

作者:穆士凝魂
链接:https://www.zhihu.com/question/337513515/answer/1561906368
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。






链接:https://www.zhihu.com/question/337513515/answer/1561906368
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
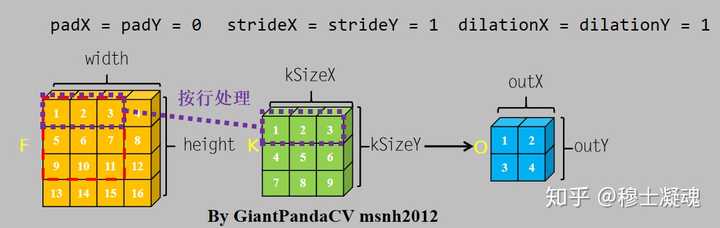
以卷积操作举例,此处只讨论暴力方法,不涉及im2col, winograd等方法.
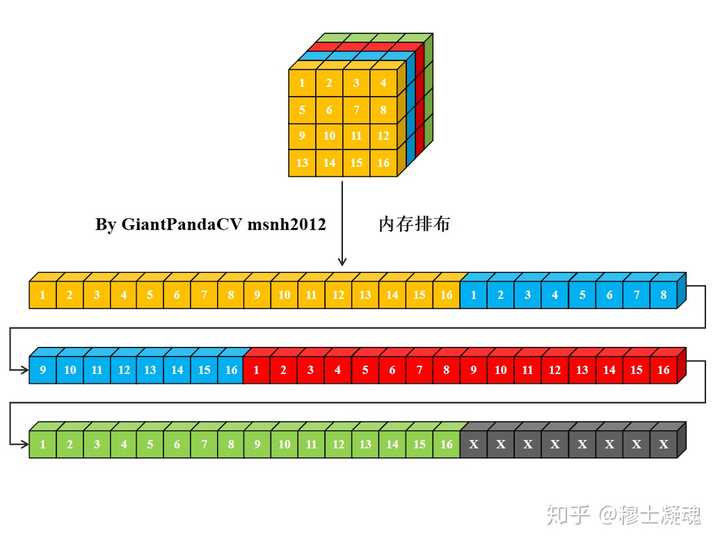
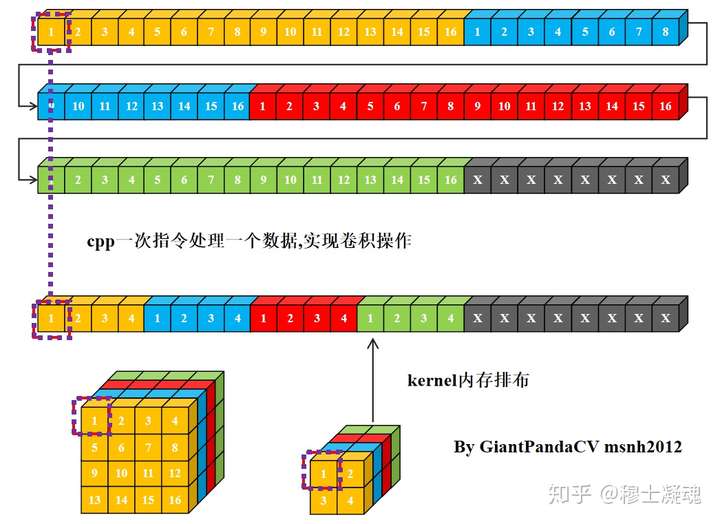
对于卷积操作, 根据计算机内存排布特点, 按行进行处理.处理完一个通道的数据, 转入下一个通道继续按行处理.
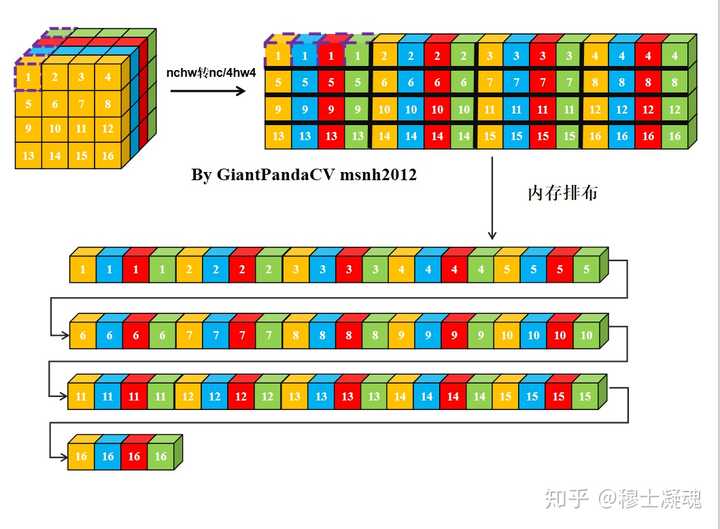
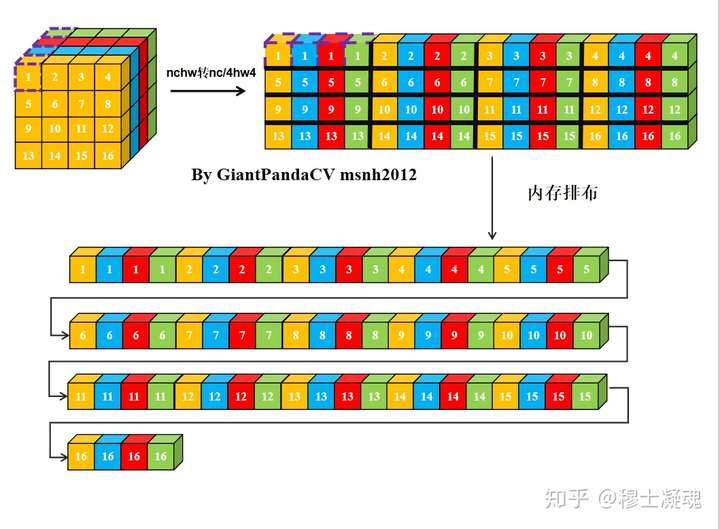
对于一个nchw格式的Tensor来说, 其在计算机中的内存排布是这样的:
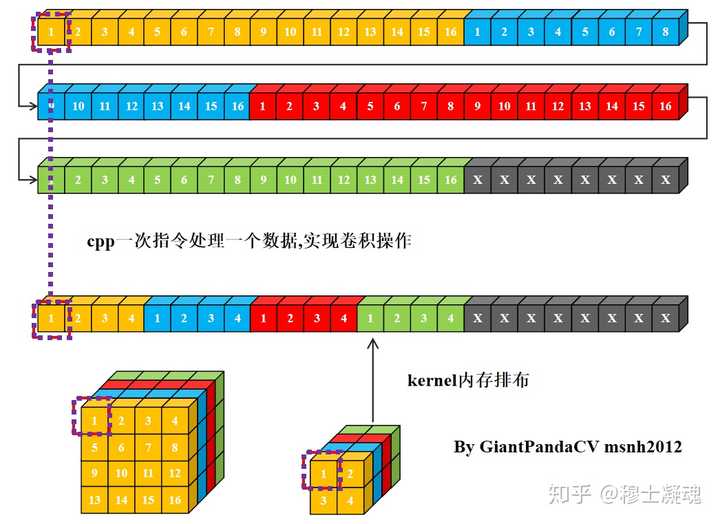
使用cpp一次指令处理一个数据, 用来处理卷积操作, 即循环实现乘法相加即可.
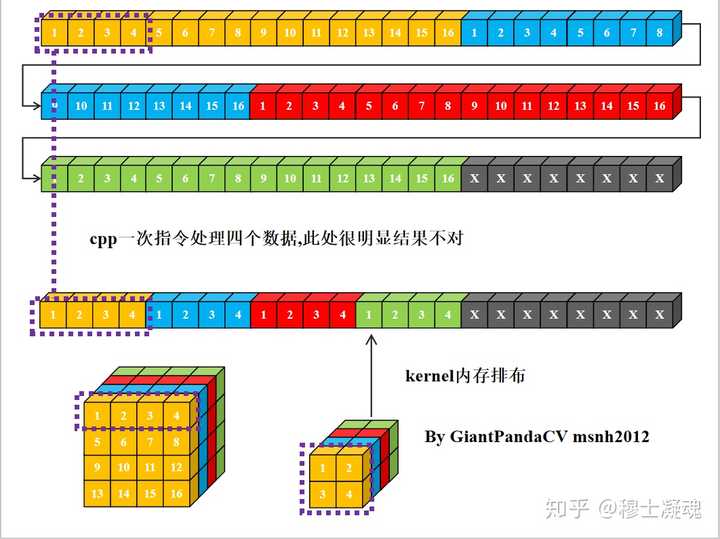
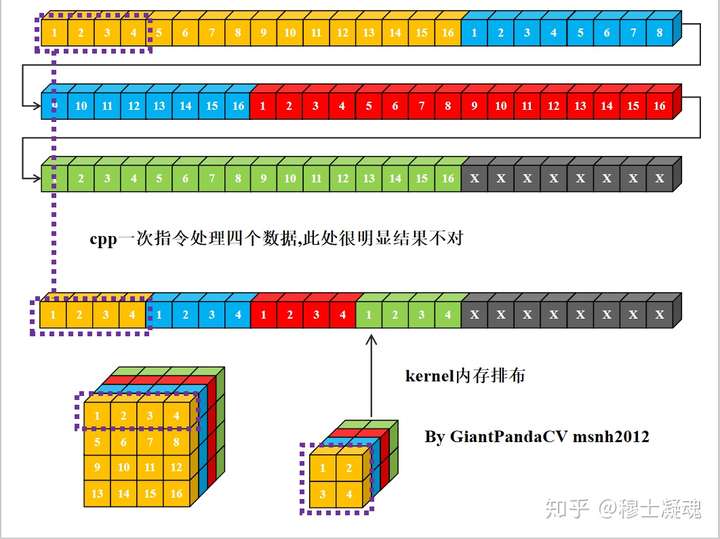
现在有一条指令处理4组数据的能力, 比如x86结构的sse指令,arm的neon指令.以及GPGPU的OpenGL和OpenCL,单次处理RGBA四组数据. 如果继续使用nchw内存排布的话, 是这样的.
根据按行处理特点, 对于Feature和kernel的宽不是4倍数进行处理, 会出现错误. 图中的kernel很明显以已经到了第二行的值.
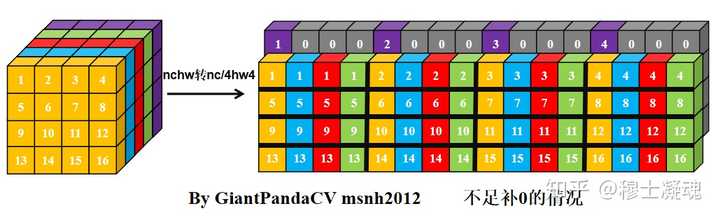
那么有没有方法在按行处理的思想上, 一次处理4个数,而不受影响.答案是有的, 即NC4HW4.即把前4个通道合并在一个通道上, 依次类推, 在通道数不够4的情况下进行补0.
经过NC4HW4重排后的Tensor在内存中的排布情况如下:
那么, 此时在进行单次指令处理4组数据的处理,就没有问题了.只不过处理结果也是NC4HW4结构的,需要在结果输出加上NC4HW4转nchw.
总结:
优点:
进行NC4HW4重排后,可以充分利用cpu指令集的特性,实现对卷积等操作进行加速。同时可以较少cache miss.
缺点:
对于较大的feature,如果其channel不是4的倍数,则会导致补充0过多,导致内存占用过高,同时也相应的增加些许计算量。



评论(0)
您还未登录,请登录后发表或查看评论