

核心思想
本文提出一种基于坐标的6D位姿估计网络,现有的位姿估计算法通常可以分为直接方法和间接方法,直接方法就是通过回归的方式直接输出6D位姿信息,间接方法就是分别预测目标的2D图像坐标和3D空间坐标,然后通过PnP方法来计算位姿。作者发现对于位姿估计中的旋转矩阵,使用间接法计算更加准确,而对于平移矩阵更适合用直接法来计算,因此作者提出了“分离”位姿网络,分别使用两种方式来估计旋转和平移矩阵。
实现过程
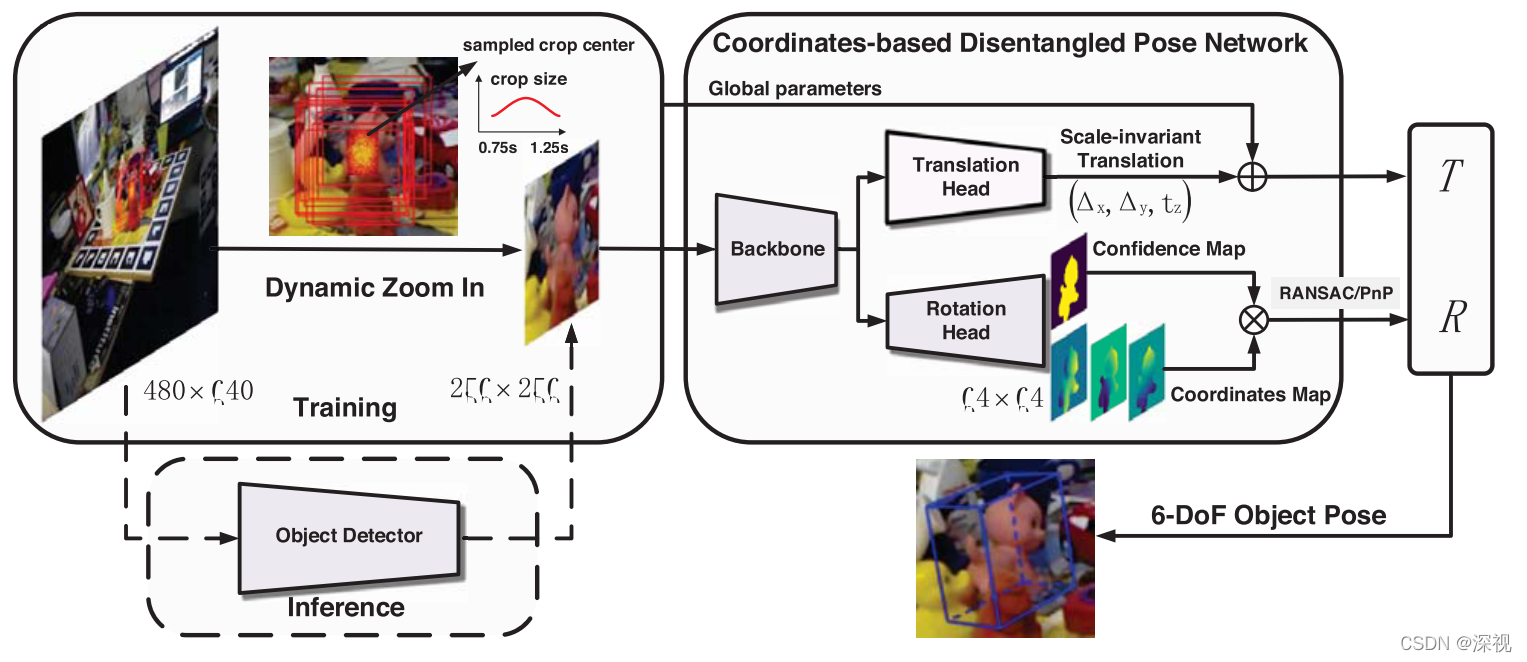
首先,相对于基于关键点进行位姿估计的方法,基于稠密坐标的位姿估计对于遮挡和聚集问题更加的具有鲁棒性。为了构建2D图像坐标和3D空间坐标之间的对应关系,要从图像中精确提取出目标区域,有些方法是采用语义分割网络来实现的,但语义分割网络无法区分同类物体的不同实例;而实例分割网络速度较慢难以满足实时性要求。本文提出一种两阶段方法:第一阶段使用一个快速的目标检测方法得到粗糙的检测结果,第二阶段使用一个固定尺寸的分割方法来提取目标的像素。
由于目标物体的尺寸随着与相机之间的距离变化是在改变的,这给坐标预测带来很大的困难,而且当物体较小时很难提取足够的信息。为了解决这个问题,本文采用一种动态放大(Dynamic Zoom In,DZI)的方法将目标物体放大至一个固定的尺寸。根据目标检测网络得到目标物体的中心坐标
C
x
,
y
C_{x,y}
Cx,y和尺寸
S
=
m
a
x
(
h
,
w
)
S=max(h,w)
S=max(h,w),从一个截尾正态分布中采样得到新的
C
~
x
,
y
\tilde{C}_{x,y}
C~x,y和
S
~
\tilde{S}
S~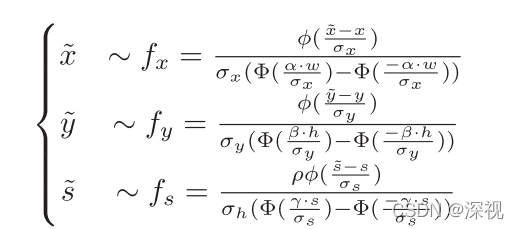
其中
α
,
β
,
γ
,
ρ
\alpha,\beta,\gamma,\rho
α,β,γ,ρ是约束采样范围的参数。利用
C
~
x
,
y
\tilde{C}_{x,y}
C~x,y和
S
~
\tilde{S}
S~提取目标物体,然后在保持长宽比不变的条件下将其放缩至固定的尺寸。
正如上文所说,本文需要预测目标物体稠密的3D坐标,此外还需要预测每个像素属于目标物体的置信度,作者使用一个网络同时完成这两个任务。首先固定尺寸的目标物体图像经过一个主干网络提取特征,然后利用一个由多层卷积层和反卷积层构成的“旋转头”来预测3D坐标和置信度,具体而言就是输出一个4通道的“坐标-置信度”图(
H
×
W
×
4
H \times W \times 4
H×W×4),其中三个通道表示坐标图
M
c
o
o
r
M_{coor}
Mcoor,分别表示物体坐标系中得
X
,
Y
,
Z
X,Y,Z
X,Y,Z坐标,另一个通道表示置信度图
M
c
o
n
f
M_{conf}
Mconf表示该像素属于目标物体得概率。因为对于背景部分的3D坐标的真实值是未知的,许多方法是为这些点赋予一个特殊值,这种方法适用于基于分类的方法。但本文的方法是直接的预测稠密的3D坐标,这推动网络预测目标物体的边界有清晰的边缘,这非常困难而且会导致坐标预测误差较大。为了解决这个问题,本文提出一个掩码的坐标-置信度损失(MCC Loss):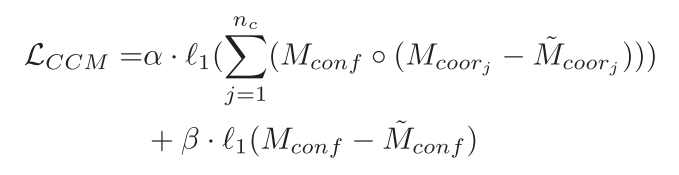
其中
∘
\circ
∘表示Hadamard乘积。对于坐标预测,只计算目标所在的前景区域损失;对于置信度预测,对全部区域计算损失。
得到置信度图后,通过设定阈值,就可以将属于目标物体的像素筛选出来。但是因为之前做了动态放大的操作,导致RGB图像中的点和置信度图
M
c
o
n
f
M_{conf}
Mconf与坐标图
M
c
o
o
r
M_{coor}
Mcoor并不是准确对应的,为了计算2D图像-3D坐标的匹配关系必须将其坐标图中的像素坐标映射回RGB图像中: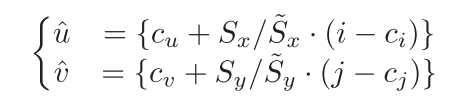
其中,
(
u
^
,
v
^
)
(\hat{u},\hat{v})
(u^,v^)表示RGB图像中的坐标,
(
i
,
j
)
(i,j)
(i,j)表示坐标图中的坐标,
(
c
u
,
c
v
)
(c_u,c_v)
(cu,cv)和
(
S
~
x
,
S
~
y
)
(\tilde{S}_x,\tilde{S}_y)
(S~x,S~y)分别表示RGB图像中物体的中心坐标和尺寸,
(
c
i
,
c
j
)
(c_i,c_j)
(ci,cj)和
(
S
x
,
S
y
)
(S_x,S_y)
(Sx,Sy)分别表示坐标图中物体的中心坐标和尺寸,
{
}
{}
{}表示取整。得到2D-3D坐标对应关系后,可以利用PnP算法计算得到旋转矩阵。
虽然平移矩阵也可以利用2D-3D坐标对应关系通过PnP算法求解,但是作者分析发现受到放缩因子误差
δ
s
c
a
l
e
\delta_{scale}
δscale的影响,平移矩阵中的深度值
T
z
T_z
Tz误差较大,而作者还发现利用语义分割网络直接预测平移矩阵其准确率较高,因此作者提出使用直接法来预测平移矩阵的参数。即对于旋转矩阵本文采用PnP方法间接计算,平移矩阵使用网络直接预测,并将其整合到一个网络中,称之为基于坐标的分离位姿网络(Coordinates- based Disentangled Pose Network ,CDPN)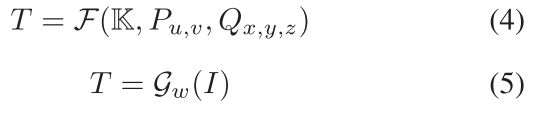
上式(4)中的
T
T
T应为
R
R
R表示旋转矩阵,
K
\mathbb{K}
K表示相机内参,
P
u
,
v
P_{u,v}
Pu,v表示2D图像坐标,
Q
x
,
y
,
z
Q_{x,y,z}
Qx,y,z表示3D空间坐标,
G
w
\mathcal{G}_w
Gw表示平移矩阵预测网络,
I
I
I表示输入图像。
为了实现平移矩阵的准确高效预测,本文提出了尺度不变的平移矩阵估计网络(Scale-Invariant Translation Estimation,SITE),首先提取全局图像信息
T
G
T_G
TG包括采样局部图块的中心位置
C
x
,
y
C_{x,y}
Cx,y和尺寸
(
h
,
w
)
(h,w)
(h,w),然后利用“平移头”预测一个尺度不变的平移向量
T
S
=
(
Δ
x
,
Δ
y
,
t
z
)
T_S=(\Delta_x,\Delta_y,t_z)
TS=(Δx,Δy,tz),其中
Δ
x
\Delta_x
Δx和
Δ
y
\Delta_y
Δy表示目标外接框中心与物体中心之间的相对坐标偏差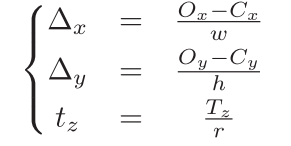
其中
r
r
r表示DZI中的放缩比例。则还原为旋转矩阵为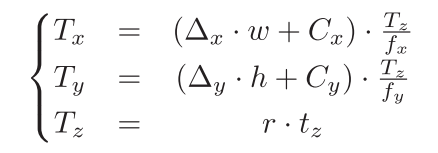
SITE的损失函数为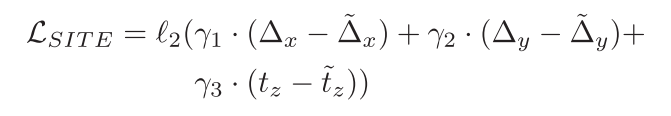
本文的6D姿态估计和3D坐标估计结果如下
创新点
- 提出一种基于坐标的分离位姿网络,旋转矩阵通过间接法计算,平移矩阵通过直接法预测
- 引入了动态放大操作将目标物体放缩为固定尺寸的图块
- 提出了MCC损失和旋转不变性平移预测网络SITE
算法评价
本文最主要的创新就是将旋转矩阵和平移矩阵分开计算,充分发挥了间接法和直接法的优势。利用DZI降低了对于目标检测精度的要求,因此可以采用参数更少的速度更快的预测方法,并且可以根据需要更换检测算法。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论