

transformers目前大火,但是对于长序列来说,计算很慢,而且很耗费显存。对于transformer中的self attention计算来说,在时间复杂度上,对于每个位置,模型需要计算它与所有其他位置的相关性,这样的计算次数会随着序列长度的增加而呈二次增长。在空间复杂度上,self attention需要存储一个矩阵来保存所有位置的相关性分数,这个矩阵的大小也会随着序列长度的增加而呈二次增长。因此,对于非常长的序列,这种二次复杂度会导致计算和内存消耗急剧增加,使得模型在处理这样的输入时会变得相对缓慢且需要大量内存。这也是为什么对于超长序列,可能需要采取一些策略,如切分成短序列进行处理,或者使用其他模型架构来替代传统的Transformer模型。
在pytorch、huggingface transformers library、微软的DeepSpeed、nvidia的Megatron-LM、Mosaic ML的Composer library、GPT-Neox、paddlepaddle中,都已经集成了flash attention。在MLPerf 2.1的open division中,在train BERT的任务上,flash attention也实现了2.7x的速度提升。
flash attention 1从attention计算的GPU memory的read和write方面入手来提高attention计算的效率。其主要思想是通过切块(tiling)技术,来减少GPU HBM和GPU SRAM之间的数据读写操作。通过切块,flash attention1实现了在BERT-large(seq. length 512)上端到端15%的提速,在GPT-2(seq. length 1k)上3x的提速。具体数据可看flash attention 1的paper。
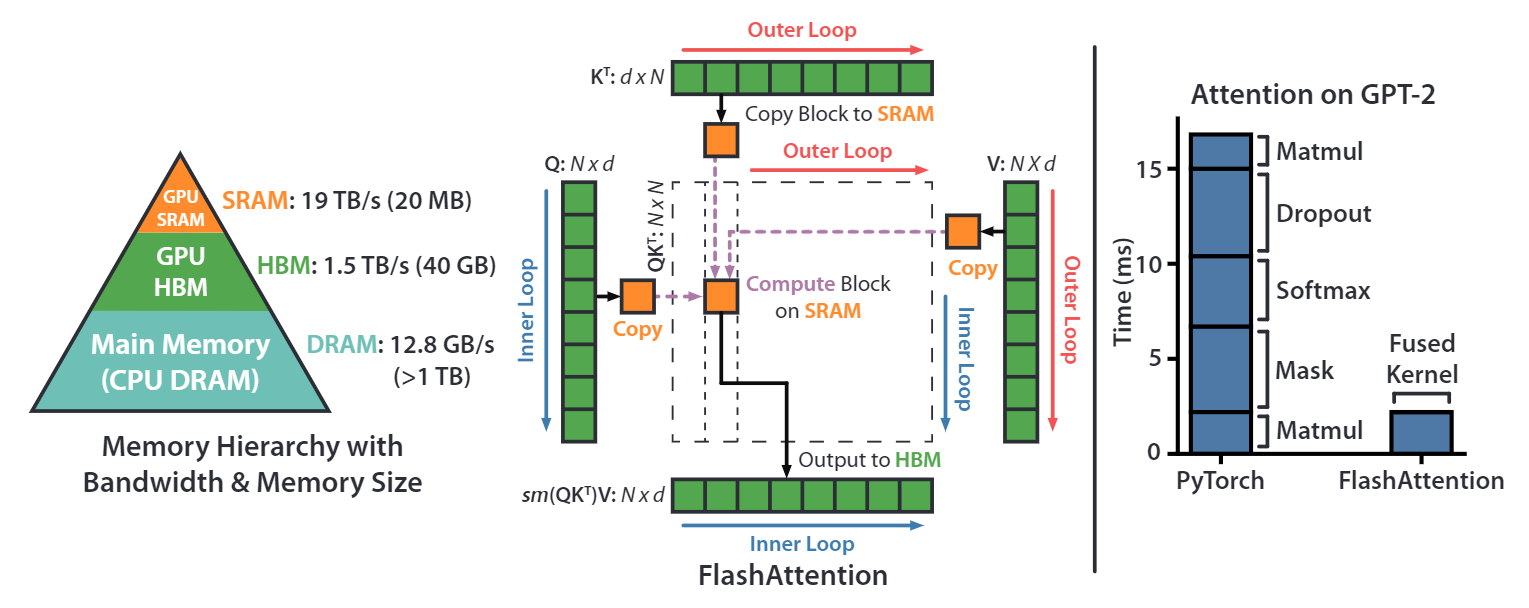
首先我们看一下NVIDIA GPU的显存架构,上图左图是以NVIDIA A100 40G显卡为例,我们常说的40G显存是其HBM memory(high bandwidth memory),其带宽是1.5~2.0TB/s,A100上还有一块192KB每108 SM (streaming multiprocessors) 的on-chip SRAM memory,其带宽是19TB/s。因此,如果能把涉及到显存的读写操作放在SRAM上,那将会极大的提升速度。
上图中间部分的图描述的就是flash attention 1算法的原理。对于常规的attention计算来说,首先会把Q、K和V完整的读进HBM中,然后执行计算。flash attention 1通过将Q、K和V切块成很多小块,然后将这些小块的Q、K和V放进SRAM中执行计算,最后再写回HBM中。
上图最右侧图片展示的是通过一些算子融合技术以及flash attention 1的IO优化技术,再GPT-2的计算上,flash attention IO优化+算子融合,相比pytorch的实现,有大约7.6x的性能提升。

上图的算法流程是标准的attention计算的实现。首先从HBM中加载Q,K矩阵,然后执行S=QK^T的计算,将结果S写回HBM;然后将S再从HBM中读取出来,执行P=softmax(S)的计算,再将P写回HBM;然后将P和V从HBM中读取出来,执行O=PV的计算,最后把结果写回HBM中。
这个过程中,有多次与HBM的IO操作,速度相对较慢。

上图算法流程是flash attention1的forward实现。我们逐步的看一下计算过程。
1.首先根据SRAM的大小,计算出合适的分块block大小;
2.将O,l,m在HBM中初始化为对应shape的全0的矩阵或向量,l,m的具体作用后面算法流程会说明;
3.将Q,K,V按照分块block的大小切分成许多个blocks;
4.将O,l,m也切分成对应数量的blocks;
5.执行outer loop,在outer loop中,做的IO操作是将分块的K_j,V_j从HBM中加载到SRAM中;
6.执行inner loop,将Q_i,O_i,l_i,m_i从HBM中load到SRAM中,然后分块计算上面流程的中间值,在每个inner loop里面,都将O_i,l_i,m_i写回到HBM中,因此与HBM的IO操作还是相对较多的。
由于我们将Q,K,V都进行了分块计算,而softmax却是针对整个vector执行计算的,因此在上图flash attention的计算流程的第10、11、12步中,其使用了safe online softmax技术。
y=softmax(x)的定义为
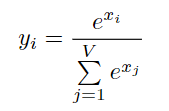

上图是naive softmax的实现过程,首先需要迭代计算分母的和,然后再迭代计算vector中每一个值对应的softmax值。这个过程需要两次从内存读取和一次写回内存操作。
但是naive softmax在实际的硬件上计算是有问题的,在naive softmax的实现过程的第3步,由于有指数操作,会有数值溢出的情况,因此在实际使用时,softmax都是使用safe softmax算法
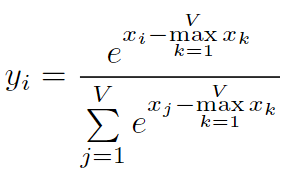

上图是safe softmax的计算过程,其主要修改是在指数部分,减去了要计算vector的最大值,保证了指数部分的最大值是0,避免了数值溢出。在几乎所有的深度学习框架中,都是使用safe softmax来执行softmax算法的。但是safe softmax相比naive softmax,多了一次数据的读取过程,总共是从内存中有三次读取,一次写入操作。
但是不管是naive softmax还是safe softmax,都需要传入一整个vector进行计算,但是flash attention 1算法执行了分块(tiling)策略,导致不能一次得到整个vector,因此需要使用online safe softmax算法。

上面的算法流程是online safe softmax的计算过程。在safe softmax中,vector的最大值$m$的计算是在一个单独的for循环中,在online safe softmax中,m的计算是迭代进行的,因此得到的m不是一个vector中最大的值,而是迭代过程中的局部极大值,相应的对softmax的分母$d$的计算也要加一个补偿项e^{m_{j-1}-m_j}。
这样得出的结果与直接使用safe softmax是一致的,具体的证明过程可以参考论文Online normalizer calculation for softmax。在flash attention 1的算法中,其也使用了online safe softmax,并对其算法进行了相应的扩展。
我们用一个简单的例子看一下safe softmax与pytorch标准的softmax的计算结果。online safe softmax在后面的flash attention的实现中会有体现。
import torch
torch.manual_seed(456)
N, d = 16, 8
Q_mat = torch.rand((N, d))
K_mat = torch.rand((N, d))
V_mat = torch.rand((N, d))
# 执行标准的pytorch softmax和attention计算
expected_softmax = torch.softmax(Q_mat @ K_mat.T, dim=1)
expected_attention = expected_softmax @ V_mat
## 执行safe softmax和attention计算
# 1st read
S_mat = Q_mat @ K_mat.T
row_max = torch.max(S_mat, dim=1).values[:, None]
# 2nd read
input_safe = S_mat - row_max
softmax_numerator = torch.exp(input_safe)
# 3rd read
softmax_denominator = torch.sum(softmax_numerator, dim=1)[:, None]
# 4th read
safe_softmax = softmax_numerator / softmax_denominator
# final matmul (another read / write)
matmul_result = safe_softmax @ V_mat
assert torch.allclose(safe_softmax, expected_softmax)
assert torch.allclose(matmul_result, expected_attention)
经过代码最终的assert,safe_softmax与pytorch标准的softmax的计算结果是一致的。
下面我们用python代码实现flash attention 1的forward算法流程:
import torch
torch.manual_seed(456)
N, d = 16, 8
Q_mat = torch.rand((N, d))
K_mat = torch.rand((N, d))
V_mat = torch.rand((N, d))
# 执行标准的pytorch softmax和attention计算
expected_softmax = torch.softmax(Q_mat @ K_mat.T, dim=1)
expected_attention = expected_softmax @ V_mat
# 分块(tiling)尺寸,以SRAM的大小计算得到
Br = 4
Bc = d
# flash attention算法流程的第2步,首先在HBM中创建用于存储输出结果的O,全部初始化为0
O = torch.zeros((N, d))
# flash attention算法流程的第2步,用来存储softmax的分母值,在HBM中创建
l = torch.zeros((N, 1))
# flash attention算法流程的第2步,用来存储每个block的最大值,在HBM中创建
m = torch.full((N, 1), -torch.inf)
# 算法流程的第5步,执行外循环
for block_start_Bc in range(0, N, Bc):
block_end_Bc = block_start_Bc + Bc
# line 6, load a block from matmul input tensor
# 算法流程第6步,从HBM中load Kj, Vj的一个block到SRAM
Kj = K_mat[block_start_Bc:block_end_Bc, :] # shape Bc x d
Vj = V_mat[block_start_Bc:block_end_Bc, :] # shape Bc x d
# 算法流程第7步,执行内循环
for block_start_Br in range(0, N, Br):
block_end_Br = block_start_Br + Br
# 算法流程第8行,从HBM中分别load以下几项到SRAM中
mi = m[block_start_Br:block_end_Br, :] # shape Br x 1
li = l[block_start_Br:block_end_Br, :] # shape Br x 1
Oi = O[block_start_Br:block_end_Br, :] # shape Br x d
Qi = Q_mat[block_start_Br:block_end_Br, :] # shape Br x d
# 算法流程第9行
Sij = Qi @ Kj.T # shape Br x Bc
# 算法流程第10行,计算当前block每行的最大值
mij_hat = torch.max(Sij, dim=1).values[:, None]
# 算法流程第10行,计算softmax的分母
pij_hat = torch.exp(Sij - mij_hat)
lij_hat = torch.sum(pij_hat, dim=1)[:, None]
# 算法流程第11行,找到当前block的每行最大值以及之前的最大值
mi_new = torch.max(torch.column_stack([mi, mij_hat]), dim=1).values[:, None]
# 算法流程第11行,计算softmax的分母,但是带了online计算的校正,此公式与前面说的online safe softmax不一致,但是是同样的数学表达式,只是从针对标量的逐个计算扩展到了针对逐个向量的计算
li_new = torch.exp(mi - mi_new) * li + torch.exp(mij_hat - mi_new) * lij_hat
# 算法流程第12行,计算每个block的输出值
Oi = (li * torch.exp(mi - mi_new) * Oi / li_new) + (torch.exp(mij_hat - mi_new) * pij_hat / li_new) @ Vj
# 算法流程第13行
m[block_start_Br:block_end_Br, :] = mi_new # row max
l[block_start_Br:block_end_Br, :] = li_new # softmax denominator
# 算法流程第12行,将Oi再写回到HBM
O[block_start_Br:block_end_Br, :] = Oi
assert torch.allclose(O, expected_attention)
运行代码,经过最后的assert操作,没有raise错误,说明通过flash attention计算的O值与pytorch标准的O值是一致的。
我们在这里使用python实现了flash attention1的算法原理。flash attention1的工业实现是使用nvidia的cutlass库完成的,cutlass是相对较底层的工具库,目前flash attention1仅支持Ampere, Ada,Turing或者Hopper架构的GPU (例如A100, RTX 3090, RTX 4090, H100, T4, RTX 2080).


评论(0)
您还未登录,请登录后发表或查看评论