学习模型输出的动作,进而更新下一步的位置newPosition,姿态这里是固定的,为垂直方向的四元数。第二部分用来进行实际的控制,当需要有环境噪声的时候,会从均匀分布中采样时间间隔,生成动作的随机噪声。第三部分用来得到接触力,并得到奖励,最后得到观测对应的状态表示,然后返回。
def step(self,action):
p.configureDebugVisualizer(p.COV_ENABLE_SINGLE_STEP_RENDERING)
currentPose=p.getLinkState(self.UR5,6)
newPosition=np.array(currentPose[4],dtype=float)
dx = action[0]*0.00004
dy = action[1]*0.00004
dz = -0.00001
self.x = self.x+dx
self.y = self.y+dy
self.z = self.z+dz
newPosition[0] = self.x
newPosition[1] = self.y
newPosition[2] = self.z
newPosture = p.getQuaternionFromEuler([-math.pi / 2., 0.0,0])
if self.U_num==0:
self.U_num = random.randint(1,10)
if self.random:
newPosition = self.random_env(newPosition)
jointPoses = p.calculateInverseKinematics(self.UR5, 6, newPosition, newPosture,maxNumIterations = 100)
p.setJointMotorControlArray(self.UR5,list([1,2,3,4,5,6]),p.POSITION_CONTROL,list(jointPoses))
else:
self.U_num = self.U_num-1
jointPoses = p.calculateInverseKinematics(self.UR5, 6, newPosition, newPosture,maxNumIterations = 100)
p.setJointMotorControlArray(self.UR5,list([1,2,3,4,5,6]),p.POSITION_CONTROL,list(jointPoses))
p.stepSimulation()
self.force_init = np.array(p.getJointState(self.UR5,7)[2][0:3],dtype=float).reshape(3,1)
self.force_now = np.dot(self.rotate,self.force_init)
force_change = abs(self.force_now)-abs(self.force_past)
self.force_past = self.force_now
reward,done = self.reward_function(force_change)
observation = self.state()
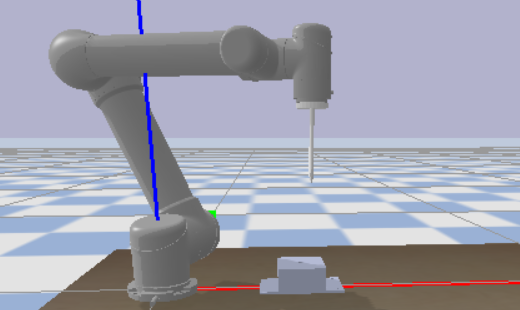
return np.array(observation,dtype=float),reward,done,done最终的图如下所示:
文章所有源代码和文件有需要的话可以跟我私聊,后面会进行开源,请多多关注。




评论(45)
您还未登录,请登录后发表或查看评论