

1 野值与内点
在SLAM系统计算两幅图像之间的单应矩阵时,如果使用间接法提取两幅图像的特征点,并对两幅图像的特征点进行匹配,得到对应集{x_i \leftrightarrow x_i^{‘} },x_i和x_i^’分别为两副图像的特征点坐标。由于获得了匹配特征点,故我们可以利用其进行单应矩阵的估算,这种方法也被称为间接法。
但是由于对应集存在一定的位置测量误差,在实际运行中经常由于点的错配而导致单应矩阵估计失效,这种问题在动态SLAM系统中更为明显。

图 1: 具有运动物体的环境
当相邻两幅图像中都有动态物体进行干扰时,我们会非常容易将特征点提取在这些动态物体上(尤其是穿格子衫的人),利用这些特征点进行单应矩阵估计会严重影响结果的质量。这些错配点则被称为野值,应该加以识别。因此我们希望,当使用间接法时,可以排除掉野值,获得“对应”中的内点集,使得我们能够在这些内点中用最佳方式估计系统的位姿。RANSAC正是其中的一种方法。
2 RANSAC原理
RANSAC全名为RANdom SAmple Consensus,一般译作随机抽样一致算法,是一种通用且非常成功的估计算法,它能够应付大比例野值的情况。为了可视化,我们先考虑一个简单的例子,估计一组二维点的直线拟合。具体问题可以看图2。
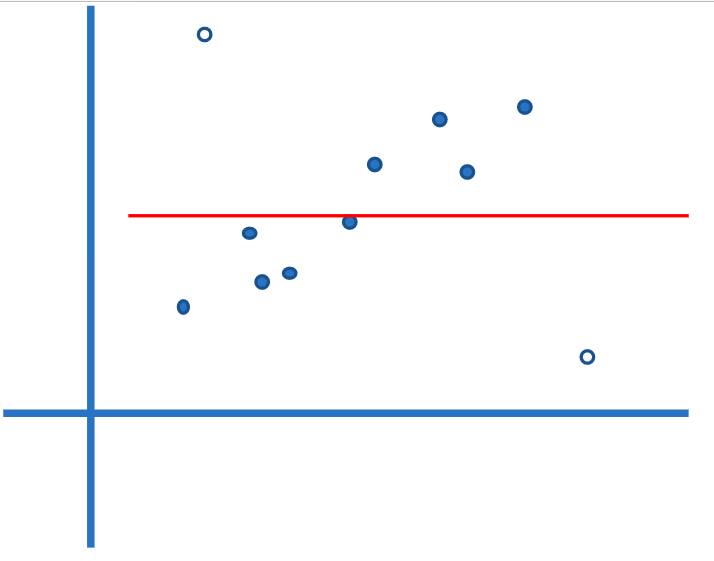
图 2: 二维点直线拟合
可能有点读者开始困惑了,在上一节介绍RANSAC就是两幅图像中的错配点的一种方法,怎么到第二节就变成直线拟合了呢?其实我们可以这样考虑,在第一幅图中的特征点都共同落在了一条直线上,在经过仿射变换(也可以是更复杂的射影变换)后,由于这种变换具有保线性(射影变换亦是),那么第二幅图中对应的特征点也理所当然地应该落在某条直线上,所以从这个角度上看,我们的工作其实与直线拟合是没有曲边的,即二维平面上的某条直线(可以假想成X轴)上的点,经过射影变换以后变成了同一个平面内的另一条直线上的匹配点,而RANSAC的目的就是排除掉那些在变换过程中出错了的那些野值点(图1中的空心点)。
算法的思想非常简单,如果此前了解或者学习过SVM的读者,在看到这句话以后估计就秒懂了。由于是直线拟合,故我们可以随机选择两个点,这两点定义一条直线,这条线的支集由在一定距离阈值内的点数来度量,随机采样重复多次,具有最大支集的线就是鲁棒拟合,而此时在距离阈值内的点就是内点,并组成一致集。
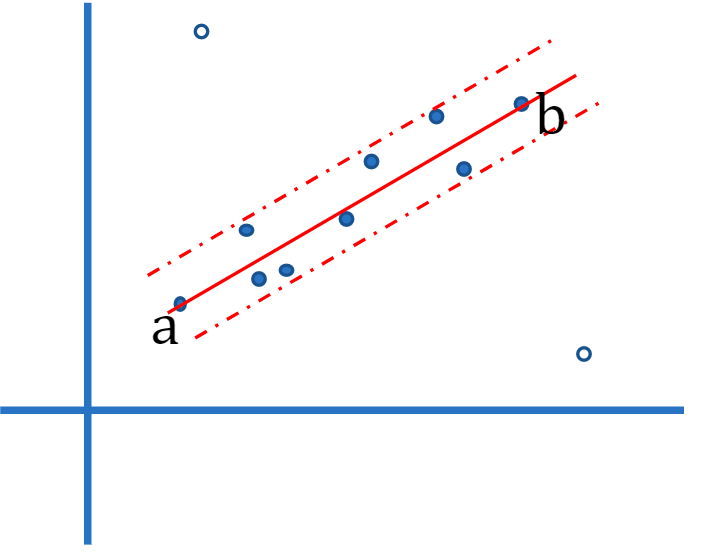
图 3: 直线的鲁棒拟合
图3是图2中的一条鲁棒的拟合直线,我们选定的线<a,b>的支集有9个点,它是点数最高的直线之一,通过点数度量可以让我们排除掉直线外的野值点。更一般地说,我们希望用模型去拟合数据,随机采样包含足以确定模型的最小数据集。</a,b>
算法的思路已经讲清楚了,但是仍然还有许多细节需要处理,主要的问题有三个:1.距离阈值如何选定?2.采样次数要多少?3.一致集的大小怎么决定?下面将具体展开讨论。
2.1 距离阈值
细心的读者可能会发现,距离阈值的选择会很大程度影响算法的效果。我们假定点的位置测量误差服从高斯分布,同样我们选择的距离阈值t使得点为内点的概率为\alpha,那么我们就需要知道内点到拟合直线的距离的概率分布。为了定量分析,我们可以假定误差是均值为0方差为\sigma^2的高斯分布,那么我们就可以算出t的值。此时点到直线距离的平方d_{\perp}^2服从自由度为m的\chi_m^2分布,m为模型的余维度,对于直线来说余维度为1,它仅与点到直线的距离有关,如果模型是一个点,则余维度为2,它与点的x和y坐标有关。随机变量\chi_m^2小于k^2的概率可根据\chi_m^2的分布函数计算得出\int_0^{k^{2}}\chi_m^2(\xi)d\xi。由分布函数可以得到
内点 \qquad d_{\perp}^2 < t^2
野值 \qquad d_{\perp}^2 \ge t^2
其中t^2={F_m}^{-1}(\alpha){\sigma}^2。如果取\alpha=0.95,即点为内点的概率为95%,表明内点被误认为野值的概率为5%,有关模型取\alpha=0.95,t的值在下表中列出。

2.2 采样次数
在匹配特征点比较少的时候,利用遍历法可以轻易找出最优解,然而在实际运行当中,几百个匹配特征点实在是太正常不过了,而且这仅仅只是相邻两帧图片的匹配而已,当采集的数据越多,采样次数呈现O(n^2)的趋势,这时就不得不考虑成本问题了。尝试每个可能的样本既不可行也不必要,我们只要保证采样次数N足够大,由s个点组成的随机样本中至少有一次没有野值的概率能够让我接受即可,就像2.1距离阈值的选择一样。我们假设至少有一次没有野值的概率为p,通常取0.99。假定ω是任意选择的数据点为内点的概率,那么\epsilon=1-\omega是其为野值的概率。那么至少需要N次选择(每次s个点),其中(1-\omega^s)^N=1-p,从而有N=\frac{log(1-p)}{log(1-(1-\epsilon)^s)}
2.3 一致集的大小
算法中,在给定野值的假定比例后,如果一致集的大小接近期望属于该数据集的内点时迭代停止,即T=(1-\epsilon)n。
至此我们已经可以给出RANSAC的算法基本流程,如下:
1.给定野值比例\epsilon,计算采样次数N与一致集的期望大小T
2. 从S中随机选择s个数据点组成一个样本
3. 确定在模型距离阈值t内的数据点集S_i,S_i即为前述的一致集
4. 如果S_i大小大于T,则停止迭代,得到最大一致集
5. 如果S_i大小小于T,则从步骤(2)重新开始
6. 经过N次实验选择其中的最大一致集作为拟合结果1.
3 自适应采样RANSAC与实践
3.1 自适应原理
数据中的野值比例ε通常是未知的,也并不是固定的,会随着SLAM系统拍摄到不同场景而改变,将野值比例设为定值显然是不合适的。一种自适应的RANSAC可以避免这种窘境,我们只需设定最坏的野值比例和初始的采样次数N即可,假设ε为50%(设为100%也无妨),N为\infty。当我们发现一个一致集包含了大于50%的数据时,那么我们知道野值比例应该是低于50%的,那么我们就可以用当前的野值比例去更新N(利用2.2节的公式)。每当发现一致集的\epsilon达到新低就更新N,N就能减少。当完成N次采样,算法就终止,剩余的步骤可仿照上一节的RANSAC流程,给出自适应采样RANSAC算法,如下:
- N=∞,实验次数count=0
- 当N大于count时,仿照RANSAC基本算法步骤(2)~(5)
- 当N=count时,算法终止,取最大一致集
3.2 代码实践
出于易读性的需要,我们选择使用Matlab作为实验上手的平台,相信做过机器人或者图像分析的各位也必然是学习过的。
首先,先设定我们的实验,本实验是计算两幅图像之间的单应矩阵,我这里选择自己生成实验数据,将第一幅图像中的两条直线的数据点,通过一个单应矩阵转移到第二幅图像的两条直线,理由可以参考节2.1以前的文字。
那么首先是生成实验数据的代码GenerateData.m:
clc;clear all;close all;
%生成第一幅图的两条直线
x1 = 2:0.1:10;
y1 = 5.*x1-3;
x2 = 1:0.1:7;
y2 = -2.*x2+3;
figure(1);
plot(x1,y1,'b');hold on;
plot(x2,y2,'r')
title('第一幅图');
%生成第二幅图的两条直线(通过单应矩阵)
theta = 35/180*pi;
trans = [1; 1];
scale = 0.5;
%单应矩阵为相似变换
H_true = scale*[cos(theta) -1*sin(theta); sin(theta) cos(theta)];
H_true = [H_true trans];
H_true = [H_true;0 0 1]
xy3 = H_true*[x1;y1;ones(size(x1))];
xy4 = H_true*[x2;y2;ones(size(x2))];
x3 = xy3(1,:);
y3 = xy3(2,:);
x4 = xy4(1,:);
y4 = xy4(2,:);
figure(2);
plot(x3,y3,'b');hold on;
plot(x4,y4,'r');
title('第二幅图');
%给第一幅图生成内点(加点噪声)
[m,n] = size(x1);
xn1 = x1(1);
yn1 = y1(1);
for i = 4:3:n
xn1 = [xn1 x1(i)];
yn1 = [yn1 y1(i)+2*(rand()-0.5)];
end
[m,n] = size(x2);
xn2 = x2(1);
yn2 = y2(1);
for i = 4:3:n
xn2 = [xn2 x2(i)];
yn2 = [yn2 y2(i)+2*(rand()-0.5)];
end
figure(1);
plot(xn1,yn1,'b*');
plot(xn2,yn2,'r*');
%给第二幅图生成内点(加点噪声)
[m,n] = size(x3);
xn3 = x3(1);
yn3 = y3(1);
for i = 4:3:n
xn3 = [xn3 x3(i)];
yn3 = [yn3 y3(i)+2*(rand()-0.5)];
end
[m,n] = size(x4);
xn4 = x4(1);
yn4 = y4(1);
for i = 4:3:n
xn4 = [xn4 x4(i)];
yn4 = [yn4 y4(i)+2*(rand()-0.5)];
end
figure(2);
plot(xn3,yn3,'b*');
plot(xn4,yn4,'r*');
hold on
两幅图之间的单应矩阵是自己设定的,所以我们能够轻易地得到实验的真值,其次由于内点不可能每个都落在直线上,所以要自行给直线点添加噪声,从而得到内点,最后使用随机数生成野值,实验数据可以看图4。
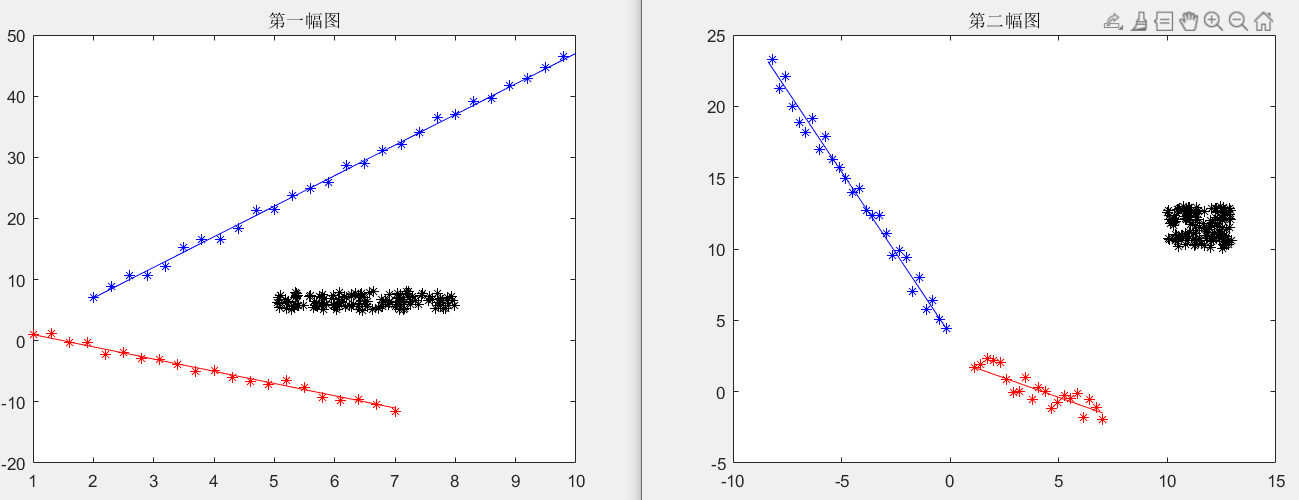
图 4: 实验数据
然后是需要自己构造出单应矩阵的求解器,这里使用的是自己写的没有归一化操作的DLT求解器,归一化对DLT求解的提升是具有本质性的,换句话说是不可或缺的,这点或许以后有机会可以细讲(挖个坑)。具体的求解器代码如下DLTSolver.m:
function H = DLTSolver(xy1, xy2)
%输入:两幅图像匹配特征点的坐标
%输出:单应矩阵H
A = [zeros(1,3) -1*xy1(:,1)' xy2(2,1)*xy1(:,1)';
xy1(:,1)' zeros(1,3) -xy2(1,1)*xy1(:,1)'];
[m,n] = size(xy1);
for i = 2:1:n
A = [A;
zeros(1,3) -1*xy1(:,i)' xy2(2,i)*xy1(:,i)';
xy1(:,i)' zeros(1,3) -xy2(1,i)*xy1(:,i)'];
end
[U,S,V] = svd(A);
H = [V(1:3,end)';V(4:6,end)';V(7:9,end)']/V(9,end); %H(3,3)为1时候的结果
end
DLT求解器的效果看图5。

图 4: DLT求解器效果
DLT求解器的效果稳如老狗,即使内点存在噪声干扰的情况下基本等于自己设定的真实值,但是在一定比例的野值(这里实验设定了90%)时就完全不能看了。这时候试一下我们的自适应RANSAC算法,自适应RANSAC的代码如下self_adaption_RANSAC.m:
%构造DLT求解器的数据,即两幅图片的内点坐标
xyn1 = [x1 x2;y1 y2;ones(size([y1 y2]))];
xyn2 = [x3 x4;y3 y4;ones(size([y3 y4]))];
%DLT求解无野值时的单应矩阵H
H_NoNoise = DLTSolver(xyn1, xyn2)
%加入野值
epsilon = 0.9;%野值比例
[m,n] = size(xyn1);
for i = 1:1:epsilon*n
xyn1 = [xyn1 [3*rand(2,1)+5;1]];
xyn2 = [xyn2 [3*rand(2,1)+10;1]];
end
figure(1)
plot(xyn1(1,n+1:end),xyn1(2,n+1:end),'k*');
figure(2)
plot(xyn2(1,n+1:end),xyn2(2,n+1:end),'k*');
hold off
%DLT求解有野值无RANSAC拟合的H
H_Noise = DLTSolver(xyn1, xyn2)
%获得数据总数n
[m,n] = size(xyn1);
%确定迭代次数N、距离阈值t和期望最大一致集T
N = 999999; t = 1; T = n;
%记录最大一致集
maxScore = 0;
H_RANSAC = 0;
i = 0;
%预估的野值比例(建议直接拉满就行)
epsilon_estim = 1;
while i < N
%构造随机样本(单应矩阵的计算最少需要四对匹配点)
sample = randperm(n,4);%样本的序号
S1 = xyn1(:,sample);
S2 = xyn2(:,sample);
H = DLTSolver(S1,S2);
%给支集打分(用单图像误差,可以自行改成对称转移或其他误差)
errors = (xyn2 - H*xyn1).^2;
errors = sum(errors);
score = sum((errors < t));
%达到期望最大一致集,退出(其实自适应RANSAC并不需要)
if(score > T)
break;
end
%保存得分最高的单应估计,并更新N
if(maxScore < score)
H_RANSAC = H;
maxScore = score;
epsilon_estim = (n-maxScore)/n;%更新野值估计比例
N = log(1-0.99)/log(1-(1-epsilon_estim)^4);
end
i = i+1;
end
H_RANSAC
结果在图6:

图 6: 自适应RANSAC结果
有了RANSAC以后,即使野值占比达到90\%,也并没有影响但单应估计的结果,所以RANSAC算得上是非常鲁棒的算法了。



评论(0)
您还未登录,请登录后发表或查看评论