

这个问题困扰我挺久,一度还理解错混淆矩阵的含义,每次记住一会没多久又忘了,而目标检测的AP与mAP问题又一直模模糊糊的,今天终于比较清晰地理解了,感谢网络上各网友无私而又丰富的知识分享。
混淆矩阵的定义
混淆矩阵(Confusion Matrix),它的本质远没有它的名字听上去那么拉风。矩阵,可以理解为就是一张表格,混淆矩阵其实就是一张表格而已。
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。

TP: 将正类预测为正类数;TN: 将负类预测为负类数;
FP: 将负类预测为正类数(错报);FN: 将正类预测为负类数(漏报)。
此前一直要记混这4个词的含义,实际应该这么来记:
TP为例,意思是预测为P,即正类,结果为T,即正确,那么这个物体就真的为正类;FN为例,意思是预测为N,即负类,结果为F,即错误了,那么这个物体实际上就是正类;FP为例,意思是预测为P,即正类,结果为F,即错误了,那么这个物体实际上就是负类。
以上这么去看待,就几乎不会记混了。
准确率(Accuracy): ACC=(TP+TN)/(TP+TN+FP+FN)
TP+TN:预测为正类和预测为负类结果都对了的数量,相当于就是预测结果中,预测对了的数量。这个需要自己去体会一下。
精确率(Precision): P=TP/(TP+FP)(分类后的结果中正类的占比)
TP+FP:预测为正的数量。精确率就是说预测为正的数量当中,实际物体也是正类的比例。
召回率(Recall): R=TP/(TP+FN)(所有正例被分对的比例,也称灵敏度)
TP+FN:实际为正的数量。召回率就是说实际上为正的数量当中,被预测为正的数量比例。
特异度(Specificity):S=TN/(TN+FP)(所有负类被分对的比例)
F1 Score:F1=2PR/(P+R)
其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
混淆矩阵的实例
当分类问题是二分问题是,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同时适用。
一下面的混淆矩阵为例,我们的模型目的是为了预测样本是什么动物,这是我们的结果:
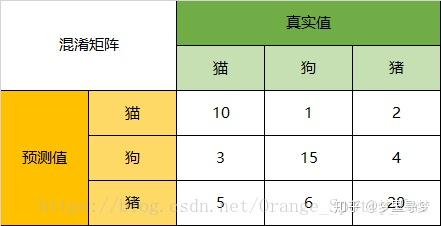
通过混淆矩阵,我们可以得到如下结论:
Accuracy
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
以猫为例,我们可以将上面的图合并为二分问题:
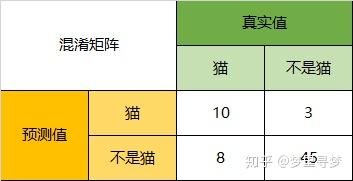
Precision
所以,以猫为例,模型的结果告诉我们,66只动物里有13只是猫,但是其实这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall
以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。Recall我们前文说过指的就是实际为猫的数量18,我们预测也是猫的数量10的比例,所以,Recall(猫)= 10/18 = 55.6%
Specificity
以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。
虽然在45只动物里,模型依然认为错判了6只狗与4只猫,但是从猫的角度而言,模型的判断是没有错的。
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
Object Detection 中的 Recall 和 mAP 实验指标的计算
底下将介绍两个例子,共同来表述目标检测的AP与mAP
例子1
这里以一个例子来展开。假设一张图片A上标注有5个苹果,另外5个物体为其他水果,而物体检测模型在A上将10个物体都识别为苹果,具体结果如下表所式,则对于“苹果”这一类,其Recall和mAP为:
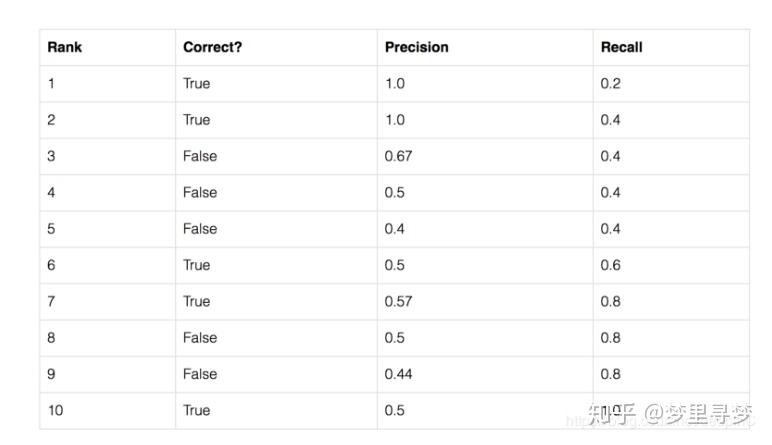
第2列中True的含义,比如rank1表示锚框1预测为苹果,实际上也是苹果,预测对了。
那么Precision怎么计算呢?
Precision指的是预测当中实际也对的数量的比例。rank1为例,只有预测了一个锚框,而这个锚框预测对了,那precision就是1/1=1;rank3为例,预测了3个锚框,其中2个预测对了,那precision就是2/3=0.67;rank6为例,预测了6个锚框,实际上只有3个是对的,那precision就是3/6=0.5;rank9为例,预测了9个锚框,实际对了只有4个,那precision就是4/9=0.44.
那么Recall怎么计算呢?
Recall指的是实际上为正的数量当中预测也对的数量。rank1为例,实际上有5个苹果,只有rank1预测对了,其余虽然还没有结果,但是不影响,那Recall就是1/5=0.2;rank4为例,实际上有5个苹果,只有rank1跟rank2预测对了,那Recall就是2/5=0.4;rank10为例,实际上有5个苹果,rank1、2、6、7、10都预测对了,那Recall就是5/5=1.
由上述的表格可直接画出 PR 曲线:
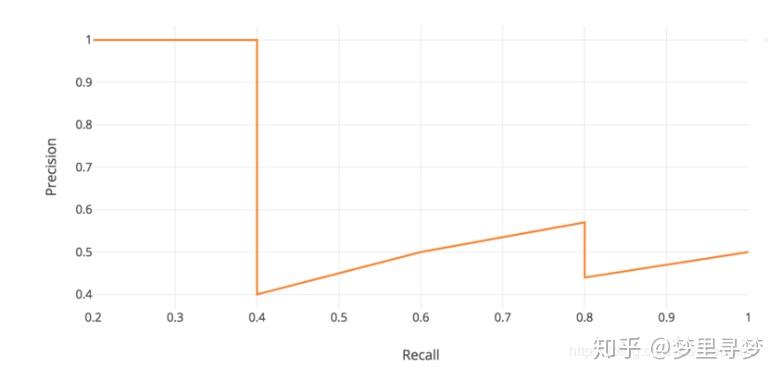
AP指的就是PR曲线围城的面积。
第一种,我们可以根据上面画的图,运用类似积分方法计算这部分面积,但是这样计算较为繁琐。
第二种,采用近似算法,具体算法如下:

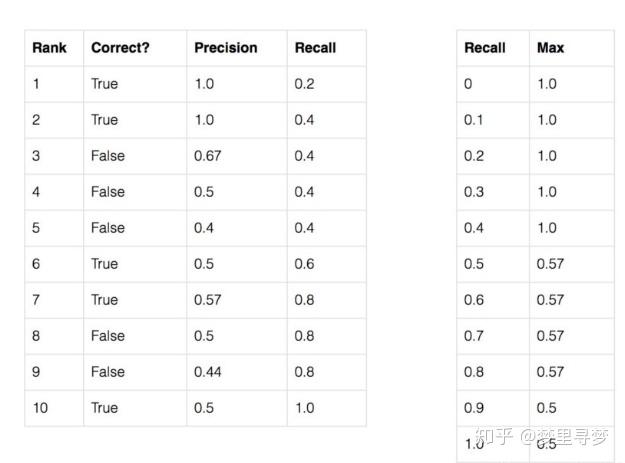
因此,AP=(1.0×5+0.57×4+0.5×2)/11=0.75。
而mAP就是多来几个例子,比如西瓜,哈密瓜,然后计算三个的AP,最后求平均。
例子2
- TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)
- FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
- FN: 没有检测到的GT的数量
- mAP: mean Average Precision, 即各类别AP的平均值
- AP: PR曲线下面积,后文会详细讲解
- PR曲线: Precision-Recall曲线
由前面定义,我们可以知道,要计算mAP必须先绘出各类别PR曲线,计算出AP。而如何采样PR曲线,VOC采用过两种不同方法。参见:The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Development Kit
在VOC2010以前,只需要选取当Recall >= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值(如例子1)。
在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。
假设,对于Aeroplane类别,我们网络有以下输出(BB表示BoundingBox序号,IoU>0.5时GT=1)。先做一个解释,这相当于一张图片中有7个GT是Aeroplane,BB1与BB10检测的都是GT1,BB2检测的是GT2,BB5检测的是GT3,BB8检测的是GT4,BB9检测的是GT5。另外的BB可能是GT,也可能是其他物体,但是对我们计算不影响。此外,也就是说GT6与GT7没有预测锚框与之对应,简而言之就是没有检测出来。
BB | confidence | GT
----------------------
BB1 | 0.9 | 1
----------------------
BB2 | 0.9 | 1
----------------------
BB10 | 0.8 | 1
----------------------
BB3 | 0.7 | 0
----------------------
BB4 | 0.7 | 0
----------------------
BB5 | 0.7 | 1
----------------------
BB6 | 0.7 | 0
----------------------
BB7 | 0.7 | 0
----------------------
BB8 | 0.7 | 1
----------------------
BB9 | 0.7 | 1
----------------------
因此,我们有IoU>0.5的检测框数量(同一Ground Truth只计算一次)TP=5 (BB1, BB2, BB5, BB8, BB9),BB10同样检测的是GT1,所以不算。IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量FP=5 (BB3、BB10、BB4、BB6、BB7,重复检测到的GT1也算FP,即BB10)。除了表里检测到的5个GT以外,我们还有2个GT没被检测到(实际图中有7个真实锚框),因此: FN = 2. 这时我们就可以按照Confidence的顺序给出各处的PR值,如下:
rank=1 precision=1.00 and recall=0.14
----------
rank=2 precision=1.00 and recall=0.29
----------
rank=3 precision=0.66 and recall=0.29
----------
rank=4 precision=0.50 and recall=0.29
----------
rank=5 precision=0.40 and recall=0.29
----------
rank=6 precision=0.50 and recall=0.43
----------
rank=7 precision=0.43 and recall=0.43
----------
rank=8 precision=0.38 and recall=0.43
----------
rank=9 precision=0.44 and recall=0.57
----------
rank=10 precision=0.50 and recall=0.71
至于PR值是怎么算的跟上个例子一样,比如rank10,实际物体为plane预测也为plane的recall值为5/7=0.71,预测为plane的实际也为plane的为5/10=0.5,值得说的是BB10虽然也IOU符合要求了,但是我们实际中不选它,所以不算是真的预测出来。
对于上述PR值,如果我们采用:
- VOC2010之前的方法,我们选取Recall >= 0, 0.1, ..., 1的11处Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0.5, 0.5, 0, 0, 0。此时
Aeroplane类别的 AP = 5.5 / 11 = 0.5。(算法与例子1一模一样) - VOC2010及以后的方法,对于Recall >= 0, 0.14, 0.29, 0.43, 0.57, 0.71, 1,我们选取此时Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0。此时
Aeroplane类别的 AP = (0.14-0)*1 + (0.29-0.14)*1 + (0.43-0.29)*0.5 + (0.57-0.43)*0.5 + (0.71-0.57)*0.5 + (1-0.71)*0 = 0.5
方法2比较合理,就应该是按照面积近似的逼近来看,相当于PR曲线下面积的近似计算。
mAP就是对每一个类别都计算出AP然后再计算AP平均值就好了
当比较 MAP 值,记住以下要点:
1. MAP 通常是在一个数据集上计算得到的。
2. 虽然解释模型输出的绝对量化并不容易,但 MAP 作为一个相对较好的度量指标可以帮
助我们。 当我们在流行的公共数据集上计算这个度量时,该度量可以很容易地用来比
较目标检测问题的新旧方法。
3. 根据训练数据中各个类的分布情况,MAP 值可能在某些类(具有良好的训练数据)非
常高,而其他类(具有较少/不良数据)却比较低。所以你的 MAP 可能是中等的,但是
你的模型可能对某些类非常好,对某些类非常不好。因此,建议在分析模型结果时查看
各个类的 AP 值。这些值也许暗示你需要添加更多的训练样本。
参考文章:https://blog.csdn.net/deepinC/article/details/86556736
参考文章:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839
参考文章:https://www.zhihu.com/question/53405779/answer/419532990



评论(0)
您还未登录,请登录后发表或查看评论