

如何从语言模型中获得Text embedding呢?
a) 将模型最后一层[CLS]位置的向量表征直接作为句向量。
b) 将模型最后一层[CLS]位置的向量表征,再经过MLP层得到的向量。
c) 将模型最后一层所有位置的向量表征,再经过一个Pooling层得到的向量。(大部分情况下采用的是mean pooling,在有些情况下也会使用max pooling等其他方式)
d) 将模型最后一层所有位置的向量表征,再经过一个Pooling层跟MLP层得到的向量。
相关模型: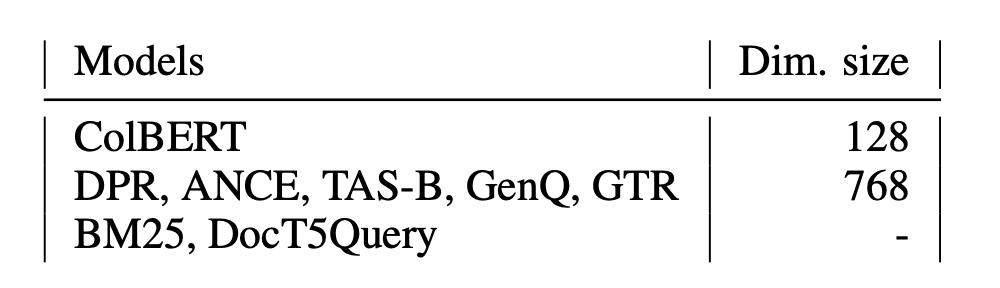
T5
核心思想:将所有 NLP 任务都转化成 Text-to-Text (文本到文本)任务,用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务
-
那么如何转化?加指令头就行了
自监督预训练的方法主要有三种:
-
语言模型式,就是 GPT-2 那种方式,从左到右预测
-
BERT-style 式,就是像 BERT 一样将一部分给破坏掉,然后还原出来(
最佳方式,15 % mask比例) -
Deshuffling (顺序还原)式,就是将文本打乱,然后还原出来
文本一部分进行破坏时的策略:
-
Mask 法,如现在大多模型的做法,将被破坏 token 换成特殊符如 [M];
-
Span(小段替换)法,可以把它当作是把上面 Mask 法中相邻 [M] 都合成了一个特殊符,每一小段替换一个特殊符,提高计算效率;(
最佳方式,span长度为3) -
Drop 法,没有替换操作,直接随机丢弃一些字符。
sentence-T5
-
T5-encoder + mean pooling,经过两阶段的训练得到了sentence-T5
两个阶段采用的都是对比学习
-
第一阶段是在无人工标注的十亿级别的庞大语料上做预训练(无监督对比学习)
-
第二阶段则是在有人工标注的十万级别的高质量NLI语料上作进一步finetune得到(有监督对比学习)
GTR
-
sentence-T5的架构不变,将finetune的数据集从NLI换成检索相关的
-
in-batch sampled softmax loss: 没有hard-negative就加大batch-size
-
bi-directional in-batch sampled softmax loss :正向损失是question和document的配对,反向损失数 document和question的匹配
-
正向损失以query为中心去构建正负样本
-
反向损失以positive document为中心去构建正负样本
BEIR的结论:使用余弦相似度度量训练的模型会偏向于检索出短文档,而使用点积相似度训练的模型会偏向于检索出长文档
But:当模型尺寸变大时,某些数据集的平均召回长度会变长
Instructor Embedding
核心:加入指令数据,正负样本的构造方法
-
加入指令数据四元组( x , I x , y , I y ) (x, I_x, y, I_y)(x,Ix,y,Iy)
I x I_xIx is “Represent the Wikipedia question for retrieving supporting documents; Input: ,”
I y I_yIy is “Represent the Wikipedia document for retrieval; Input: .”
相似度的计算:余弦相似度,Embedding是GTR models(T5 based)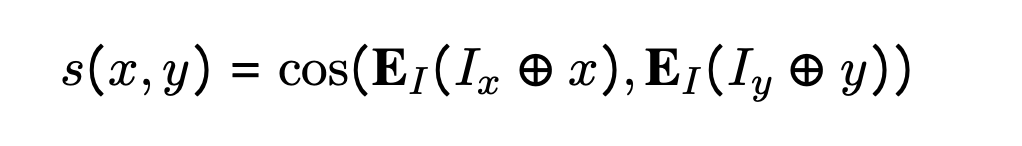
-
Loss的计算

BGE
自动编码+对比学习
自动编码任务有两个要求:
1)其一是重建任务需要足够难,从而迫使模型去生成高质量的句向量
2)其二是能够充分利用训练数据。
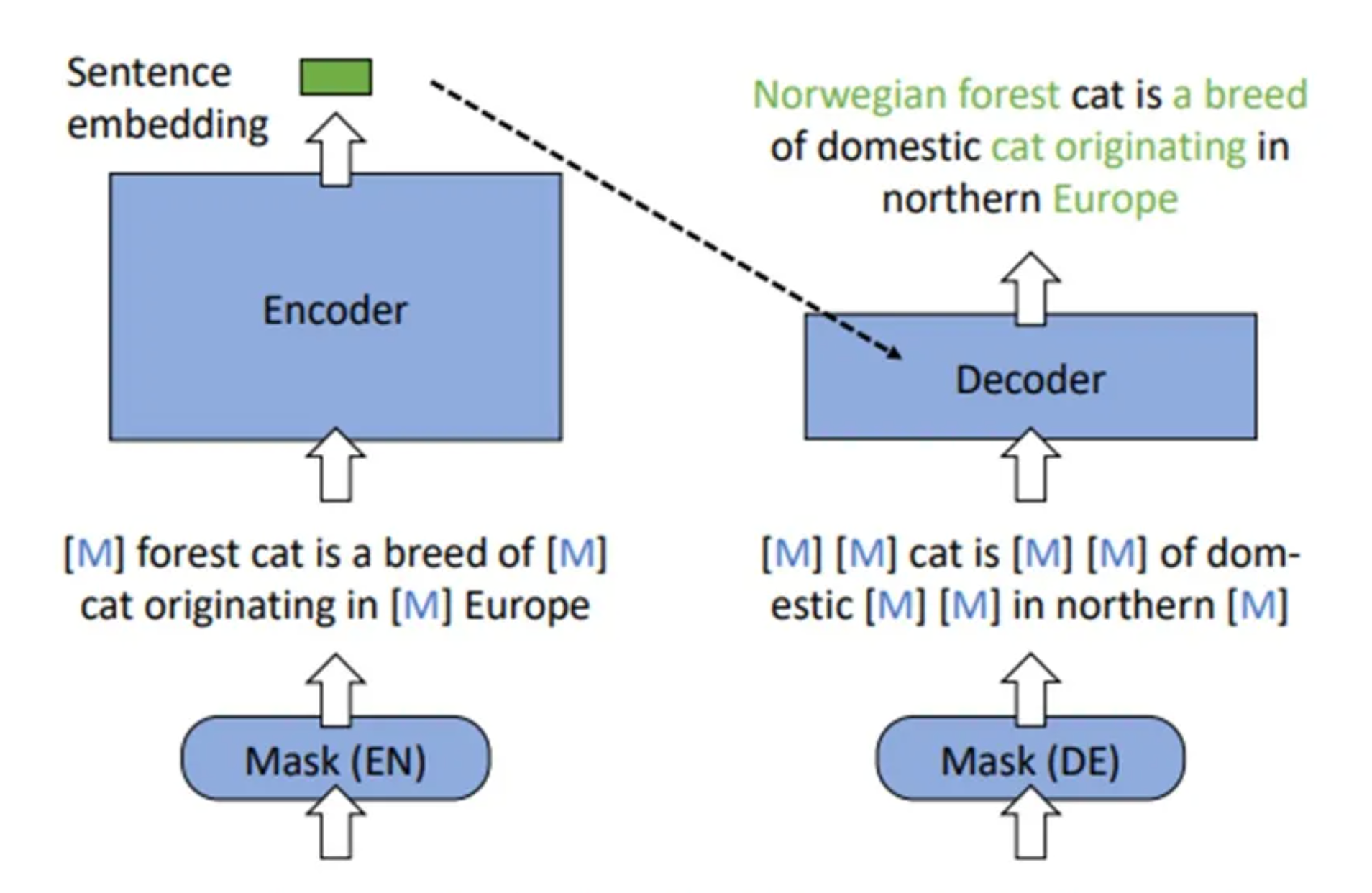
RetroMAE的预备训练方案
-
模型架构:
包括一个以Bert为基底的Encoder + 一个只有一层的Decoder -
Encoder端:
训练时,Encoder端以30%的比例对原文本进行mask,最终得到最后一层[CLS]位置的向量表征作为句向量 -
Decoder端:
以50%的比例对原文本进行mask,联合Encoder端的句向量,对原本进行重建 -
基于RetroMAE+key word的RetorMAE-2的方案在22年底已经提出,但是目前没有基于此的text embedding模型开源。
-
BGE在finetune阶段针对检索任务需要加入特定的Prefix(只在query侧加"Represent this sentence for searching relevant passages:")。
-
猜想:自动编码+有监督对比学习+无监督对比学习,语言模型先在没有pair对的数据上以自动编码的任务做预训练,然后再在没有人工标注的数据上做对比学习,最后再在有人工标注的数据上做进一步finetune。



评论(0)
您还未登录,请登录后发表或查看评论