

项目简介
本项目基于朴素贝叶斯算法来解决垃圾邮件分类问题,并使用混淆矩阵进行了验证,得到了非常好的准确率和召回率(96%和97%)。此外还开发了一个可视化的垃圾邮件分类系统界面,使用PyQT进行界面设计。
项目结构
- data:数据集
- trec06c:中文邮件数据集
- data:中文邮件数据集
- delay:邮件文本索引和标签
- full:邮件文本索引和标签
- model:训练好的模型
- cut_word_lists.npy:分词结果
- main.py:垃圾邮件统计分类全部代码
- stopwords.txt:停用词
- VisualizationInterface.py:垃圾邮件可视化分类全部代码
项目开发软件环境
- Windows 11
- Python 3.7
- PyCharm 2022.1
项目开发硬件环境
- CPU:Intel® Core™ i7-8750H CPU @ 2.20GHz 2.20 GHz
- RAM:24GB
- GPU:NVIDIA GeForce GTX 1060
前言
本博客对基于朴素贝叶斯的垃圾邮件分类系统的开发过程进行了详细的总结,从原理到实现每一步都有记录,看完本篇博客保证各位读者对这方面知识有着更深入的了解。另外,只要跟着我一步一步做,各位读者也可以实现基于朴素贝叶斯的垃圾邮件分类系统!
零、项目演示
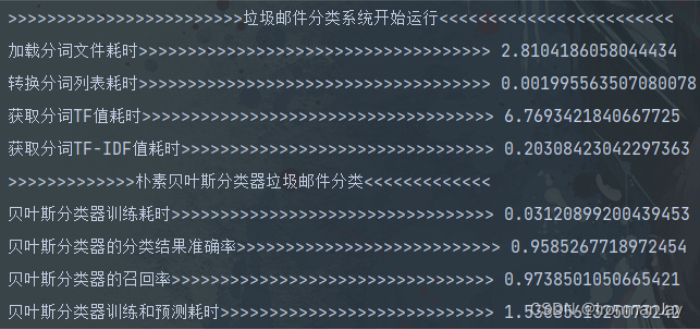
1.使用朴素贝叶斯分类器对垃圾邮件训练和测试的结果:
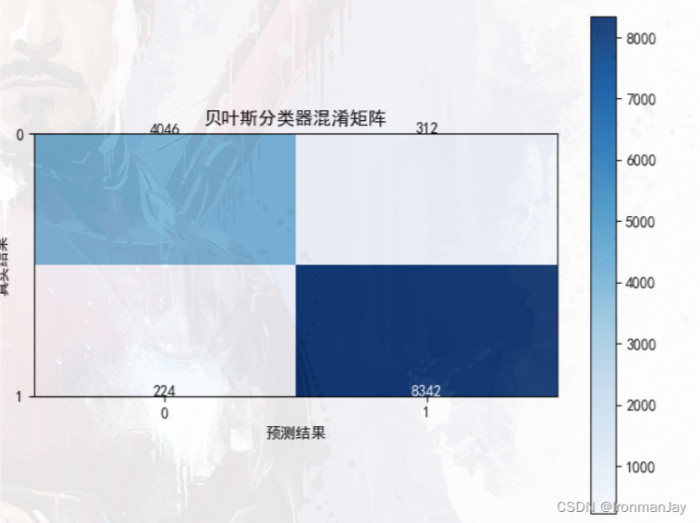
2.贝叶斯分类器混淆矩阵:
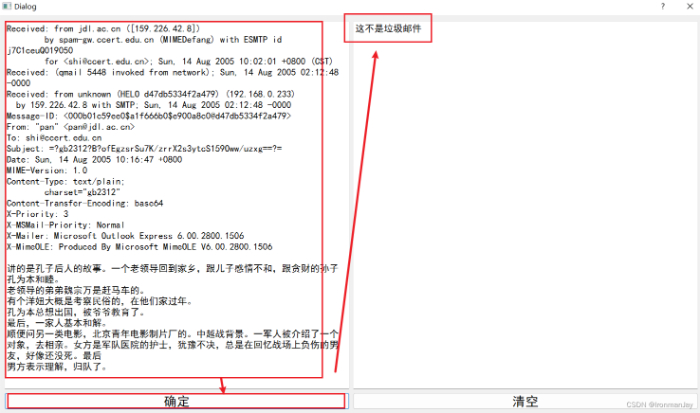
3.对非垃圾邮件的分类:
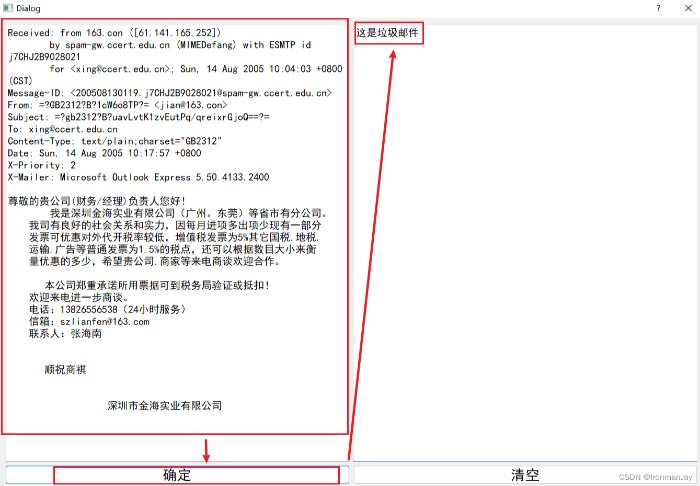
4.对垃圾邮件的分类:
一、邮件数据集
本项目所采用的数据集来源为国际文本检索会议提供的一个公开的垃圾邮件语料库,可以进入官网下载此数据集,此数据集是一个广泛使用的电子邮件数据集,用于测试垃圾邮件过滤算法的效果。该数据集包含了大约10000个标记的开发集和50000个未标记的测试集,共60000余封测试邮件。其中约40%的电子邮件消息被标记为垃圾邮件,其余的则被标记为非垃圾邮件。而我们本项目所采用的数据集为其中的trec06c中文邮件数据集,如果想进行英文的垃圾邮件分类,可以使用其中的trec06p数据集。
此数据集被广泛用于各种研究项目中,例如垃圾邮件过滤、邮件分类和特征提取等。此外,该数据集还被用于比较不同算法的性能,如支持向量机、朴素贝叶斯、决策树等。但是我们在使用的时候需要对电子邮件进行一些预处理操作,例如去除HTML标记、停用词过滤和词干提取。评估指标包括精确度、召回率、F1分数等。根据之前的研究结果,该数据集的分类性能通常在90%左右。
可以直接使用上面提供的下载链接下载数据集,下文我会详细介绍如何对此数据集进行预处理和具体的使用。下面就是本数据集中的中文邮件的一个示例: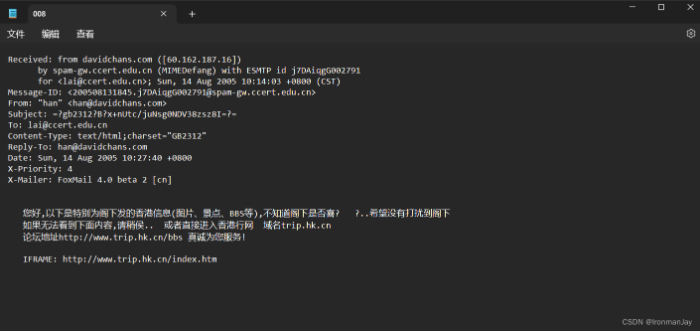
二、算法原理
2.1 条件概率公式
条件概率是指在某种条件下发生某一事件的概率,通常用符号P(A∣B)表示,在事件B BB发生的前提下事件A AA发生的概率。条件概率公式是用来计算条件概率的数学公式,它可以表示为: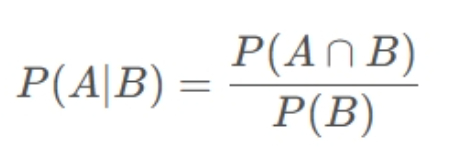
其中,P(A∩B)表示事件A和事件B同时发生的概率,P(B)表示事件B发生的概率。因此,条件概率公式可以解释为:在事件B发生的前提下,事件A和B同时发生的概率,除以事件B发生的概率,就是在事件B发生的前提下事件A发生的概率。
例如,假设某个班级有30名学生,其中20名男生和10名女生。如果从这个班级中随机选出一个学生,问选出的学生是男生的概率是多少?根据条件概率公式,我们可以得到:
其中,P(男生∩选中的学生)表示选中的学生是男生的概率,P(选中的学生)表示任意一个学生被选中的概率。因为男生占总人数的2/3,所以选中男生的概率为20/30,即2/3;任意一个学生被选中的概率为1,因为我们一定会选中一个学生。因此,我们可以得到:
因此,从这个班级中随机选中一个学生,他是男生的概率是2/3。
2.2 全概率公式
全概率公式是概率论中一个重要的公式,用于计算某个事件的概率。它可以用于处理复杂的概率问题,特别是当我们无法直接计算事件的概率时,可以通过全概率公式来计算。全概率公式可以表示为:
其中,P(A)表示事件A AA发生的概率,P(A∣Bi)表示在事件Bi发生的条件下,事件A发生的概率,P(Bi)表示事件Bi发生的概率。∑i=1表示对所有可能发生的事件Bi求和,即包括事件B1,B2,...,Bn。
该公式的基本思想是,将事件A发生的概率分解为在不同条件下的概率之和。换句话说,事件A可能会在不同的条件下发生,我们需要考虑所有可能的条件,然后计算每个条件下事件A发生的概率,并加权求和。这些权重是每个条件下的概率,即P ( Bi)。
例如,我们假设班级里有1/3的学生喜欢数学,1/3的学生喜欢语文,1/3的学生喜欢英语。我们还知道,喜欢数学的学生中有1/2的人喜欢计算机,喜欢语文的学生中有1/3的人喜欢计算机,而喜欢英语的学生中有1/4的人喜欢计算机。
现在问题来了,如果随机选取一个学生,他或她喜欢计算机的概率是多少?我们可以使用全概率公式来解决这个问题,即:
P(喜欢计算机)=P(喜欢计算机∣喜欢数学)∗P(喜欢数学)+P(喜欢计算机∣喜欢语文)∗P(喜欢语文)+P(喜欢计算机∣喜欢英语)∗P(喜欢英语)
其中,P(喜欢计算机∣喜欢数学)表示在喜欢数学的学生中喜欢计算机的概率,即1/2;)P(喜欢数学)表示喜欢数学的学生占总人数的比例,即1/3。同理,P(喜欢计算机∣喜欢语文)表示在喜欢语文的学生中喜欢计算机的概率,即1/3;P(喜欢语文)表示喜欢语文的学生占总人数的比例,即1/3。P(喜欢计算机∣喜欢英语)表示在喜欢英语的学生中喜欢计算机的概率,即1/4;P(喜欢英语)表示喜欢英语的学生占总人数的比例,即1/3。
因此,将这些值代入公式,我们可以得到: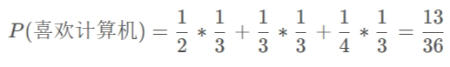
因此,随机选取一个学生,他或她喜欢计算机的概率是13/36.
2.3 朴素贝叶斯公式
2.3.1 什么是朴素贝叶斯公式
现在我们已经掌握了条件概率公式和全概率公式,下面让我们再进一步,学习一下朴素贝叶斯公式。朴素贝叶斯公式是一种基于贝叶斯定理的简单概率分类器。朴素贝叶斯假设每个特征在给定类别下都是条件独立的。尽管这个假设在现实世界中往往不成立,但朴素贝叶斯在许多实际问题中表现出惊人的性能。朴素贝叶斯公式如下: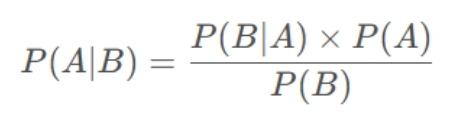
其中,P(A∣B)是后验概率,表示在给定B的情况下,A发生的概率;P(B∣A)是条件概率,表示在给定A的情况下,B发生的概率;P(A)是A的先验概率;P(B)是B的先验概率。
现在我们用一个班级学生的例子来解释朴素贝叶斯。假设一个班级有100名学生,其中60名男生,40名女生。我们想要预测一个学生是否戴眼镜。我们已经观察到,男生中有30名戴眼镜,女生中有20名戴眼镜。问题:给定一个戴眼镜的学生,他(她)是男生的概率是多少?
我们根据贝叶斯定理来求解:
在这个例子中:
我们首先计算P(戴眼镜):
P(戴眼镜)=P(戴眼镜∣男生)×P(男生)+P(戴眼镜∣女生)×P(女生)=0.5×0.6+0.5×0.4=0.5
然后,我们可以根据朴素贝叶斯公式计算后验概率:
所以,给定一个戴眼镜的学生,他(她)是男生的概率是60%。
2.3.2 使用朴素贝叶斯公式进行垃圾邮件分类
当我们掌握以上知识点后,就可以使用朴素贝叶斯公式来解决垃圾邮件分类的问题。在正式解决这个问题之前我们先思考,作为人来说,我们如何对一个事物进行分类呢?比如要从各种植物中识别出草、花、树等等,可以从颜色、形状等等特征分析;从各种动物中识别出猫、狗、鸡等等,可以从叫声、长相等等特征分析;当然,将这个思想推广到邮件分类问题上,人也可以根据邮件中的具体内容对邮件进行分类判断,例如,如果某封邮件中充斥着:“今天一律五折、期待您的回访、欢迎购买我公司产品”等等句子,很明显这是一封垃圾邮件,那么我们如何让计算机也可以像人一样识别什么样的邮件是垃圾邮件呢?
其实思想很简单,我们人对一封邮件进行分类的依据就是邮件中的关键词,如果某封邮件中多次出现:“天气、心情、生活”等等有关日常问候的词语,我们就可以认为这是一封简单的日常交流的邮件,这并不是一封垃圾邮件,而如果某封邮件中多次出现:“打折、房价、发票”等等无用的词语,我们就可以认为这是一封垃圾邮件。所以我们考虑,是否可以让计算机也可以根据邮件中的关键词对垃圾邮件进行分类呢?答案是可以的,现在我们做如下定义:
- spam表示垃圾邮件
- ham表示非垃圾邮件
- x表示邮件文本内容
- y表示分类结果
如果现在有一封邮件,我们要对其进行分类判断,因为我们现在还不知道这封邮件究竟属于spam,还是属于ham,所以我们需要计算其对于不同类别的后验概率:
- 当输入邮件文本为x时,这封邮件为spam的概率为:
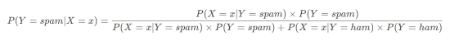
当输入邮件文本为x时,这封邮件为ham的概率为
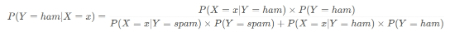
最后如果P(Y=spam∣X=x)的概率值大就表明x xx是一封垃圾邮件,反之表明x xx是一封非垃圾邮件,上面的式子看似计算起来很复杂,但实际他们的分母都是相等的,唯一的区别就是分子,所以可得: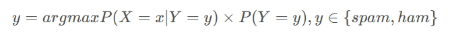
还需要注意的是,x xx虽然是输入的邮件文本,但是已经经过数据预处理、分词、TF-IDF值的计算等步骤的处理成为了邮件文本x xx对应的特征向量,而我们使用的朴素贝叶斯公式默认每个特征都是条件独立的,也就是说特征向量中每个词语的TF-IDF值之间互不影响,所以说上式可以继续化简为: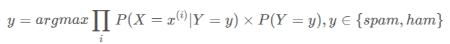
之后就可以训练数据,使用最大似然估计方法计算得到每个关键词的条件概率值P(X=x(i)∣Y=y),而P(Y=y)作为先验概率很容易计算得到。当输入一封新的邮件文本x后就可以对其进行同样的数据处理,然后代入上式得到分类概率值,取最大的分类概率值作为最后的分类结果,就可以判断输入x是垃圾邮件还是非垃圾邮件了。
三、代码实现
3.1 垃圾邮件统计分类代码实现
1.首先导入项目运行所需要的库:
import numpy as np
import matplotlib.pyplot as plt
import re
import jieba
import itertools
import time
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, recall_score
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
2.然后根据index文件获取数据文件的路径和标签,用0和1对标签值进行标记,0代表不是垃圾邮件,1代表是垃圾邮件,最终得到邮件文件路径列表和邮件对应的标签值列表:
def get_path_label():
"""
根据index文件获取数据文件的路径和标签
:return 数据文件路径、数据文件标签
"""
label_path_list = open("data/trec06c/full/index", "r", encoding="gb2312", errors="ignore")
label_path = [data for data in label_path_list]
label_path_split = [data.split() for data in label_path if len(data.split()) == 2]
label_list = [1 if data[0] == "spam" else 0 for data in label_path_split]
path_list = [data[1].replace("..", "trec06c") for data in label_path_split]
return path_list, label_list
3.然后根据上一步得到的邮件文件路径列表获取每个邮件的文本内容,并对其进行简单的处理,如去除特殊字段、换行符等,最终得到每个邮件的正文内容列表。另外,需要注意的是,只有第一次运行的时候需要调用此函数,因为邮件正文只是为了分词使用,而后面我们已经将分词结果保存到本地了,所以使用的时候直接调用即可,不用每次都加载,这样可以节省时间:
def get_data(path_list):
"""
根据数据文件路径打开数据文件,提取每个邮件的正文
:param path_list:
:return 提取的邮件正文
"""
mail = open(path_list, "r", encoding="gb2312", errors="ignore")
mail_text = [data for data in mail]
mail_head_index = [mail_text.index(i) for i in mail_text if re.match("[a-zA-z0-9]", i)]
text = ''.join(mail_text[max(mail_head_index) + 1:])
text = re.sub('\s+', '', re.sub("\u3000", "", re.sub("\n", "", text)))
return text
4.然后加载停用词表,停用词就是一些不重要的词语,比如“啊、它们、没有”等,这些单词不仅对我们最终的判断结果没有帮助,还会消耗存储空间并降低搜索效率,所以我们应该忽略这些词语,加载停用词表的目的就是把刚刚获取到的每一封邮件正文中的停用词删除。另外,此停用词表就在我的项目中,下载项目后就可以直接使用。还有一点需要注意的是,只有第一次运行的时候需要加载停用词表,因为停用词表只在分词的时候使用过,而分词后的结果已经被我保存到本地了,需要使用的时候直接调用本地保存好的分词结果就行,所以不用每次使用都加载停用词表,这样可以节省时间:
def upload_stopword():
"""
加载停用词
:return 返回加载的停用词表
"""
with open("stopwords.txt", encoding="utf-8") as file:
data = file.read()
return data.split("\n")
5.然后使用jieba分词工具将邮件文本分词,因为我们要计算每封邮件中每个词语对这封邮件最终的分类影响,这里需要使用刚才加载的停用词表以去除不需要的词语。这里还需要注意的是,只有第一次使用的时候调用此函数,否则每次分词非常耗时,除了第一次使用,其余测试的时候直接调用保存的分词结果即可,保存好的分词结果已经被我放到项目的主目录了,使用的时候直接调用即可,可以节省时间:
def participle(mail_list, stopword_list):
"""
使用jieba对邮件文本分词
:param mail_list: 邮件文本
:param stopword_list: 停用词表
:return 返回邮件文本分词结果
"""
cur_word_list = []
startTime = time.time()
for mail in mail_list:
cut_word = [data for data in jieba.lcut(mail) if data not in set(stopword_list)]
cur_word_list.append(cut_word)
print("jieba分词用时%0.2f秒" % (time.time() - startTime))
return cur_word_list
6.然后计算邮件文本中词语的词频(TF),也可称为词语出现的频率(Term Frequency)。TF指的是一个词语的重要程度,TF值越高,表明一个词语在邮件中出现的次数越多,也就意味着该词语越重要,反之意味着越不重要。TF的计算公式如下:
上面的计算量看起来很大,但是在Python中实现却很简单,我们只需要使用CountVectorizer()函数就能帮我们完成TF值的计算,最终返回计算好的TF值列表:
def get_TF(cur_word_list):
"""
计算TF
:param cur_word_list: 分词结果列表
:return TF列表
"""
text = [' '.join(data) for data in cur_word_list]
cv = CountVectorizer(max_features=5000, max_df=0.6, min_df=5)
count_list = cv.fit_transform(text)
return count_list
对于CountVectorizer()函数中的参数值简单介绍一下:
- max_features=5000:对TF值降序排序,取前5000个词语作为关键词集
- max_df=0.6:去除在60%的邮件中都出现过的词语,因为出现次数太多,没有区分度
- min_df=5:去除只在5个以下的邮件中出现的词语,因为出现次数太少,没有区分度
7.然后计算邮件文本中词语的IDF(Inverse Document Frequency),也可称为逆文本词频。IDF指的是一个词语在某一封邮件中的区分度,若某个词语只在某封邮件中出现过多次,而在其他邮件中几乎没有出现过,那么就可以认为该词语对这封邮件很重要,也就说明可以通过该词语将此邮件和其他邮件区分开,反之不能进行区分。IDF的计算公式如下:
刚刚我们已经计算得到了TF值,现在我们将TF值与IDF值相乘,就得到了某个词语的TF-IDF值: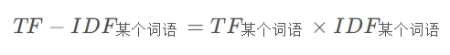
通过计算词语的TF-IDF值,就可以把TF-IDF值高的词语作为邮件的特征属性,因为TF-IDF值不仅仅包括词语重要性的权重,还包括词语区分度的权重,通过结合权重得到特征值,从而降低特征值低的词语的重要性,提高特征值高的词语的重要性,就可以利用这些词语对邮件进行分类。以上的计算步骤看起来可能比较复杂,但是在Python中也只需要两行(甚至一行)就可以完成TF-IDF的计算:
def get_TFIDF(count_list):
"""
计算TF-IDF
:param count_list: 计算得到的TF列表
:return TF-IDF列表
"""
TF_IDF = TfidfTransformer()
TF_IDF_matrix = TF_IDF.fit_transform(count_list)
return TF_IDF_matrix
8.为了可视化展示我们的分类测试结果,我们可以计算一下混淆矩阵(Confusion Matrix),混淆矩阵的每一列代表真实值,每一行代表预测值(也可以自行设置行和列的表示值),通过混淆矩阵我们可以大致观察出训练模型的分类效果:
def plt_confusion_matrix(confusion_matrix, classes, title, cmap=plt.cm.Blues):
"""
绘制混淆矩阵
:param confusion_matrix: 混淆矩阵值
:param classes: 分类类别
:param title: 绘制图形的标题
:param cmap: 绘图风格
"""
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.imshow(confusion_matrix, interpolation="nearest", cmap=cmap)
plt.title(title)
plt.colorbar()
axis_marks = np.arange(len(classes))
plt.xticks(axis_marks, classes, rotation=0)
plt.yticks(axis_marks, classes, rotation=0)
axis_line = confusion_matrix.max() / 2.
for i, j in itertools.product(range(confusion_matrix.shape[0]), range(confusion_matrix.shape[1])):
plt.text(j, i, confusion_matrix[i, j], horizontalalignment="center",
color="white" if confusion_matrix[i, j] > axis_line else "black")
plt.tight_layout()
plt.xlabel("预测结果")
plt.ylabel("真实结果")
plt.show()
9.然后使用贝叶斯分类器对垃圾邮件进行分类,在分类的时候需要使用刚刚计算的TF-IDF矩阵值和标签列表进行训练和测试:
def train_test_Bayes(TF_IDF_matrix_result, label_list):
"""
朴素贝叶斯分类器对于垃圾邮件数据集的训练和测试
:param TF_IDF_matrix_result: TF_IDF值矩阵
:param label_list: 标签列表
:return 无
"""
print(">>>>>>>>>>>>>朴素贝叶斯分类器垃圾邮件分类<<<<<<<<<<<<<")
train_x, test_x, train_y, test_y = train_test_split(TF_IDF_matrix_result, label_list, test_size=0.2, random_state=0)
classifier = MultinomialNB()
startTime = time.time()
classifier.fit(train_x, train_y)
print("贝叶斯分类器训练耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startTime)
score = classifier.score(test_x, test_y)
print("贝叶斯分类器的分类结果准确率>>>>>>>>>>>>>>>>>>>>>>>>>>>", score)
predict_y = classifier.predict(test_x)
print("贝叶斯分类器的召回率>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", recall_score(test_y, predict_y))
plt_confusion_matrix(confusion_matrix(test_y, predict_y), [0, 1], title="贝叶斯分类器混淆矩阵")
- 首先使用train_test_split()进行训练集和测试集的划分,本项目中训练集划分80%,测试集划分20%
- 然后使用MultinomialNB()进行朴素贝叶斯模型训练,其实sklearn库中的 naive_bayes模块实现了五种朴素贝叶斯算法,我们这里选用MultinomialNB(),因为其适用于离散性数据,且符合多项式分布的特征变量,也就是词语的TF-IDF值,另外,MultinomialNB()的默认参数alpha=1,即使用拉普拉斯平滑处理,采用加1的方式,来统计没有出现过的词语的概率,避免因为训练集样本不充分而导致概率计算结果为0的情况,这样得到的概率值更接近真实概率值
- 然后计算模型的准确率
- 然后计算模型的召回率
- 最后使用上面介绍的plt_confusion_matrix()绘制混淆矩阵
10.当我们完成各个子模块的功能后,就可以将这些子模块进行整合,来完成垃圾邮件分类任务了,主函数中各个子模块的调用顺序和上面各个子模块介绍的顺序一致,我只是额外增加了各个子步骤的运行时间计算。另外,需要注意的是,get_data()、upload_stopword()、participle()这三个函数只有第一次运行的时候需要使用,其余的时候注释掉即可,这样可以节省很多时间,因为咱们的训练和测试数据太多了,如果不这么做的话,消耗的时间太长了:
if __name__ == '__main__':
print(">>>>>>>>>>>>>>>>>>>>>>>>垃圾邮件分类系统开始运行<<<<<<<<<<<<<<<<<<<<<<<<")
path_lists, label_lists = get_path_label()
'''
只有第一次运行的时候需要加载,因为后面都已经将分词结果保存到本地了,所以就不用每次都加载邮件文本了,而且停用词表也在分词的时候使用过了,所以也不用每次都加载
'''
# mail_texts = [get_data(path) for path in path_lists]
# stopword_lists = upload_stopword()
'''
将筛选后的数据集分词,并将分词结果保存,只有第一次使用的时候需要将注释打开,否则每次分词非常耗时,除了第一次使用,其余测试的时候直接调用保存的分词结果即可
'''
# cut_word_lists = participle(mail_texts, stopword_lists)
# cut_word_lists = np.array(cut_word_lists)
# np.save("cut_word_lists.npy", cut_word_lists)
startOne = time.time()
cut_word_lists = np.load('cut_word_lists.npy')
print("加载分词文件耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startOne)
startTwo = time.time()
cut_word_lists = cut_word_lists.tolist()
print("转换分词列表耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startTwo)
startThree = time.time()
count_lists = get_TF(cut_word_lists)
print("获取分词TF值耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startThree)
startFour = time.time()
TF_IDF_matrix_results = get_TFIDF(count_lists)
print("获取分词TF-IDF值耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startFour)
startFive = time.time()
train_test_Bayes(TF_IDF_matrix_results, label_lists)
print("贝叶斯分类器训练和预测耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startFive)
11.最后我们可以运行主函数来看一下模型的训练结果:
- 可以看到整个项目运行时间还是蛮快的,如果加上刚才的三个函数时间就会慢很多。当然,时间并不是重点,我们可以观察到,我们的模型的准确率为96%,召回率为97%,这也就意味着我们的模型训练结果还是不错的,这次实验很成功:
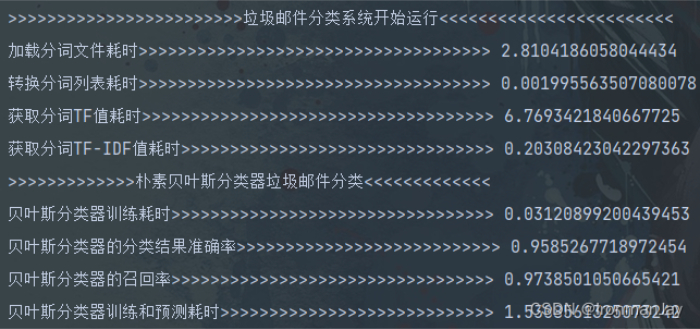
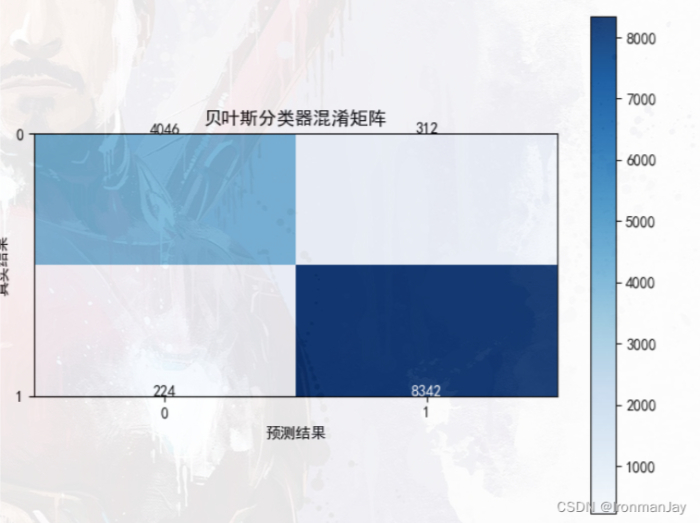
- 我们再来看生成的混淆矩阵,可以看到所有的邮件几乎都分类成功了,这也从可视化的角度证明我们训练的模型的分类准确率非常高:
3.2 垃圾邮件可视化分类代码实现
1.首先导入项目运行所需要的库:
import sys
import re
import jieba
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from PyQt5 import QtCore, QtGui, QtWidgets
from scipy.sparse import csr_matrix
import joblib
2.然后加载停用词表,目的是去除测试文本中的停用词,和上面介绍的一样,不再赘述:```html
def upload_stopword():
"""
加载停用词
:return 返回加载的停用词表
"""
with open("stopwords.txt", encoding="utf-8") as file:
data = file.read()
return data.split("\n")3.然后对测试文本进行预处理并计算TF-IDF值,这部分的处理和上面介绍的过程一样,不再赘述:
def upload_stopword():
"""
加载停用词
:return 返回加载的停用词表
"""
with open("stopwords.txt", encoding="utf-8") as file:
data = file.read()
return data.split("\n")4.然后直接调用训练好的模型进行测试,我已经将训练好的模型保存到项目的主目录了。当然,读者也可以使用自己训练的模型测试,具体方法自行搜索,比较简单,因为这部分内容不是本篇博客重点,所以不在此赘述:
def predict_res(mail):
"""
使用训练好的模型对传入的测试邮件进行分类预测
:param mail: 待测试邮件
:return: 分类预测结果
"""
classifier = joblib.load("model/classifier.pkl")
res = classifier.predict(mail)
return res
5.然后绘制测试窗口,这部分内容也不是本篇博客的重点内容,所以也不在此赘述,唯一需要介绍的就是my_func()函数,my_func()函数的作用是调用上面介绍的各个子模块,返回得到预测结果,最终将预测结果显示在窗口上:
class Ui_Dialog(object):
"""
垃圾邮件分类的可视化展示
"""
def __init__(self):
"""
初始化参数
"""
self.pushButton_2 = None
self.pushButton = None
self.horizontalLayout = None
self.plainTextEdit_2 = None
self.plainTextEdit = None
self.horizontalLayout_2 = None
self.verticalLayout = None
self.verticalLayout_2 = None
def setupUi(self, Dialog):
"""
绘制垃圾邮件分类的UI界面
:param Dialog: 当前对话窗口
"""
Dialog.setObjectName("基于朴素贝叶斯的垃圾邮件过滤系统")
Dialog.resize(525, 386)
self.verticalLayout_2 = QtWidgets.QVBoxLayout(Dialog)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.verticalLayout = QtWidgets.QVBoxLayout()
self.verticalLayout.setObjectName("verticalLayout")
self.horizontalLayout_2 = QtWidgets.QHBoxLayout()
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.plainTextEdit = QtWidgets.QPlainTextEdit(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(12)
self.plainTextEdit.setFont(font)
self.plainTextEdit.setObjectName("plainTextEdit")
self.horizontalLayout_2.addWidget(self.plainTextEdit)
self.plainTextEdit_2 = QtWidgets.QPlainTextEdit(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(12)
self.plainTextEdit_2.setFont(font)
self.plainTextEdit_2.setObjectName("plainTextEdit_2")
self.horizontalLayout_2.addWidget(self.plainTextEdit_2)
self.verticalLayout.addLayout(self.horizontalLayout_2)
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
self.pushButton = QtWidgets.QPushButton(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(16)
self.pushButton.setFont(font)
self.pushButton.setObjectName("pushButton")
self.horizontalLayout.addWidget(self.pushButton)
self.pushButton_2 = QtWidgets.QPushButton(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(16)
self.pushButton_2.setFont(font)
self.pushButton_2.setObjectName("pushButton_2")
self.horizontalLayout.addWidget(self.pushButton_2)
self.verticalLayout.addLayout(self.horizontalLayout)
self.verticalLayout_2.addLayout(self.verticalLayout)
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
self.pushButton.clicked.connect(self.my_func)
def retranslateUi(self, Dialog):
"""
绘制当前窗口的按钮
:param Dialog: 当前对话窗口
"""
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "Dialog"))
self.pushButton.setText(_translate("Dialog", "确定"))
self.pushButton_2.setText(_translate("Dialog", "清空"))
self.pushButton_2.clicked.connect(self.plainTextEdit.clear)
self.pushButton_2.clicked.connect(self.plainTextEdit_2.clear)
def my_func(self):
"""
调用各个功能模块
"""
stopword_lists = upload_stopword()
mail = self.plainTextEdit.toPlainText()
mail_handle = handle_mail(mail, stopword_lists)
res = predict_res(mail_handle)
show_res = None
if res[0] == 1:
show_res = "这是垃圾邮件"
else:
show_res = "这不是垃圾邮件"
self.plainTextEdit_2.setPlainText(show_res)
6.然后直接使用主函数调用上面介绍的绘制窗口的模块即可(预测功能模块已经嵌入到绘制窗口模块中了):
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
Dialog = QtWidgets.QDialog()
ui = Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
sys.exit(app.exec_())
7.最后我们可以运行一下主函数,来看一下运行效果:
当我们输入一段非垃圾邮件的时候,窗口输出“这不是垃圾邮件”,表明预测成功: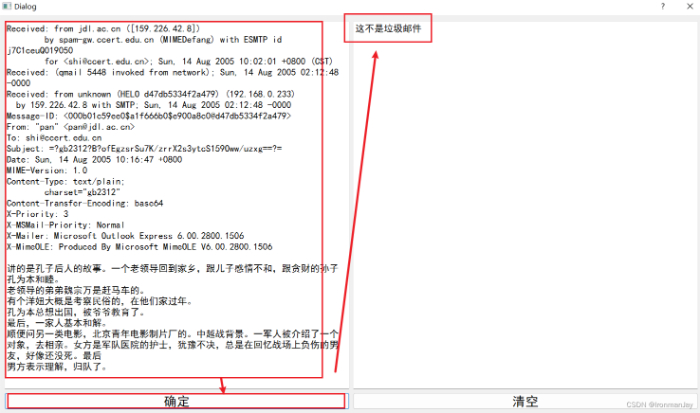
当我们输入一段垃圾邮件的时候,窗口输出“这是垃圾邮件”,表明预测成功: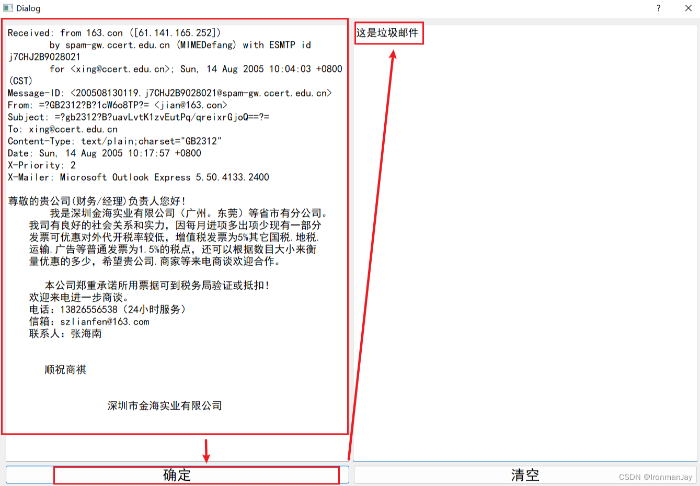
四、亟待解决的问题
目前看来我们的模型训练效果还不错,但是还是存在问题,当我们在进行可视化的邮件分类的时候,需要输入一封测试邮件,我们需要计算这封测试邮件分词后的TF-IDF值。但是之前我们在进行模型的训练和测试的时候,由于总数据量非常大,所以我们设定的维度为5000维,也就是取TF-IDF值降序后的前5000个单词作为关键词集,而我们输入的测试邮件肯定达不到5000维,也就导致无法进行预测。
为了解决这个问题,我能想到的办法就是使用csr_matrix()函数和shape()函数对计算得到的测试邮件的TF-IDF值进行维度扩充,将其维度扩充到5000维:
TF_IDF_matrix_res = csr_matrix((TF_IDF_matrix.data, TF_IDF_matrix.indices, TF_IDF_matrix.indptr), shape=(1, 5000))
这样虽然可以成功输出预测分类值,但是测试分类的结果总是很差,但是我目前也没有想到更好的办法去解决这个问题,如果各位读者有好的办法,欢迎随时和我交流!
五、全部代码
5.1 垃圾邮件统计分类全部代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:IronmanJay
# email:1975686676@qq.com
# 导入程序运行必需的库
import numpy as np
import matplotlib.pyplot as plt
import re
import jieba
import itertools
import time
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, recall_score
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
def get_path_label():
"""
根据index文件获取数据文件的路径和标签
:return 数据文件路径、数据文件标签
"""
label_path_list = open("data/trec06c/full/index", "r", encoding="gb2312", errors="ignore")
label_path = [data for data in label_path_list]
label_path_split = [data.split() for data in label_path if len(data.split()) == 2]
label_list = [1 if data[0] == "spam" else 0 for data in label_path_split]
path_list = [data[1].replace("..", "trec06c") for data in label_path_split]
return path_list, label_list
def get_data(path_list):
"""
根据数据文件路径打开数据文件,提取每个邮件的正文
:param path_list:
:return 提取的邮件正文
"""
mail = open(path_list, "r", encoding="gb2312", errors="ignore")
mail_text = [data for data in mail]
mail_head_index = [mail_text.index(i) for i in mail_text if re.match("[a-zA-z0-9]", i)]
text = ''.join(mail_text[max(mail_head_index) + 1:])
text = re.sub('\s+', '', re.sub("\u3000", "", re.sub("\n", "", text)))
return text
def upload_stopword():
"""
加载停用词
:return 返回加载的停用词表
"""
with open("stopwords.txt", encoding="utf-8") as file:
data = file.read()
return data.split("\n")
def participle(mail_list, stopword_list):
"""
使用jieba对邮件文本分词
:param mail_list: 邮件文本
:param stopword_list: 停用词表
:return 返回邮件文本分词结果
"""
cur_word_list = []
startTime = time.time()
for mail in mail_list:
cut_word = [data for data in jieba.lcut(mail) if data not in set(stopword_list)]
cur_word_list.append(cut_word)
print("jieba分词用时%0.2f秒" % (time.time() - startTime))
return cur_word_list
def get_TF(cur_word_list):
"""
计算TF
:param cur_word_list: 分词结果列表
:return TF列表
"""
text = [' '.join(data) for data in cur_word_list]
cv = CountVectorizer(max_features=5000, max_df=0.6, min_df=5)
count_list = cv.fit_transform(text)
return count_list
def get_TFIDF(count_list):
"""
计算TF-IDF
:param count_list: 计算得到的TF列表
:return TF-IDF列表
"""
TF_IDF = TfidfTransformer()
TF_IDF_matrix = TF_IDF.fit_transform(count_list)
return TF_IDF_matrix
def plt_confusion_matrix(confusion_matrix, classes, title, cmap=plt.cm.Blues):
"""
绘制混淆矩阵
:param confusion_matrix: 混淆矩阵值
:param classes: 分类类别
:param title: 绘制图形的标题
:param cmap: 绘图风格
"""
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.imshow(confusion_matrix, interpolation="nearest", cmap=cmap)
plt.title(title)
plt.colorbar()
axis_marks = np.arange(len(classes))
plt.xticks(axis_marks, classes, rotation=0)
plt.yticks(axis_marks, classes, rotation=0)
axis_line = confusion_matrix.max() / 2.
for i, j in itertools.product(range(confusion_matrix.shape[0]), range(confusion_matrix.shape[1])):
plt.text(j, i, confusion_matrix[i, j], horizontalalignment="center",
color="white" if confusion_matrix[i, j] > axis_line else "black")
plt.tight_layout()
plt.xlabel("预测结果")
plt.ylabel("真实结果")
plt.show()
def train_test_Bayes(TF_IDF_matrix_result, label_list):
"""
朴素贝叶斯分类器对于垃圾邮件数据集的训练和测试
:param TF_IDF_matrix_result: TF_IDF值矩阵
:param label_list: 标签列表
:return 无
"""
print(">>>>>>>>>>>>>朴素贝叶斯分类器垃圾邮件分类<<<<<<<<<<<<<")
train_x, test_x, train_y, test_y = train_test_split(TF_IDF_matrix_result, label_list, test_size=0.2, random_state=0)
classifier = MultinomialNB()
startTime = time.time()
classifier.fit(train_x, train_y)
print("贝叶斯分类器训练耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startTime)
score = classifier.score(test_x, test_y)
print("贝叶斯分类器的分类结果准确率>>>>>>>>>>>>>>>>>>>>>>>>>>>", score)
predict_y = classifier.predict(test_x)
print("贝叶斯分类器的召回率>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", recall_score(test_y, predict_y))
plt_confusion_matrix(confusion_matrix(test_y, predict_y), [0, 1], title="贝叶斯分类器混淆矩阵")
if __name__ == '__main__':
print(">>>>>>>>>>>>>>>>>>>>>>>>垃圾邮件分类系统开始运行<<<<<<<<<<<<<<<<<<<<<<<<")
path_lists, label_lists = get_path_label()
'''
只有第一次运行的时候需要加载,因为后面都已经将分词结果保存到本地了,所以就不用每次都加载邮件文本了,而且停用词表也在分词的时候使用过了,所以也不用每次都加载
'''
# mail_texts = [get_data(path) for path in path_lists]
# stopword_lists = upload_stopword()
'''
将筛选后的数据集分词,并将分词结果保存,只有第一次使用的时候需要将注释打开,否则每次分词非常耗时,除了第一次使用,其余测试的时候直接调用保存的分词结果即可
'''
# cut_word_lists = participle(mail_texts, stopword_lists)
# cut_word_lists = np.array(cut_word_lists)
# np.save("cut_word_lists.npy", cut_word_lists)
startOne = time.time()
cut_word_lists = np.load('cut_word_lists.npy')
print("加载分词文件耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startOne)
startTwo = time.time()
cut_word_lists = cut_word_lists.tolist()
print("转换分词列表耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startTwo)
startThree = time.time()
count_lists = get_TF(cut_word_lists)
print("获取分词TF值耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startThree)
startFour = time.time()
TF_IDF_matrix_results = get_TFIDF(count_lists)
print("获取分词TF-IDF值耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startFour)
startFive = time.time()
train_test_Bayes(TF_IDF_matrix_results, label_lists)
print("贝叶斯分类器训练和预测耗时>>>>>>>>>>>>>>>>>>>>>>>>>>>>", time.time() - startFive)
5.2 垃圾邮件可视化分类全部代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:IronmanJay
# email:1975686676@qq.com
# 导入程序运行必需的库
import sys
import re
import jieba
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from PyQt5 import QtCore, QtGui, QtWidgets
from scipy.sparse import csr_matrix
import joblib
def upload_stopword():
"""
加载停用词
:return 返回加载的停用词表
"""
with open("stopwords.txt", encoding="utf-8") as file:
data = file.read()
return data.split("\n")
def handle_mail(mail, stopword_list):
"""
对邮件文本预处理,并计算其TF-IDF值,最后返回TF-IDF值矩阵
:param mail: 待检测的邮件文本
:param stopword_list: 停用词列表
:return TF-IDF值矩阵
"""
'''
处理邮件文本的邮件头以及空格、换行等等
'''
mail_head_index = [mail.index(i) for i in mail if re.match("[a-zA-z0-9]", i)]
mail_res = ''.join(mail[max(mail_head_index) + 1:])
mail_res = re.sub('\s+', '', re.sub("\u3000", "", re.sub("\n", "", mail_res)))
'''
对邮件文本进行分词处理
'''
cut_word = [data for data in jieba.lcut(mail_res) if data not in set(stopword_list)]
'''
计算邮件本文的TF-IDF值
'''
text = [' '.join(cut_word)]
cv = CountVectorizer()
TF_IDF = TfidfTransformer()
TF_IDF_matrix = TF_IDF.fit_transform(cv.fit_transform(text))
TF_IDF_matrix_res = csr_matrix((TF_IDF_matrix.data, TF_IDF_matrix.indices, TF_IDF_matrix.indptr), shape=(1, 5000))
return TF_IDF_matrix_res
def predict_res(mail):
"""
使用训练好的模型对传入的测试邮件进行分类预测
:param mail: 待测试邮件
:return: 分类预测结果
"""
classifier = joblib.load("model/classifier.pkl")
res = classifier.predict(mail)
return res
class Ui_Dialog(object):
"""
垃圾邮件分类的可视化展示
"""
def __init__(self):
"""
初始化参数
"""
self.pushButton_2 = None
self.pushButton = None
self.horizontalLayout = None
self.plainTextEdit_2 = None
self.plainTextEdit = None
self.horizontalLayout_2 = None
self.verticalLayout = None
self.verticalLayout_2 = None
def setupUi(self, Dialog):
"""
绘制垃圾邮件分类的UI界面
:param Dialog: 当前对话窗口
"""
Dialog.setObjectName("基于朴素贝叶斯的垃圾邮件过滤系统")
Dialog.resize(525, 386)
self.verticalLayout_2 = QtWidgets.QVBoxLayout(Dialog)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.verticalLayout = QtWidgets.QVBoxLayout()
self.verticalLayout.setObjectName("verticalLayout")
self.horizontalLayout_2 = QtWidgets.QHBoxLayout()
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.plainTextEdit = QtWidgets.QPlainTextEdit(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(12)
self.plainTextEdit.setFont(font)
self.plainTextEdit.setObjectName("plainTextEdit")
self.horizontalLayout_2.addWidget(self.plainTextEdit)
self.plainTextEdit_2 = QtWidgets.QPlainTextEdit(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(12)
self.plainTextEdit_2.setFont(font)
self.plainTextEdit_2.setObjectName("plainTextEdit_2")
self.horizontalLayout_2.addWidget(self.plainTextEdit_2)
self.verticalLayout.addLayout(self.horizontalLayout_2)
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
self.pushButton = QtWidgets.QPushButton(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(16)
self.pushButton.setFont(font)
self.pushButton.setObjectName("pushButton")
self.horizontalLayout.addWidget(self.pushButton)
self.pushButton_2 = QtWidgets.QPushButton(Dialog)
font = QtGui.QFont()
font.setFamily("SimHei")
font.setPointSize(16)
self.pushButton_2.setFont(font)
self.pushButton_2.setObjectName("pushButton_2")
self.horizontalLayout.addWidget(self.pushButton_2)
self.verticalLayout.addLayout(self.horizontalLayout)
self.verticalLayout_2.addLayout(self.verticalLayout)
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
self.pushButton.clicked.connect(self.my_func)
def retranslateUi(self, Dialog):
"""
绘制当前窗口的按钮
:param Dialog: 当前对话窗口
"""
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "Dialog"))
self.pushButton.setText(_translate("Dialog", "确定"))
self.pushButton_2.setText(_translate("Dialog", "清空"))
self.pushButton_2.clicked.connect(self.plainTextEdit.clear)
self.pushButton_2.clicked.connect(self.plainTextEdit_2.clear)
def my_func(self):
"""
调用各个功能模块
"""
stopword_lists = upload_stopword()
mail = self.plainTextEdit.toPlainText()
mail_handle = handle_mail(mail, stopword_lists)
res = predict_res(mail_handle)
show_res = None
if res[0] == 1:
show_res = "这是垃圾邮件"
else:
show_res = "这不是垃圾邮件"
self.plainTextEdit_2.setPlainText(show_res)
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
Dialog = QtWidgets.QDialog()
ui = Ui_Dialog()
ui.setupUi(Dialog)
Dialog.show()
sys.exit(app.exec_())



评论(0)
您还未登录,请登录后发表或查看评论