

写在前面
前篇回顾:
在这片博客里我将记录模型评价的ROC曲线以及AUC面积的概念以及作用,并且同样以二分类任务为例介绍一个新的犯错成本不均衡的模型评价工具,那就是代价曲线
ROC于AUC
在这里我们要引入2个新的概念,那就是真正例率(True Positive Rate,简称TPR)和假正例率(False Positive Rate,简称FPR),定义如下图所示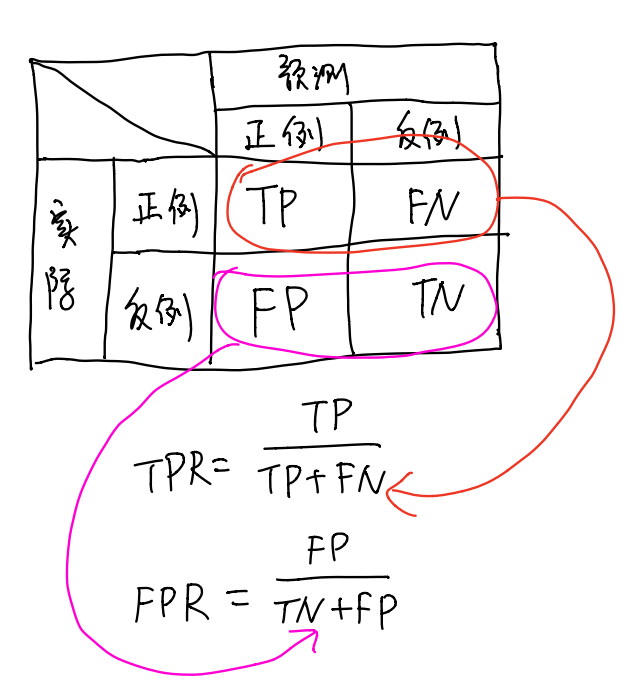
连续点
现在我们介绍了很多的比例概念,让我们来整理一下吧
TPR:模型预测的正确正例占实际正例的比例
FPR:模型预测的错误正例占实际反例的比例
P:模型预测的正例的正确率
R:模型预测的正例的完整率
然后我们就可以介绍ROC曲线啦,我们以FPR为横坐标,TPR为纵坐标,修改分类阈值,也就是正例和反例的分割点,使得模型输出的TPR和FPR不同,从而得到如下的坐标图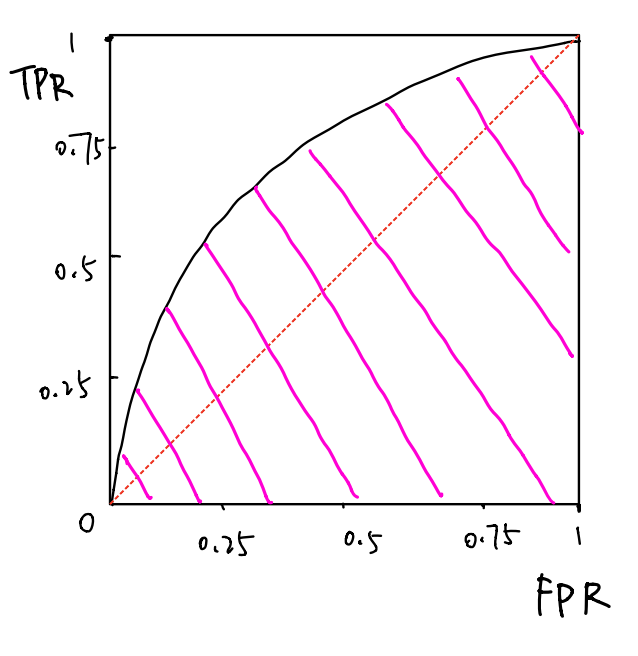
我们来看一个特殊点,那就是坐标(1,1)和(0,0),这2个具体的含义是什么呢?我们来举个例子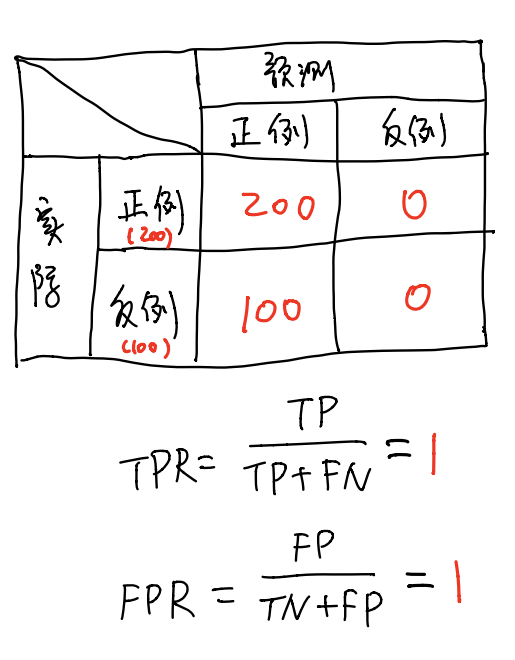
这种情况就是很严重的过拟合了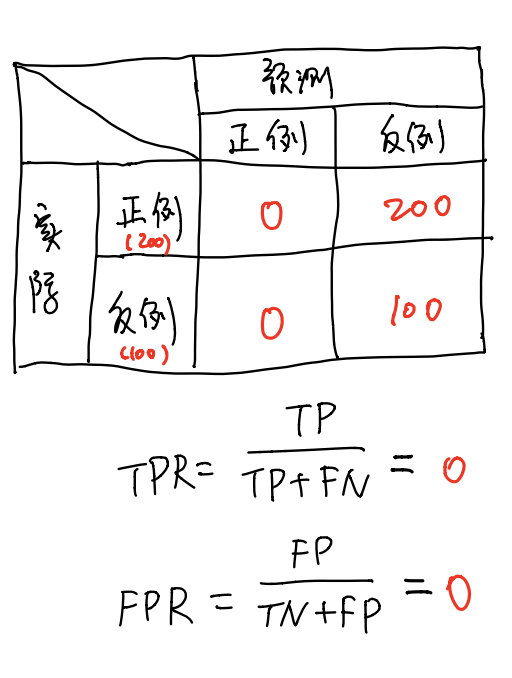
这种情况就是很严重的欠拟合了,可以认为这个学习器啥也不会
离散点
在实际情况下,很难做到ROC曲线是连续的,因为拿来验证的数据集是有限的,所以实际情况下ROC曲线是非连续,而是离散的,如下图所示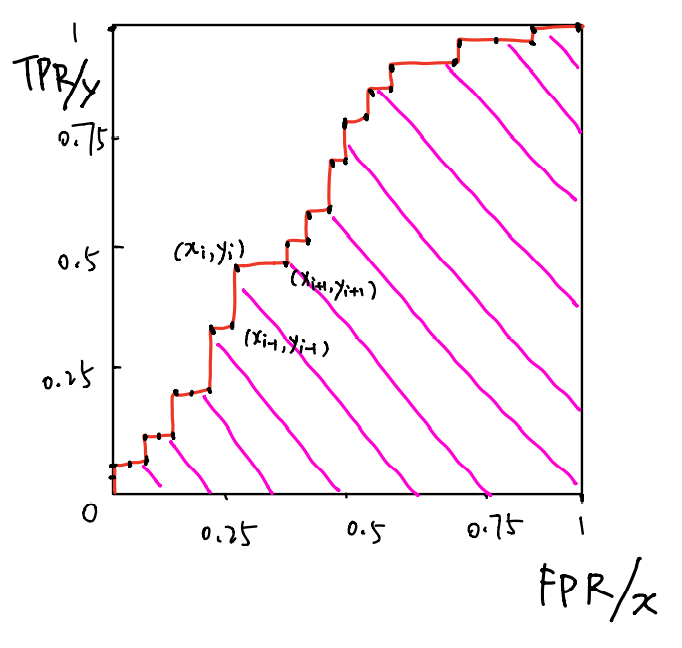
其实ROC从(0,0)到(1,1)的过程可以看成随着训练的进行,模型输出从欠拟合到过拟合的过程
AUC
AUC全称Area Under ROC Curve,也就是粉色线所覆盖的区域面积,这个面积大小是用来评价模型的性能的,那该怎么计算离散点组成的ROC曲线的粉色线所覆盖的区域面积呢?
如下图所示
AUC数值越大也代表着模型越优
不均等成本及代价曲线
在现实生活中,犯错的成本是不一样的,比如马路上摔一跤和摔下楼梯这2个错误(失误)的成本是不一样的。同样的,在模型中的犯错成本也是不一样的,因此在这里引入新的概念,那就是二分类代价矩阵,如下图所示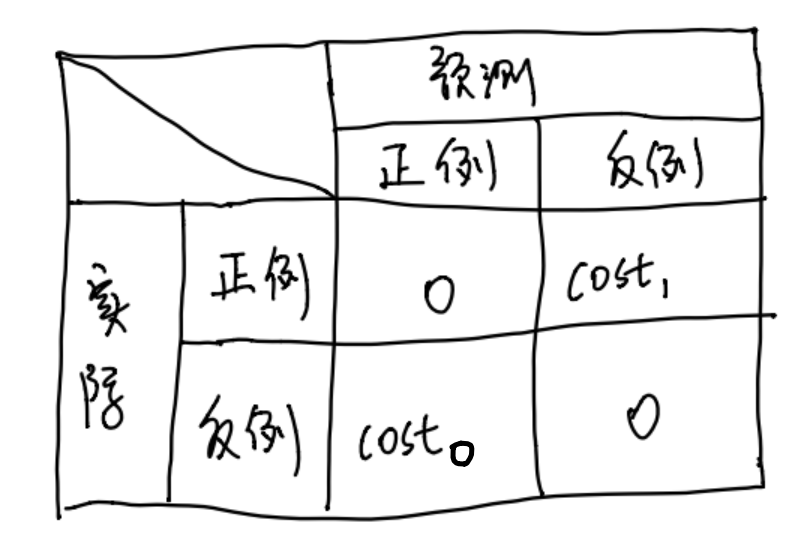
代价敏感
我们设置cost来衡量整个模型的性能,初步实现了非均衡犯错成本的简单数学衡量,cost1是将正例识别成反例的惩罚因子,cost0是将反例识别成正例的惩罚因子,假设验证集里面有m个样本
cost可以理解成模型将正例判成反例时会惩罚cost1分数,模型将反例判成正例时会惩罚cost0分数,当把验证集里的m个样本都判断完毕之后会得到罚分结果的总和,并以此来判断模型的性能,因此这个罚分越小的话模型自然是越优的啦~
因为现在犯错的代价不再是均衡的五五开了,因此ROC曲线不能直接反映出模型的性能,但是还有代价曲线可以帮助我们衡量模型的性能
代价曲线
我们定义正例概率是p,并定义正例概率代价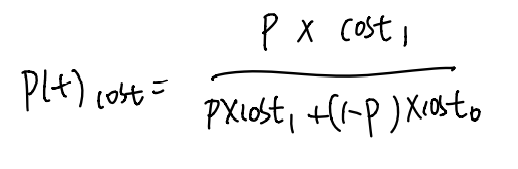
其中p可以这样理解
我们再定义归一化代价,得到cost_norm
最后以cost_norm为纵坐标,正例概率代价为横坐标,将ROC曲线上的点绘制呈直线,这些直线与坐标轴会围出一个面积,取所有面积的交集就是我们要的期望总体代价
那么怎么将ROC曲线坐标上的点转化成直线呢?假设ROC上的点坐标为(FPR,TPR),可计算出相应的FNR,并绘制一条从(0,FPR)到(1,FNR)的直线就是我们要的结果啦~
其实这个直线也代表了模型随着训练从欠拟合到过拟合的一个过程,因此取面积交集,且面积交集越大,模型越优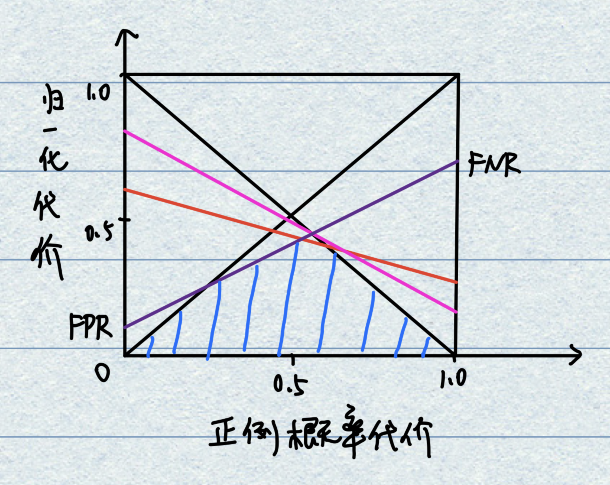



评论(0)
您还未登录,请登录后发表或查看评论