

从本节开始,会以Mohamed W. Mehrez[1]所提供的实例为基础,用Python来实现模型预测控制(MPC)和滚动时域估计(MHE)。
运动学模型
既然是基于模型的优化问题,那么首先简单地对所研究对象的运动学模型进行介绍。本示例使用常见的差分小车模型,其坐标转换关系如下图所示。
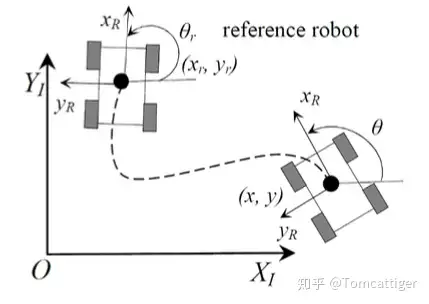
对于这样一个在平面运动的模型,我们只需要使用三个坐标系即可描述小车在平面中的状态,即 ,其中 和 为小车在大地坐标系下的二维坐标值,而 描述的是小车前进方向相对于大地坐标系下相对角度。通常情况下,针对差分驱动的小车,我们的控制输入 可以选定为 , 其中 和 分别为相对于车体坐标系的前向运动速度和转动速度。
通过简单的坐标转换关系我们不难得到如下运动学关系
,或者可以通过离散的方式表达为
, 其中 为时间间隔。有了这个模型后下一步就是定义/设计优化代价函数。
优化目标
一般的,优化的目标是使得小车之后若干时间内的状态尽量接近我们所设计或是预想的状态,这个包括但不限于,小车本身的状态(这里的 )和控制输入(这里的 )。最简单的诉求便是我们希望我们设计的控制器多快好省(以尽量小的控制代价)地使得小车接近我的目标结果。举个简答的例子,在平面上两点之间直线路径抵达速度最快,但是如果将这个问题放大的三维平面,问题的答案就不是那么简单直接了。为了更为普遍地解决问题,我们可以构造一个代价函数,让算法自行去寻找得到这个结果并且实现最低代价的途径是什么。
在本例子中,我们选取相应的惩罚矩阵,并通过求和的方式获得今后若干步之内的代价函数以解决优化控制问题(optimal control problem, OCP),例如:
其中 就是我们的代价函数,它可能长这样 ,其中矩阵 和 就是需要预先定义的惩罚矩阵。之后控制器需要以 最小化为目标代价寻找最佳的控制输入。
当然,有时候也可以添加对最终状态的惩罚,如下所示 。
有了控制目标后,我们还需要结合上一小节定义的物理/运动模型和相关约束(如取值范围等)构成OCP问题。为解决OCP问题,其中一个途径是将其转换成非线性规划问题(nonlinear programming problem, NLP),其有如下标准表达方法
其中s.t.表示受约束于,即表示后面所附内容为求解问题需要考虑的约束条件。不失一般的,通常有不等约束和等价约束两种分别记作 和 。
Single Shooting vs Multi-Shooting
解决上述的NLP问题在数学上有不同的途径,根据Mohamed提供的示例,主要关于两种方法,分别是single shooting和multi-shooting。具体的区别大家可以参看其在GitHub提供PPT资料,我在这里提供两张图并简单总结一下,multi-shooting除了在控制变量上进行离散外也对系统状态进行了离散,使得求解问题的难度降低(速度提高,这一点可以在后面的示例中进行对比)。
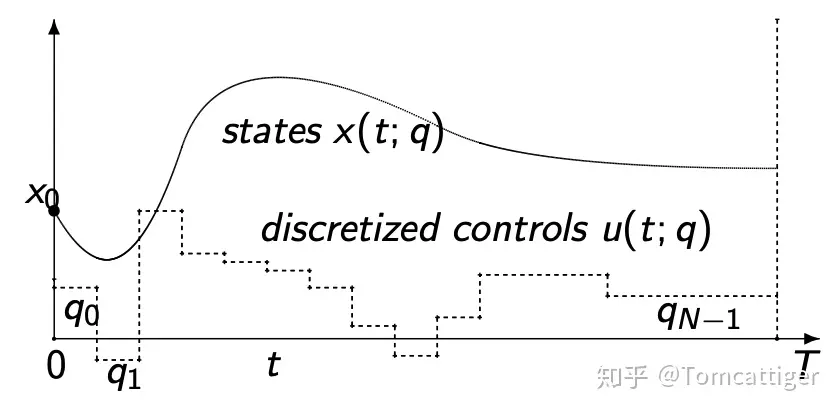
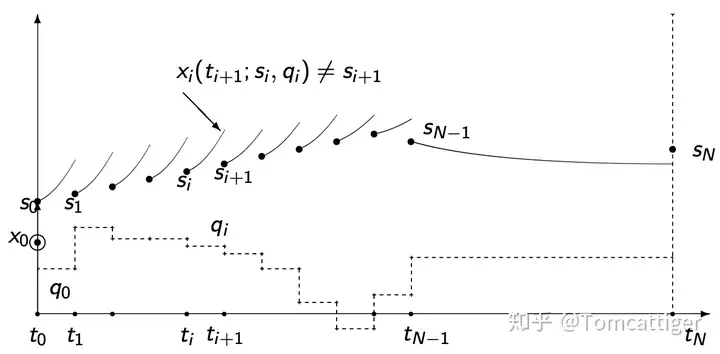
Let's code
讲完最核心模型和优化问题的构建和其数学上的解决方法,我们现在就可以利用CasADi来进行编程实践了。代码的基本思路会和Mohamed的MATLAB版本基本一致,后续会对不同实现方法实现的注意事项进行介绍。
simulation 1
在第一个场景中,在给定小车初始状态和最终状态后,需要通过算法自动地获得驱动小车运动的控制命令并不断驱动小车以达到最终状态。第一个例子的代码(sim_1_mpc_single_shooting.py)直接使用SX来构造MPC问题。这个版本的代码和原来的MATLAB代码最为接近,方便后面与MATLAB版本进行比较,大部分的讲解会在代码中以注释的方式呈现。
首先,我们需要导入之后会用到的工具和库。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
## CasADi 工具
import casadi as ca
## 其他常用库
import numpy as np
import time接下来我们就来到了主函数的部分,首先我们需要根据数学模型使用CasADi的符号表达方式构建,也就是把之前的数学模型变成实际的代码。
if __name__ == '__main__':
T = 0.2 # (模拟的)系统采样时间【秒】
N = 100 # 需要预测的步长【超参数】
rob_diam = 0.3 # 机器人自身直径【米,仅为展示所用】
v_max = 0.6 # 最大前向速度【物理约束】
omega_max = np.pi/4.0 # 最大转动角速度 【物理约束】
# 根据数学模型建模
## 系统状态
x = ca.SX.sym('x') # x轴状态
y = ca.SX.sym('y') # y轴状态
theta = ca.SX.sym('theta') # z轴转角
states = ca.vertcat(x, y) # 构建小车状态向量 \bm{x} = [x, y, theta].T
states = ca.vertcat(states, theta) # 实际上也可以通过
# states = ca.vertcat(*[x, y, theta])
# 或者 ca.vcat([x, y, theta)一步实现
n_states = states.size()[0] # 获得系统状态的尺寸,向量以(n_states, 1)的格式呈现 【这点很重要】
## 控制输入
v = ca.SX.sym('v') # 前向速度
omega = ca.SX.sym('omega') # 转动速度
controls = ca.vertcat(v, omega) # 控制向量
n_controls = controls.size()[0] #控制向量尺寸
# 运动学模型
rhs = ca.vertcat(v*np.cos(theta), v*np.sin(theta))
rhs = ca.vertcat(rhs, omega)
# 利用CasADi构建一个函数
f = ca.Function('f', [states, controls], [rhs], ['input_state', 'control_input'], ['rhs'])至此,我们在代码中构建了一个函数f。这个函数的输入为[states, controls],而输出就是通过[states, controls]表达的系统的运动学模型。换成Python格式的解释是
def f(states, controls):
return rhs因此,从理解上,上述代码的意义只是为了得到这个用符号表达的f函数,后续我们不需要使用之前定义的这些ca.SX.sym变量了。下一步才是基于这个函数构建MPC
if __name__ == 'main':
...
# 开始构建MPC
## 相关变量,格式(状态长度, 步长)
U = ca.SX.sym('U', n_controls, N) # N步内的控制输出
X = ca.SX.sym('X', n_states, N+1) # N+1步的系统状态,通常长度比控制多1
P = ca.SX.sym('P', n_states+n_states) # 构建问题的相关参数
# 在这里每次只需要给定当前/初始位置和目标终点位置
## Single Shooting 约束条件
X[:, 0] = P[:3] # 初始状态希望相等
### 剩余N状态约束条件
for i in range(N):
# 通过前述函数获得下个时刻系统状态变化。
# 这里需要注意引用的index为[:, i],因为X为(n_states, N+1)矩阵
f_value = f(X[:, i], U[:, i])
X[:, i+1] = X[:, i] + f_value*T
## 获得输入(控制输入,参数)和输出(系统状态)之间关系的函数ff
ff = ca.Function('ff', [U, P], [X], ['input_U', 'target_state'], ['horizon_states'])
## NLP问题
### 惩罚矩阵
Q = np.array([[1.0, 0.0, 0.0],[0.0, 5.0, 0.0],[0.0, 0.0, .1]])
R = np.array([[0.5, 0.0], [0.0, 0.05]])
### 优化目标
obj = 0 # 初始化优化目标值
for i in range(N):
# 在N步内对获得优化目标表达式
obj = obj + ca.mtimes([(X[:, i]-P[3:]).T, Q, X[:, i]-P[3:]]) + ca.mtimes([U[:, i].T, R, U[:, i]])
### 约束条件定义
g = [] # 用list来存储优化目标的向量
for i in range(N+1):
# 这里的约束条件只有小车的坐标(x,y)必须在-2至2之间
# 由于xy没有特异性,所以在这个例子中顺序不重要(但是在更多实例中,这个很重要)
g.append(X[0, i])
g.append(X[1, i])
### 定义NLP问题,'f'为目标函数,'x'为需寻找的优化结果(优化目标变量),'p'为系统参数,'g'为约束条件
### 需要注意的是,用SX表达必须将所有表示成标量或者是一维矢量的形式
nlp_prob = {'f': obj, 'x': ca.reshape(U, -1, 1), 'p':P, 'g':ca.vertcat(*g)}
### ipot设置
opts_setting = {'ipopt.max_iter':100, 'ipopt.print_level':0, 'print_time':0, 'ipopt.acceptable_tol':1e-8, 'ipopt.acceptable_obj_change_tol':1e-6}
## 最终目标,获得求解器
solver = ca.nlpsol('solver', 'ipopt', nlp_prob, opts_setting)上述代码最后我们获得求解这个小车运动问题的求解器solver。接下来我们可以利用这个求解器来解决问题。
if __name__ == 'main':
...
...
# 开始仿真
## 定义约束条件,实际上CasADi需要在每次求解前更改约束条件。不过我们这里这些条件都是一成不变的
## 因此我们定义在while循环外,以提高效率
### 状态约束
lbg = -2.0 # x,y不得小于-2
ubg = 2.0 # x,y不得大于2
### 控制约束
lbx = [] # 最低约束条件
ubx = [] # 最高约束条件
for _ in range(N):
#### 记住这个顺序,不可搞混!
#### U是以(n_controls, N)存储的,但是在定义问题的时候被改变成(n_controlsxN,1)的向量
#### 实际上,第一组控制v0和omega0的index为U_0为U_1,第二组为U_2和U_3
#### 因此,在这里约束必须在一个循环里连续定义。
lbx.append(-v_max)
ubx.append(v_max)
lbx.append(-omega_max)
ubx.append(omega_max)
## 仿真条件和相关变量
t0 = 0.0 # 仿真时间
x0 = np.array([0.0, 0.0, 0.0]).reshape(-1, 1) # 小车初始状态
xs = np.array([1.5, 1.5, 0.0]).reshape(-1, 1) # 小车末了状态
u0 = np.array([0.0, 0.0]*N).reshape(-1, 2) # 系统初始控制状态,为了统一本例中所有numpy有关
# 变量都会定义成(N,状态)的形式方便索引和print
x_c = [] # 存储系统的状态
u_c = [] # 存储控制全部计算后的控制指令
t_c = [] # 保存时间
xx = [] # 存储每一步机器人位置
sim_time = 20.0 # 仿真时长
index_t = [] # 存储时间戳,以便计算每一步求解的时间
## 开始仿真
mpciter = 0 # 迭代计数器
start_time = time.time() # 获取开始仿真时间
### 终止条件为小车和目标的欧式距离小于0.01或者仿真超时
while(np.linalg.norm(x0-xs)>1e-2 and mpciter-sim_time/T<0.0 ):
### 初始化优化参数
c_p = np.concatenate((x0, xs))
### 初始化优化目标变量
init_control = ca.reshape(u0, -1, 1)
### 计算结果并且
t_ = time.time()
res = solver(x0=init_control, p=c_p, lbg=lbg, lbx=lbx, ubg=ubg, ubx=ubx)
index_t.append(time.time()- t_)
### 获得最优控制结果u
u_sol = ca.reshape(res['x'], n_controls, N) # 记住将其恢复U的形状定义
###
ff_value = ff(u_sol, c_p) # 利用之前定义ff函数获得根据优化后的结果
# 小车之后N+1步后的状态(n_states, N+1)
### 存储结果
x_c.append(ff_value)
u_c.append(u_sol[:, 0])
t_c.append(t0)
### 根据数学模型和MPC计算的结果移动小车并且准备好下一个循环的初始化目标
t0, x0, u0 = shift_movement(T, t0, x0, u_sol, f)
### 存储小车的位置
x0 = ca.reshape(x0, -1, 1)
xx.append(x0.full())
### 计数器+1
mpciter = mpciter + 1这里,在主函数之外,我们另外定义了一个shift_movement函数(纯数学仿真)来移动小车,如果有兴趣的同学可以结合Gazebo或者其他带有物理引擎的软件得到更真实的效果。具体函数定义如下
def shift_movement(T, t0, x0, u, f):
# 小车运动到下一个位置
f_value = f(x0, u[:, 0])
st = x0 + T*f_value
# 时间增加
t = t0 + T
# 准备下一个估计的最优控制,因为u[:, 0]已经采纳,我们就简单地把后面的结果提前
u_end = ca.horzcat(u[:, 1:], u[:, -1])
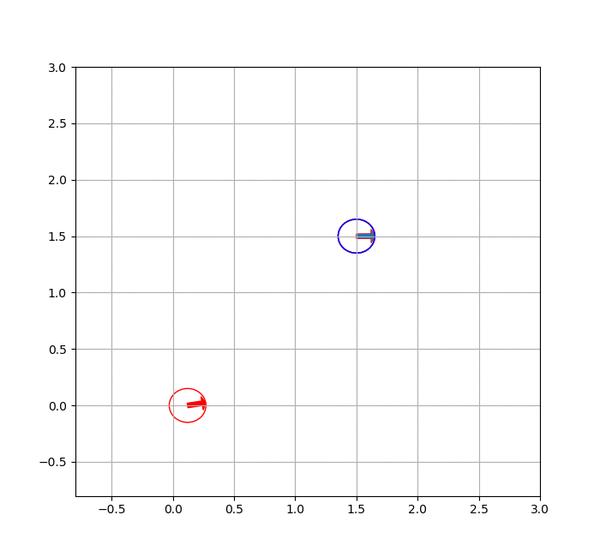
return t, st, u_end.T最终,我们就可以获得如下仿真结果(这个动图不如MATLAB版本的好看,后续有空会更新)。小车从初始位置开始沿一条S曲线抵达了最后的目标位置(蓝色)。
总结
在我自己的电脑上,完成一次计算的时间大约是0.1992秒,一次while循环为0.1997秒。说实话,速度是比较慢的,这跟超参数N的选择有关(计算一百步后的结果)。实际应用需要结合实际情况合理设置。下期文章会对Multi-Shooting实现并进行比较。
预留链接
Python代码GitHub
CasADi学习(1)
CasADi学习(3)



评论(0)
您还未登录,请登录后发表或查看评论