

在谈到faster rcnn时,很多细节还有待深究,一直想好好看看其源码,并整理出来,好像还挺遥遥无期,留待以后吧。现在主要针对三处比较模糊的地方进行分析。
一、ROI Align的基本原理
讲到Align有必要谈一下双线性插值的原理。
数字图像中实现缩放的方法有很多种,其中一种就是双线性插值,在实现图像缩放时,有两种方法来确定缩放后的图像的像素值,第一种是根据原图像中的的像素找到对应的缩放后的图像中的像素,第二种是根据缩放后的图像找到对应的原图像中的像素,如下图
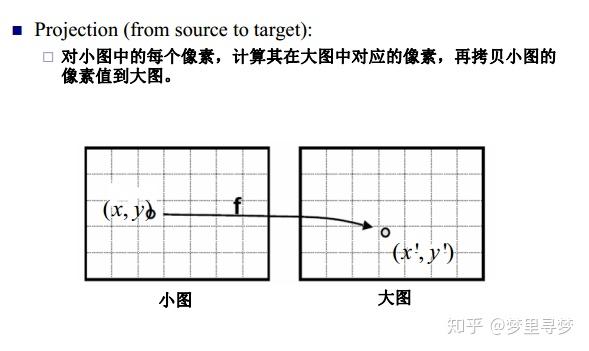
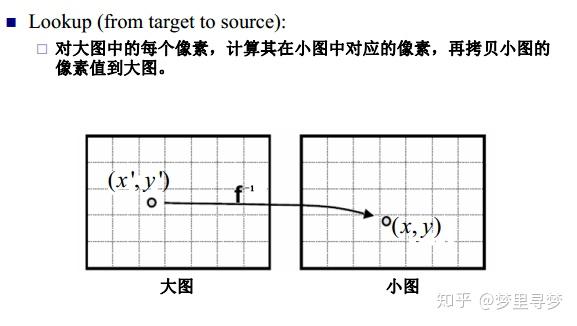
但是第一种方法有缺点,因为小图中的像素点到大图中的像素点不是满射,因此大图中的点不能完全有像素值,第二种方法也有缺点,大图中的点逆映射为小图中的点时,得到的像素坐标值可能不是整数,一种办法是采用最近邻方法,即将得到的坐标值与相邻的原图像中的像素坐标值比较,取离得最近的坐标值对应的像素值作为缩放后的图像对应的坐标值的像素值,这种办法可能导致图像失真,因此采用双线性差值的办法来进行计算相应的像素值。

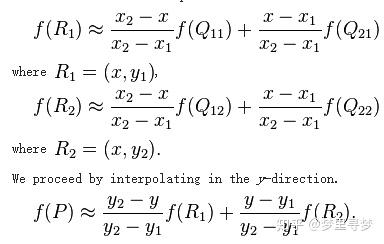
右侧是最一般的双线性插值,下面举一个实际的例子来说明双线性插值在图像缩放中的应用。
假设一个图像的大小是485x647,放大分别放大1.3倍和1.7倍,即485x1.3=630.5,647x1.7=1099.9,根据四舍五入的原则确定放大后的图像为631x1100,接下来就是计算放大后图像各个位置的像素值,例如计算放大后图像位于(136,345)位置的像素值,则136/1.3=104.615,345/1.7=202.941,这里由于示例的原因取小数点后三位,则原图像中相邻的四个位置分别是(104,202),(104,203),(105,202),(105,203)这四个点,

如图我画出了这个点对应的周围的四个点,202.941-202=0.941
所以f(R1)=(1-0.941)xf(104,202)+0.941xf(104,203),
f(R2)=(1-0.941)xf(105,202)+0.941xf(105,203),
104.615-104=0.615
所以f(P)=(1-0.615)xf(R1)+0.615xf(R2),
其中f表示的那一点的像素值,这样就计算出了f(P),实际上就是放大后图像(136,345)处对应的像素值。
所以上述的重点在于说明了放大和缩小之后的像素点返回原图到底在哪:相当于反向放大缩小后的坐标点,找到原像素点中最临近的点。
这是我之前一直没搞明白的地方,现在再举一个例子讲讲(很多问题只有通过例子才能显得如此通俗易懂)。
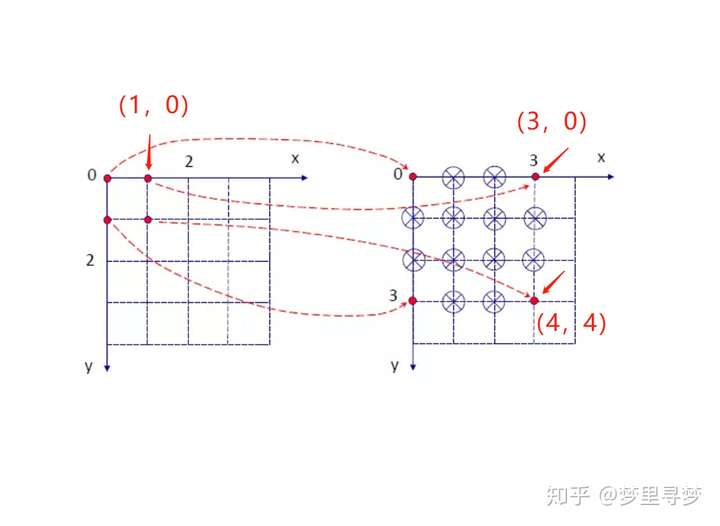
1、假设左图为原图,4个红点为4个像素点,将左图放大2倍,得到右图,现在就是要得到右图各个点坐标的像素值。
右图原点的坐标(0,0),映射回原图坐标为(0/2,0/2),即(0,0),那么就直接取原图中(0,0)的像素值。
右图中坐标(3,0),映射回原图坐标为(3/2,0),此时与该点最邻近的坐标为(1,0),(2,0),其中(2,0)超过原图则用0补全。然后应用线性插值算出该点像素值。
2、假设右图为原图,将4*4的像素点缩小为2*2的左图。现在求左图对应回原图的像素位置。
如(1,1)对应回原图为(2,2)的位置,直接取该点的像素值。可以看到,对于该例,左图的4个像素点就直接取右图中(0,0)、(2,0)、(0,2)和(2,2)的位置,也没用上双线性插值。
上面只是一个简单的例子,告知了原图与缩放之后的图应该如何映射,然后找到最邻近的四个点位置,并进行双线性插值。
重头戏
ROI Align 是在Mask-RCNN这篇论文里提出的一种区域特征聚集方式, 很好地解决了ROI Pooling操作中两次量化造成的区域不匹配(mis-alignment)的问题。实验显示,在检测测任务中将 ROI Pooling 替换为 ROI Align 可以提升检测模型的准确性。
先笼统讲述一下ROIpooling与ROIAlign
对ROIpooling,比方我们映射到featuremap上的锚框为5*7,对选择的区域要分成2*2的区域,而5/2=2.5,所以我们对于高,分割成2+3,7/2=3.5,所以我们对于宽,分割成3+4,那么我们会将该处分割成如下右边的4个小块。并对4个小块做maxpooling,最终得到一个2*2的featuremap。

对于ROIAlign,对我们同样要将映射到featuremap上5*7的锚框分割成2*2的区域,此时我们不再选择四舍五入,如下图右边图所示,至于之后怎么处理,下文会接着讲到。
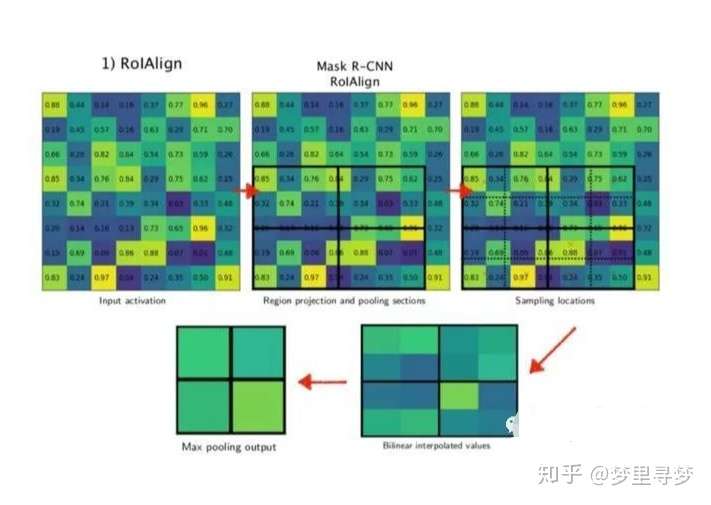
1. ROI Pooling 的局限性分析
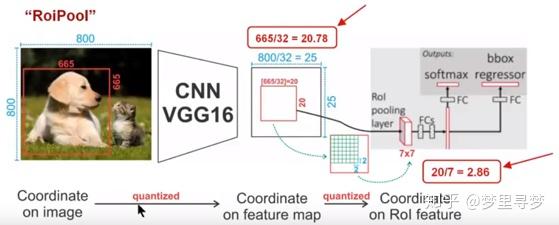
在常见的两级检测框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,ROI Pooling 的作用是根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。由于预选框的位置通常是由模型回归得到的,一般来讲是浮点数,而池化后的特征图要求尺寸固定。故ROI Pooling这一操作存在两次量化的过程。
- 将候选框边界量化为整数点坐标值。
- 将量化后的边界区域平均分割成 k x k 个单元(bin),对每一个单元的边界进行量化。
事实上,经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。在论文里,作者把它总结为“不匹配问题(misalignment)。
下面我们用直观的例子具体分析一下上述区域不匹配问题。如 图1 所示,这是一个Faster-RCNN检测框架。输入一张800*800的图片,图片上有一个665*665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。接下来需要把框内的特征池化7*7的大小,因此将上述包围框平均分割成7*7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
图 1
2. ROI Align 的主要思想和具体方法
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法(如图2)。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作,。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套比较优雅的流程,如 图3 所示:
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成k x k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,我在实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。
图 2
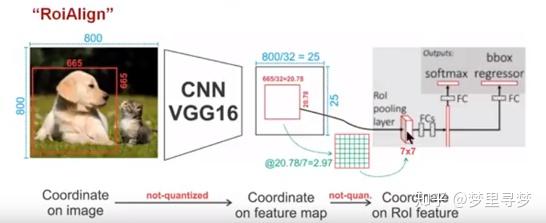
同样,针对图2,有着类似的映射
1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800*800,最后一层特征图feature map大小:25*25
2)假定原图中有一region proposal,大小为665*665,这样,映射到特征图中的大小:665/32=20.78,即20.78*20.78,此时,没有像RoiPooling那样就行取整操作,保留浮点数
3)假定pooled_w=7,pooled_h=7,即pooling后固定成7*7大小的特征图,所以,将在 feature map上映射的20.78*20.78的region proposal 划分成49个同等大小的小区域,每个小区域的大小20.78/7=2.97,即2.97*2.97
4)假定采样点数为4,即表示,对于每个2.97*2.97的小区域,平分四份,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样,就会得到四个点的像素值,如下图。这也是本部分开头要处理的问题。
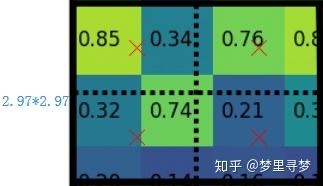
上图中,四个红色叉叉‘×’的像素值是通过双线性插值算法计算得到的。
如何计算呢?
坐上角的像素值,就由0.85,0.34,0.32,0.74的中心位置通过双线性插值共同决定其像素点的值,比方说,0.85像素的坐标为(0,0),0.32像素的坐标为(0,1),那么x这点的坐标就大概为(2.97/4,2.97/4)。
最后,取四个像素值中最大值作为这个小区域(即:2.97*2.97大小的区域)的像素值,如此类推,同样是49个小区域得到49个像素值,组成7*7大小的feature map
图 3
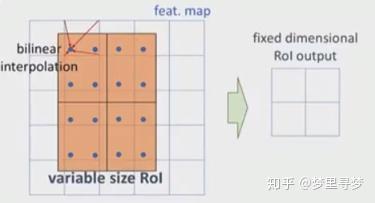
3. ROI Align 的反向传播
常规的ROI Pooling的反向传播公式如下:
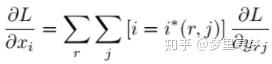
这里,xi代表池化前特征图上的像素点;yrj代表池化后的第r个候选区域的第j个点;i*(r,j)代表点yrj像素值的来源(最大池化的时候选出的最大像素值所在点的坐标)。由上式可以看出,只有当池化后某一个点的像素值在池化过程中采用了当前点Xi的像素值(即满足i=i*(r,j)),才在xi处回传梯度。
类比于ROIPooling,ROIAlign的反向传播需要作出稍许修改:首先,在ROIAlign中,xi*(r,j)是一个浮点数的坐标位置(前向传播时计算出来的采样点),在池化前的特征图中,每一个与 xi*(r,j) 横纵坐标均小于1的点都应该接受与此对应的点yrj回传的梯度,故ROI Align 的反向传播公式如下:
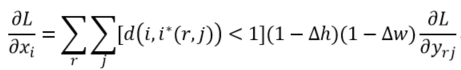
上式中,d(.)表示两点之间的距离,Δh和Δw表示 xi 与 xi*(r,j) 横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上。
以上应该基本讲清楚了ROIAlign的使用及其细节,说得还是有点乱,不过暂时只能如此了。
接下去讲一下rpn与rcnn head锚框标签制作,虽然都只是文字表述,但是应该还是很好理解(主要作图太耗时耗力了)。
锚框标签制作
步骤:假设featuremap形状为38*50(H*W)
1、为38*50的每个像素点形成9个锚框,共形成9*38*50的锚框total_anchors,表现为数组形式,shape为[9*38*50,4],4指的是每个锚框的xmin,ymin,xmax,ymax;
2、将各个锚框坐标映射到原图,形成基于原图的锚框坐标,形式同上;
3、去除超过边框坐标的锚框,最后剩len(inds_insides)个,inds_insides为total_anchors去除超过边框的锚框后剩下的索引;
4、为锚框分配与其相似的真实边界框:
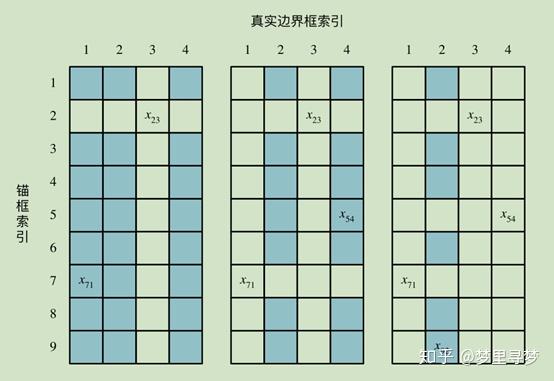
A:argmax_overlaps是计算每个anchor和哪个object的IOU最大,维度是n*1,值是object的index。
B:gt_argmax_overlaps = overlaps.argmax(axis=0)则是计算每个object和哪个anchor的IOU最大,维度是m*1,值是anchor的index,另外因为如果有多个anchor和某个object的IOU值都是最大且一样,那么gt_argmax_overlaps只会得到index最小的那个。
5、labels初始化为-1,shape为(len(inds_inside),),将IOU<0.3的置为0,将IOU>0.7的置为1;
6、设置正负样本比例,比如0.5,意味着batch256中128为正样本,128为负样本。重抽样label,选中的值维持原来的值,其余的置为-1;
7、创建bbox_targets,其为数组,shape为(len(inds_inside),4)。用第3步形成的锚框坐标与每个锚框对应的真实锚框做位置偏移,4即代表4个偏移的坐标值。
8、创建bbox_weights,其为数组,shape为(len(inds_inside),4)。label标签是0或-1的weight都是0,其余为1.
9、映射回原来的锚框长度为9*38*50=17100的锚框长度,label的shape(1,9*38*50),bbox_targets的shape为1*36*38*50,bbox_targets的维度是1*36*38*50。映射回去后,被过滤掉的bbox的label都是-1,bbox_targets都是0,bbox_weights都是0。
10、结束
Proposal标签制作
1、通过RPN可以分别形成两个featuremap,分类的shape为(batch,2*9,H,W),bbox的shape为(batch,4*9,H,W)。进一步经过bbox的偏移值,可以将bbox映射回原图中实际的锚框坐标,此时bbox的shape变为(4*9*H*W,5),其中第一列为batch的值。再通过NMS(非极大值抑制),选取概率最高的前2000个框。
2、对剩下的2000个框,将bbox数据放进Rois里,维度为(2000,5),第一列不是roi的标签,只是batch的index标识。Gt_boxes为真实锚框,shape为(x,5),x是object的数量。
3、将Gt_boxes的第一列置为0,然后和rois合并,最后rois的shape为(2000+x,5)。
4、计算每个rois和ground truth的IOU矩阵bbox_overlaps,shape为(2000+x,x)。计算每个rois与哪个ground truth之间的IOU最大,记录该IOU的索引gt_assignment,shape为(2000+x,1),并记录此时最大的IOU值overlaps,shape同样为(2000+x,1),labels记录每个rois对应IOU最大的ground truth的标签,维度也为(2000+x,1)。
5、对rois做抽样,目的是让rois总数都维持一个固定值(如128),并设置正负roi的比例(1:3),相当于正负样本为32:96。
6、计算正样本roi的index。设置TRAIN.FG_THRESH,默认是0.5,这里是将和ground truth的最大IOU大于这个阈值的roi认为是foreground,也就是有object,一般fg_indexes都不多,常见几十。如果fg_indexes的个数超过32,则随机抽样出32个,少于32个,就不做处理。
7、计算负样本roi的index。设置TRAIN.BG_THRESH,注意这里是[0.1,0.5],并对该区间的bg_indexes做随机抽样,选取96个,如果前景少于32个,比如前景只有20个,那么背景就抽样出128-20=108个。
8、前面对roi做foreground和background的采样后,roi的数量就从2000+x降为rois_per_image(默认是128),具体的index保存在keep_indexes中。roi对应的标签保存在labels变量中,labels = labels[keep_indexes]。Labels中正样本维持原值,负样本置为0。
9、此时rois的shape为(128,5),第一列为index,记录keep_indexes。
10、对bbox_targets_data进行分配,计算roi与对应gt_boxes的offset,并对bbox_targets进行归一化(具体有待再细化去看)。bbox_target_data的维度是(128,5),第一列是真实标签,剩下4列是回归的预测目标。
11、分配bbox_targets,比如共有分类数20,则其shape为(128,4*21),根据bbox_targets_data的真实标签,比如第一个rois为第20类,那么就将bbox_target_data[0,1:4]赋值给bbox_targets[0,80:84],其余位置为0,以此类推。bbox_weights的shape与bbox_targets一致,并将其对应位置赋值为1,其余均为0。其中背景类的bbox_targets和bbox_weights也均为0。
12、结束
参考文章:http://blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b



评论(0)
您还未登录,请登录后发表或查看评论