

核心思想
本文提出一种基于双目图像进行透明物体位姿估计的方法。作者首先回顾了现有的位姿估计方法,通常采用单目相机获取目标2D图像,并与物体的3D模型或者RGB-D获取的点云图像进行匹配,进而实现位姿估计。而RGB-D传感器对于透明的,光滑的物体,其距离感知效果并不好。为了解决这个问题,作者采用了双目立体视觉来获得透明物体的深度信息,并通过提取物体上的关键点,利用反透视变换来获取关键点的3D坐标。因为现有的姿态估计数据集,尚没有提供双目数据的,因此作者提出一种方法,通过简单的标记就可以获取目标物体的关键点三维坐标,3D模型等信息,并制作了一个双目的透明物体位姿估计数据集(Transparent Object Dataset, TOD),用于网络的训练和测试。
实现过程
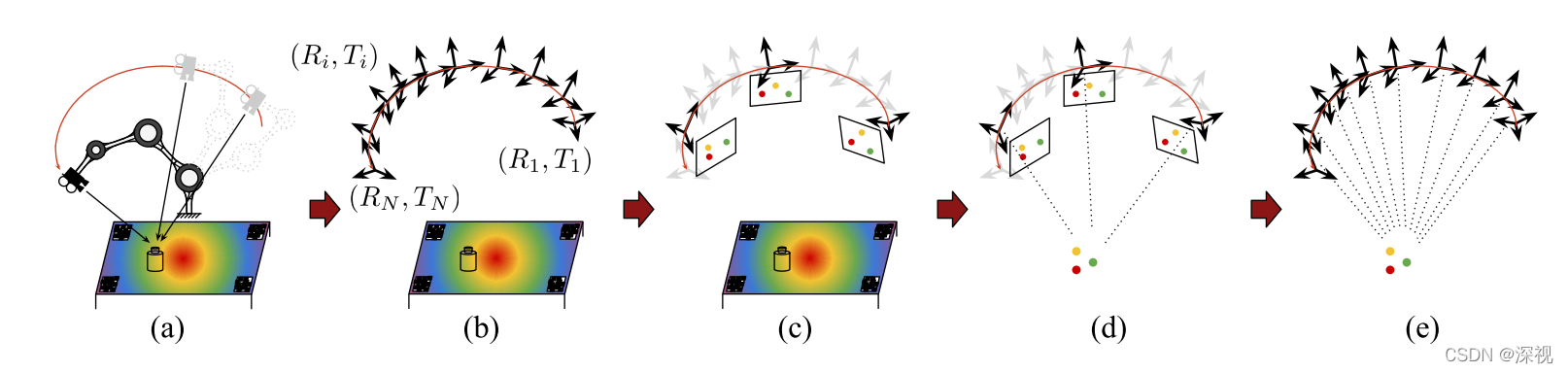
首先介绍如何获取双目图像数据集,作者在机械臂的末端安装一个标定好的双目相机,在多个连续视角下拍摄目标物体的图像(如图a)。为了估计相机在世界坐标系下的相对位姿,作者将目标物体放置在一个平面上,在平面的特定位置粘贴了多个二维码标签,相机通过识别识别标签,并结合标签对应的位置坐标利用PnP算法就可以求解出自身的位姿(如图b)。然后利用最远点采样算法(farthest point sampling,FPS)从连续的图像序列中选出彼此之间距离最大的几个关键帧,并人工在关键帧上标记若干个关键点(如图c)。得到关键点的二维坐标和相机的位姿信息后,可以求解出关键点的三维坐标(如图d)。最后再将关键点的3D坐标反向投影到连续图像序列的各个帧当中,得到每个帧中的关键点二维坐标和对应的深度信息。
虽然本文采用的方法不需要物体的模型和每个点的深度信息,但为了与其他的方法进行比较,本文还是提供了物体的3D模型和深度信息。获取的方法是利用染色过后的目标物体,替代原透明目标物体的位置,然后利用RGB-D相机进行扫描拍摄,如下图所示。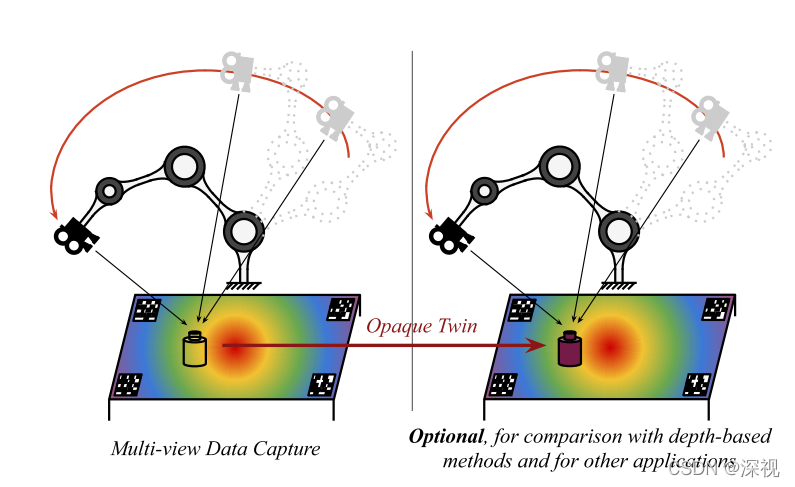
获得关键点图像与物体模型如下图所示
建立好数据集后,就可以利用数据对网络进行训练。作者利用一个透明目标检测算法,从左相机图像中检测到目标物体,并利用矩形框将其框选出来。因为双目图像中同一物体在左右两个相机中的位置不同,因此矩形框的尺寸要足够大,使得无论在右图中目标位置如何变化都能包含在该矩形框中,本文选择矩形框尺寸为180 _ 120。如下图所示
将框选后固定尺寸的双目图像堆叠起来,输入到KeyPose网络中,KeyPose网络的结构参考了KeyPointNet算法,为了获得足够大的上下文信息,本文采用了一系列以指数形式增长空洞卷积,在不压缩原输入图像分辨率的前提下,提高感受野范围。经过一系列卷积之后,可以通过两种方式获得关键点的坐标以及对应的视差(可以用于计算深度)。第一种是直接回归法,用3个1 _ 1的卷积层分别预测每个关键点的坐标U(图像坐标系下的横坐标),坐标V(图像坐标系下的纵坐标)和视差值D。第二种是通过热力图的方法,对于每个关键点
i
i
i,卷积神经网络都输出一个热力图,并且利用一个空间softmax层输出一个概率图
p
r
o
b
i
prob_i
probi,然后通过积分的方式获得一个中心点,该点坐标即为关键点的图像坐标UV。同理,视差值也可以通过3 _ 3的卷积获得一个热力图,然后与概率图
p
r
o
b
i
prob_i
probi进行卷积,中心点对应的热力值即为预测的视差值。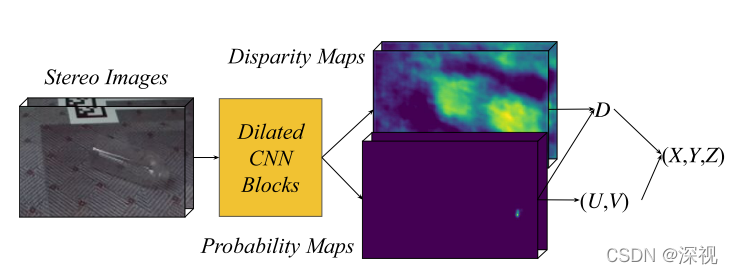
上述方法是通过将双目图像堆叠起来,输入到同一个网络中,以隐式的方式获取双目图像信息。当然也可以通过显式的方式来计算视差,分别用两个共享权重的卷积神经网络对左右输入图像进行处理,得到左右图的关键点坐标,并直接计算对应关键点横坐标之间的差值得到视差。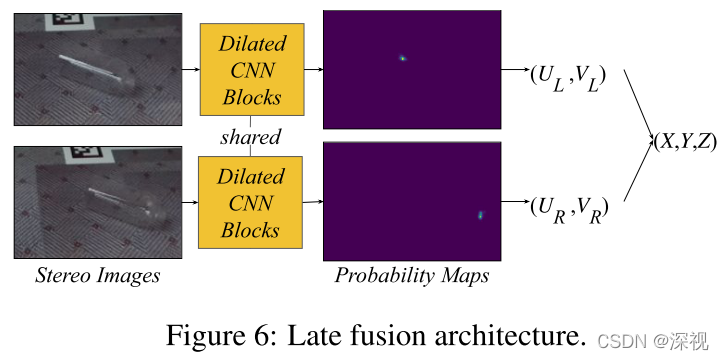
得到视差后,根据视差值、相机的焦距和双目相机之间的基线距离可以计算得到深度,已知关键点的图像坐标和对应的深度值就可以利用反透视变换计算关键点的三维坐标。
损失函数
本文设计了三个损失函数:关键点损失,投影损失和局部损失。关键点损失是对关键点预测的图像坐标和视差值进行监督,这比直接对关键点的三维坐标进行监督更加稳定,损失函数如下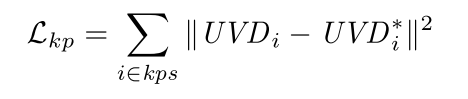
投影损失是将预测的关键点3D坐标投影到其他的视角下,并计算真实的关键点在该视角下的坐标,计算二者之间的差异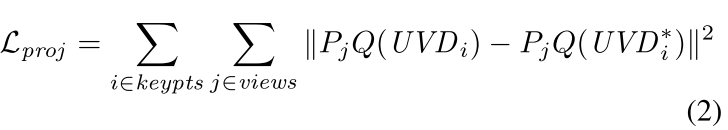
其中
Q
Q
Q表示将
U
V
D
UVD
UVD重投影得到
X
Y
Z
XYZ
XYZ 3D坐标的过程,
P
j
P_j
Pj表示将3D坐标反投影到视角
j
j
j中的过程。
局部损失则是对关键预测中的概率图
p
r
o
b
i
prob_i
probi进行监督,希望预测的概率图中心接近于真实的关键点位置
其中
N
(
U
V
i
∗
,
σ
)
\mathcal{N}(UV_i^_,\sigma)
N(UVi∗,σ)表示以关键点
i
i
i真实坐标为中心,以
σ
\sigma
σ为方差的圆形正态分布区域,
N
~
\widetilde{\mathcal{N}}
N
表示
N
\mathcal{N}
N的规则化相反数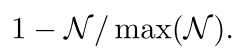
将三个损失函数乘以特定权重累加起来得到最终损失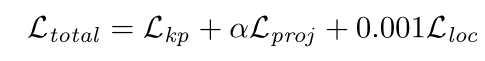
创新点
- 提出一种通过多视角图像序列和少量2D关键点标注信息,获取图像序列中3D关键点坐标数据集的方法
- 利用双目图像获取深度信息,并基于关键点的检测实现透明物体的位姿估计
算法评价
本文是我看到的第一篇使用双目相机进行位姿估计的文章,主要是解决了RGB-D相机难以获取透明物体深度信息的这一问题,并且提供了一个透明物体的双目图像数据集。但从文章提供的图像来看,本文的方法还是有很多局限的,比如目标物体的关键点都是选取的类似球心、圆柱体上下表面的形心等位置,当然这对于没有纹理的透明物体的确是比较重要的关键点,但是这个数据集训练得到的网络,估计很难泛化到其他更为复杂的物体上。另外,本文只是得到了目标物体关键点的三维坐标,若要求解整个物体的姿态还是需要物体的模型信息的。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。




评论(0)
您还未登录,请登录后发表或查看评论