

一、BN层的作用,工作原理?
在模型训练过程中,批量规范化利用小批量的均值和和方差,不断调整神经网络的中间输出(让数据分布变得一致),使整个神经网络各层的中间输出值更加稳定。(BN的作用)
在原论文中,作者提出的解释是,减少内部协变量偏移(internal covariate shift),所以使得最终的训练结果更稳定。实际上,这个方法的解释是不确切的,BN所带来的好处,更多是归一化引起的。
二、内部协变量偏移
先来说一下内部协变量偏移的概念:表示数据的分布在网络传播过程中会发生偏移。
更具体的来说,深度神经网络涉及很多层神经元的叠加,每一层的参数变化会导致上一层的输入数据分布发生变化,通过层层叠加,高层的输入分布会变化的非常剧烈,这使得高层需要不断重新适应底层的参数变化。这一现象也就是内部协变量偏移。
所以需要进行一些放缩和拉伸,来缓解这种现象。
这里有一个例子来解释它(我感觉这个例子有点牵强),假设我们有一个玫瑰花的深度学习网络,这是一个二分类的网络,1表示识别为玫瑰,0则表示非玫瑰花。我们先看看训练数据集的一部分:

上图所示,所有的玫瑰花都是红色的,这样会导致模型认为只要是红色的就是玫瑰花。

而这幅图玫瑰花是五颜六色的,其特征分布与上图是不一致的。通俗的讲,就是刚开始模型已经适应了红色就是玫瑰的这种分布,突然有来了五颜六色的玫瑰,会使得模型有点很难接受,从而影响模型的收敛速度和精度,这也就是内部协变量偏移(internal covariate shift)。而BN过程中会训练两个标量参数,拉伸gamma和偏移beta。BN就是将这些输入值进行一个归一化的操作,将其放缩到合适的范围,从而加快训练速度。
参考博客:https://www.cnblogs.com/itmorn/p/11241236.html#ct6
三、归一化带来的影响
归一化,归纳统一样本的统计分布性。归一化可以使得后边数据处理更加方便,程序收敛速度加快,统一量纲。
如下图所示,左图是未归一化的求最优解的过程,右图是经过归一化后的求解最优解的过程。
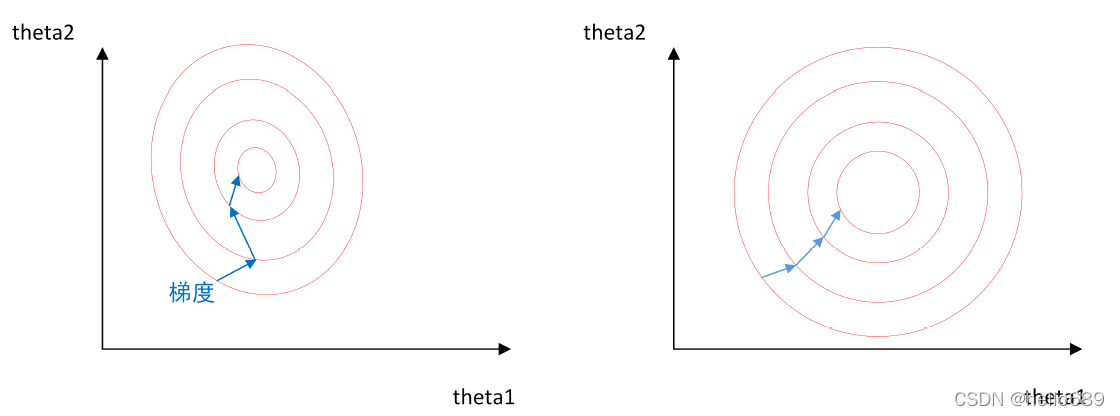
从图中很明显可以看出来,当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
归一化类型:
- 线性归一化,用max值和min值来归一化,如果max和min不稳定,那么结果也不稳定。
- 标准差归一化,经过处理的数据符合标准正态分布,BN里边用的就是这个
- 非线性归一化,通过数学函数,对原始值进行一个映射,如log、指数等。
四、BN层的工作阶段
批量规范化一般用在全连接层和卷积层。使用略有不同
- 对于卷积层来说,BN可以用在卷积层之后,非线性激活函数之前;
- 对于全连接层来说,BN置于全连接层的仿射变换和激活函数之间;

更形象化的操作流程可参考https://www.cnblogs.com/itmorn/p/11241236.html#ct6
BN的算法流程
输入,X = x_1,x_2,…,x_m学习参数\gamma, \beta
- 计算上一层输出数据的均值;
- 计算上一层输出数据的标准差;
- 归一化处理,为了避免分母为0,加进去一个很小的值;
- 重构分布(放缩和拉伸),y_i = \gamma * 第3步得到的值 + \betay 。
为什么归一化之后还要进行放缩和偏移?
减均值除方差可以得到的分布式正态分布。还以玫瑰花为例,如果都是玫瑰花,那么减均值之后为0,分布都在0处,通过放缩和偏移,改变分布,使模型训练更稳定。
train和eval下的计算方式有什么不同?
下图为某个网络在训练时的报错信息。在训练模式下,batchsize设置为4,使用4块显卡,分布式训练。显示出现了batch_size为1的情况,从而导致代码抛出异常(这里猜测可能是因为数据并行,每块卡分了一个batch)。因为源代码设置过,在训练模式下,BN的计算batch是不能为1的,BN是要批量数据的方差和平均差的 。
在训练过程中,我们无法得知使⽤整个数据集来估计平均值和⽅差,所以只能根据每个小批次的平均值和⽅差不断训练模型。而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和⽅差。

五、代码
下边是沐神的动手学深度学习中的BN实现代码。
import torch
from torch import nn
from d2l import torch as d2l
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使⽤传⼊的移动平均所得的均值和⽅差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使⽤全连接层的情况,计算特征维上的均值和⽅差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使⽤⼆维卷积层的情况,计算通道维上(axis=1)的均值和⽅差。
# 这⾥我们需要保持X的形状以便后⾯可以做⼴播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,⽤当前的均值和⽅差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和⽅差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data



评论(0)
您还未登录,请登录后发表或查看评论