

专栏开篇
该专栏会使用我编写的pytorch模板快速搭建实战项目,并会在实战过程中详细解释一些模型和函数库的使用方法,模板也会根据实战内容的需求而更新更加常用的模板
我会在后续的每一节里详细讲解遇到的优化器、计算损失的方法,从原理进行讲解,内容会比较多,但通熟易懂,公式这部分不需要特别懂,知道大概的原理即可,对原理不感兴趣的可以直接跳过。后续我也会制作一个导航栏用于快速查阅之前讲过的知识点。后续如果再遇到讲过的知识点的话,会直接采用超链接的形式。欢迎大家订阅,我会一直更新下去的。
简介
该模板的作用
自动完成以下内容
- 自动保存每个文件随着epoch增加的训练、验证和测试损失的图
- 自动保存每个文件随着epoch增加的训练、验证和测试准确率的图
- 自动保存所有文件随着文件增加的训练、验证和测试损失的图
- 自动保存所有文件随着文件增加的训练、验证和测试准确率的图
- 自动更新网络结构,并将使得每个文件准确率最高的模型和网络结构记录下来
- 自动更新网络结构,并将使得每个文件准确率最高的模型和网络结构记录下来
- 增加早停类,使得损失下降小于某个阈值的时候进入下一个epoch,可以快速进入下一个最优网络结构
- 在不同epoch自动调整学习率
使研究者只需要关注数据预处理和模型定义这两层即可
分别对应模板的00data_preprocess_template.py和01pytorch_template.py
模板地址
GitHub: https://github.com/1571859588/PyTorch_Template
版本与更新
目前版本:1.0
由于这个模板是在我自己认为可能最常用的保存和更新pth的方法,存在一些主观性,所以如果有问题的话欢迎评论区和以下的方式提意见~
如有更好的意见,欢迎在github的issues提问,欢迎大家在pull requests更新模板
后续如果更新了版本的话,我会在本专栏里面用到新版本的时候提醒新版本的更新内容和链接地址,所以大家不用特别担心自己的版本跟文章的版本不一致的情况
贡献与开源声明
该模板由本人一人编写,仅用于开源,不可商用,商用必究
模板
简介
该pytorch模板 目录为一个整体,不能缺少任何一个模块
- 需要更改的部分:00,01
01preprocessed_data的训练集、测试集和验证集都需要存在,且名称要对应,这样才会有图片- 自动生成最佳模型及网络结构,并保存最佳模型到
best_model中,并将过程中的训练和验证损失图像保存到loss_fig中。文件名均以准确率.pth或准确率.png命名
模板使用方法
只有00,01以数字开头的文件需要改,其他都是工具文件
执行顺序为数字顺序
目录结构
├─pytorch模板
│ │ 00data_preprocess_template.py
│ │ 01pytorch_template.py
│ │ readme.md
│ │ template_utils.py
│ │
│ ├─00raw_data
│ │ ├─test_data
│ │ ├─train_data
│ │ └─valid_data
│ ├─01preprocessed_data
│ │ ├─test_data
│ │ ├─train_data
│ │ └─valid_data
│ ├─best_model
│ │ ├─csvs
│ │ └─total
│ ├─early_stop_model
│ └─figures
│ ├─csvs_acc_figs
│ ├─csvs_loss_figs
│ ├─total_acc_figs
│ └─total_loss_figs
cmd输入
tree /f即可显示树形结构
各模块作用
00data_preprocess_template.py 数据预处理
这个文件将00raw_data目录的原生数据集转为符合后续代码要求的数据集格式,即3个csv文件,分别为训练集、验证集和测试集,并将文件存放在01preprocessed_data目录里相应train_data,valid_data ,test_data目录
以上csv文件只有最后一列为标签,其余均为数据
01pytorch_template.py 训练模型
该文件为模型定义和训练代码
该文件使用已经经过预处理的01preprocessed_data的数据集进行训练,验证和测试,并将经测试得到最高模型的保存到best_model目录中,并将训练和验证损失记录到loss_fig目录中。文件名均以准确率.pth 或准确率.png命名
template_utils.py 工具函数
Dataset_name 类
作用:
- 自定义数据集类,通过自动
初始化参数:
flag:flag只能取 ‘train‘、’valid‘ 、 ‘test‘ 之中的一个,一次性只能是训练集、验证集和测试集的一种,默认值为traincsv_paths:数组形式,分别代表训练集、验证集和测试集的csv文件地址,默认值为['./data_train.csv', './data_valid.csv', './data_test.csv']
成员方法:
- 已写好
__getitem__和__len__,可以直接用于DataLoader
argparse 类
作用:
- 封装超参数,可以直接调用argparse对象的属性
初始化参数:
csv_paths:数组形式,表示训练集、验证集和测试集的文件夹地址。如['./01preprocessed_data/train_data/','./01preprocessed_data/valid_data/','./01preprocessed_data/test_data/'],实际上就是模板对应的文件夹hidden_size:数组形式,表示各隐藏层的神经元数目。默认值为Nonelr_adjust:字典数组形式,表示在不同epoch时调整的学习率,键为第几个epoch,值为学习率。默认值为Noneinput_size:输入维度,默认值为30output_size:输出维度,默认值为12epochs:共有多少个epochs,默认值为30original_lr:初始学习率,默认值为0.001patience:早停类的耐心,默认值为4cuda_id:若传入的cuda_id不可用时,则使用cpu,默认值为0
成员方法:
find_cuda_id- 作用:找到可用的gpu,并返回
cuda_id - 无参数
- 作用:找到可用的gpu,并返回
check_cuda- 作用:检查输入的
cuda_id是否可用 - 无参数
- 作用:检查输入的
成员属性:
csv_paths:数组形式,表示训练集、验证集和测试集的文件夹地址。如['./01preprocessed_data/train_data/','./01preprocessed_data/valid_data/','./01preprocessed_data/test_data/'],实际上就是模板对应的文件夹hidden_size:数组形式,表示各隐藏层的神经元数目。默认值为Nonelr_adjust:字典数组形式,表示在不同epoch时调整的学习率,键为第几个epoch,值为学习率。默认值为Noneinput_size:输入维度,默认值为30output_size:输出维度,默认值为12epochs:共有多少个epochs,默认值为30original_lr:初始学习率,默认值为0.001patience:早停类的耐心,默认值为4device:即可用的设备,cpu或gpu
EarlyStopping 类
作用:
- 早停类,在训练过程中发现验证损失下降幅度较低且超过耐心值的时候终止并保存模型,提前进入下一个epoch,节省资源和时间
初始化参数:
patience:耐心值,表示能够允许损失下降幅度较低即不提升的次数,默认值为7verbose:表示是否打印信息,默认值为Falsedelta:损失下降幅度阈值,如果损失下降幅度小于这个值,则不计为提升,默认值为0
成员方法:
__call__- 作用:判断是否超过耐心,若超过耐心则自动保存模型
- 参数:
val_loss:某个epoch下的验证损失值model:自定义模型对象path:超过耐心的时候模型保存的位置
- 返回值:
- 无
成员属性:
early_stop:bool类型,为True时表示超过耐心,此时需要自行用这个成员属性来控制进入下一个epoch
evaluate
作用:
- 用于模型自动训练、验证和评估
参数:
dataloader:数据加载类,必须是DataLoader对象model:神经网络模型,即自定义模型对象device:计算设备,cpu或gpu,可以直接输入argparse对象.deviceflag:flag只能取 ‘train‘、’valid‘ 、 ‘test‘ 之中的一个,分别表示训练、验证、测试criterion:损失函数,输入对象必须是损失函数对象,如torch.optim.Adam()optimizer:优化器对象,默认值是Noneepoch:第几个epoch,用于显示打印信息,默认值是Noneepochs:有多少个epoch,用于显示打印信息,默认值是None
返回值:(顺序从上往下一一对应)
np.average(valid_loss):浮点数形式,表示这个epoch下的平均损失np.average(accuracys):浮点数形式,表示这个epoch下的平均损失accuracys:数组形式,表示这个epoch下各batch下的准确率valid_loss:数组形式,表示这个epoch下各batch下的损失model:训练完成后的模型对象,仅flag为train时生效optimizer:训练完成后的优化器对象,仅flag为train时生效
save_checkpoint
作用:
- 用来保存模型参数和隐藏层
参数:
model:自定义模型对象optimizer:优化器对象epoch:现在在第几个epoch,默认值是Nonefilepath:模型保存地址,默认值是'./best_model/1.pth'
返回值:
- 无
load_checkpoint
作用:
- 用来加载已保存的模型,并查看模型、优化器和隐藏层的参数
参数:
filepath:已保存的以pth为后缀的模型地址model:加载到哪个模型对象中,注意保存和加载的模型网络结构一定要一样才可以加载optimizer:加载到哪个优化器对象中,注意保存和加载的优化器一定要一样才可以加载device:将保存的模型加载到cpu还是gpu上,一般取args.device即上面讲的超参数类即可
返回值:
model:已加载的模型optimizer:已加载的优化器epoch:模型保存的时候处于第几个epoch,方便后续继续训练checkpoint['hidden_size']:表示隐藏层的参数
save_figure
作用:
- 该函数用于画图,自动保存图像到指定位置,图像横坐标表示百分比
参数:
train:数组形式,训练损失/准确率valid:数组形式,验证损失/准确率test:数组形式,测试损失/准确率save_path:图像保存位置,默认地址为./total_loss_figs/1.png
00raw_data (不一定)
这里考虑到每个数据集的存放方式不一致,可以不用严格按照这里的目录结构放好
01preprocessed_data
需要严格将训练集、验证集和测试集存放到相应的文件夹中,并且按序从0放好,以更好地对应,且最后一列为标签
train_data
存放训练数据集
valid_data
存放验证集
test_data
存放测试集
best_model
保存准确率最高的模型,以准确率命名的pth模型
csvs
该目录下会根据01preprocessed_data 里的文件保存对应训练集的最佳模型
total
该目录下会根据01preprocessed_data 里的文件保存对应训练集的最佳模型
early_stop_model 早停模型
记录下某个epoch最好的模型,文件名以验证集平均准确率为名字,与上面的best_model 不一样
figures
以准确率命名的总损失和总准确率折线图,与上面的best_model 一一对应
csvs_acc_figs
该目录下会根据01preprocessed_data 里的文件保存对应的训练、验证、测试随着epoch 增加的准确率图像
csvs_loss_figs
该目录下会根据01preprocessed_data 里的文件保存对应的训练、验证、测试随着epoch 增加的损失图像
total_acc_figs
该目录下会根据01preprocessed_data 里所有文件保存对应的测试集随着csvs 增加,即随着被试训练后得到的准确率图像
total_loss_figs
该目录下会根据01preprocessed_data 里所有文件保存对应的测试集随着csvs 增加,即随着被试训练后得到的损失图像
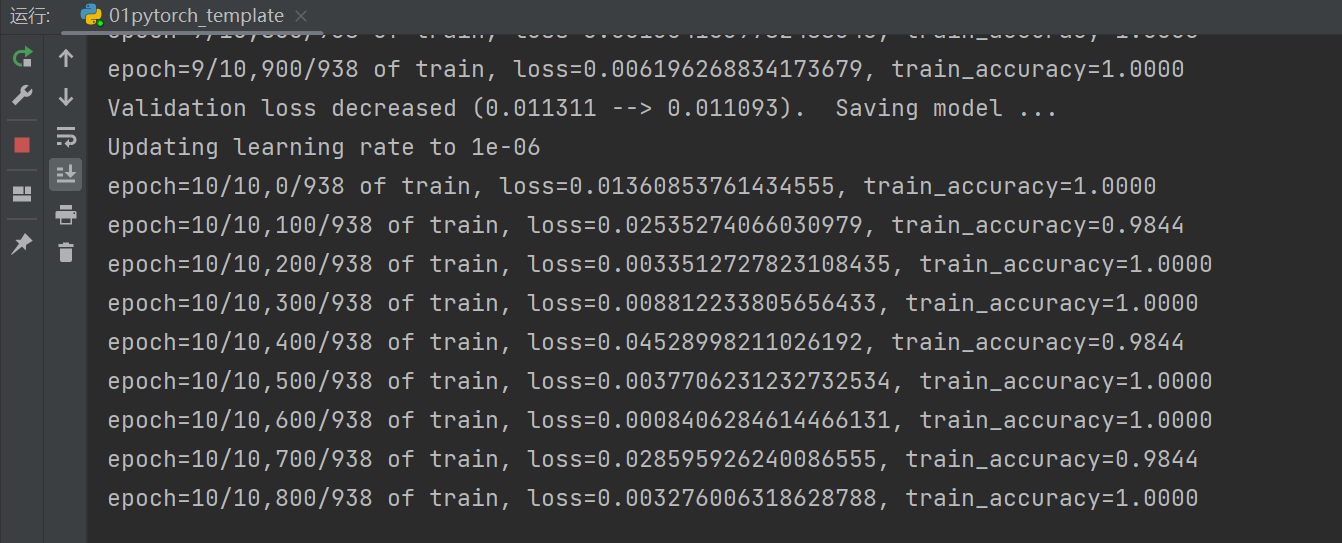
运行结果图
运行结果
best_model
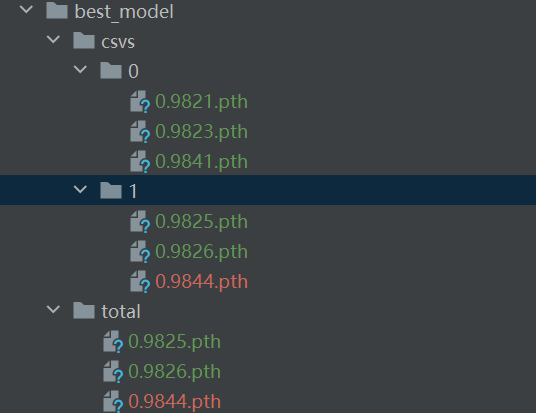
文件名即为准确率
figure
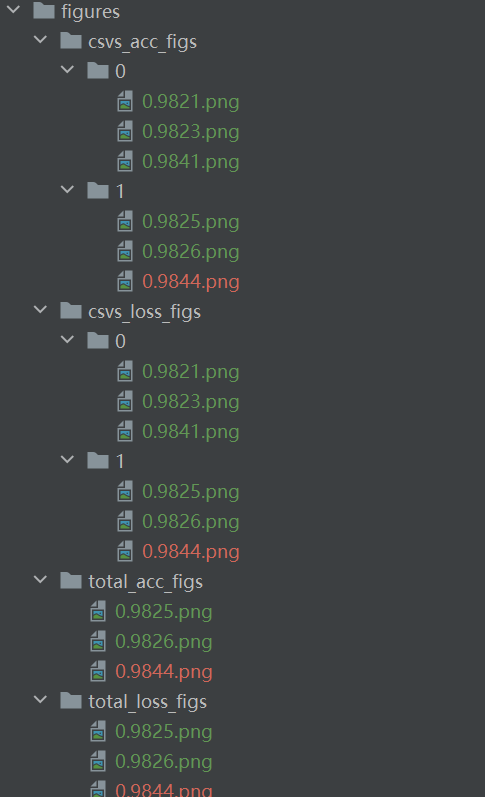
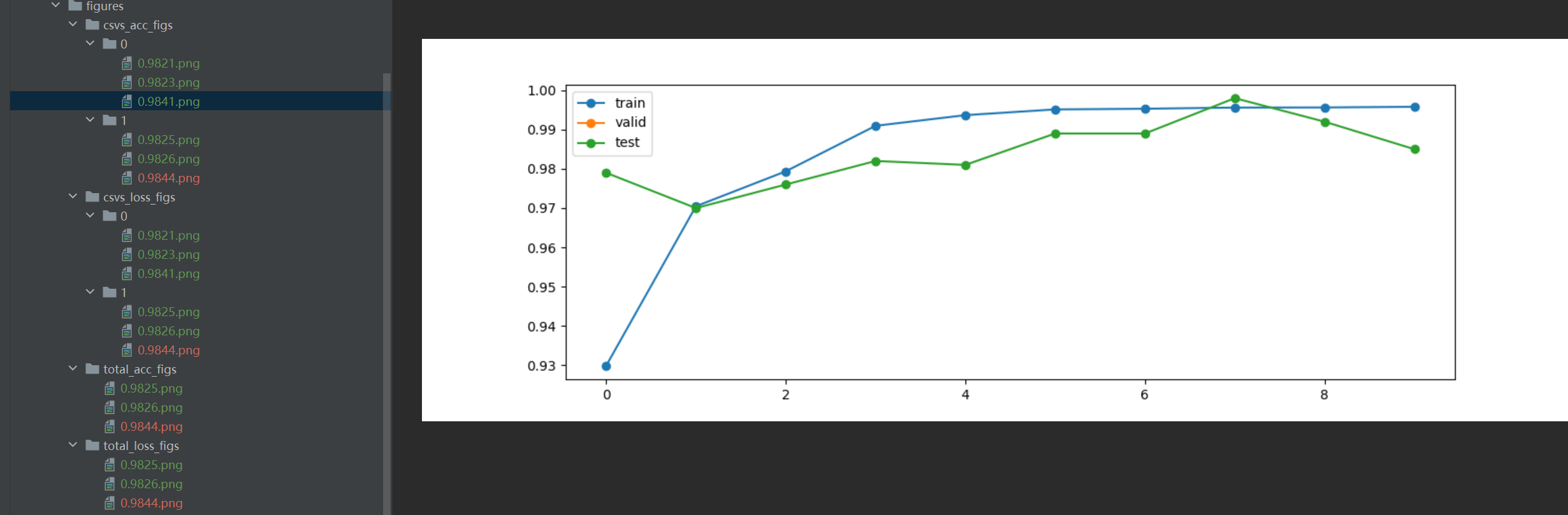
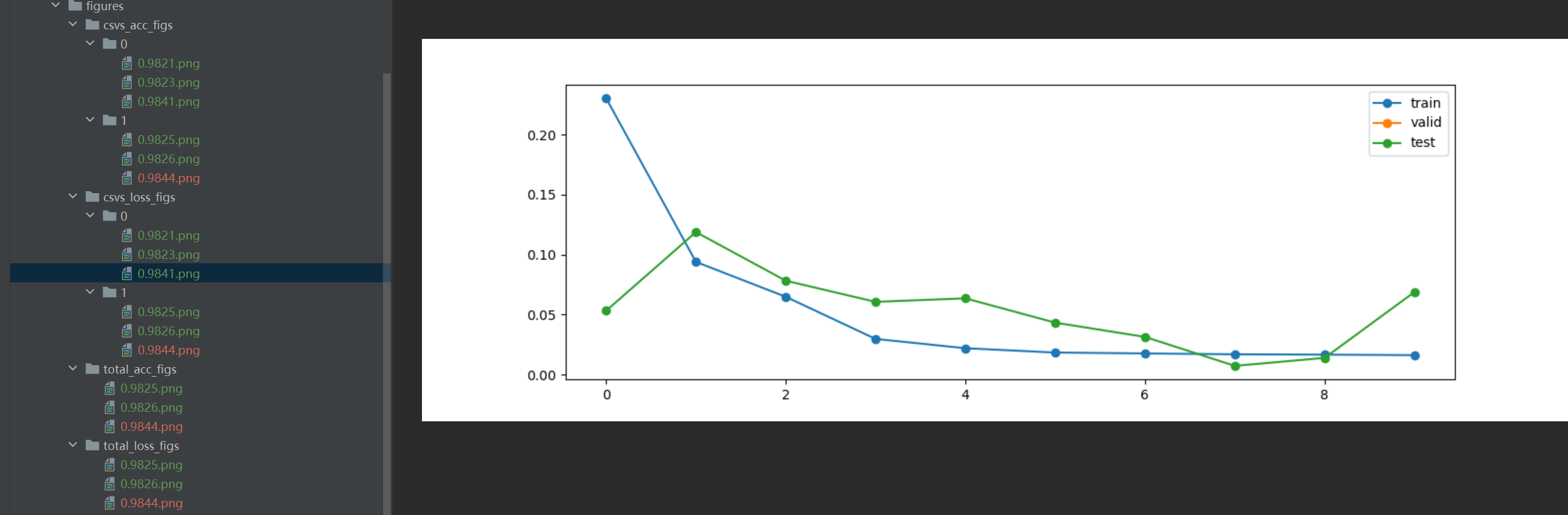
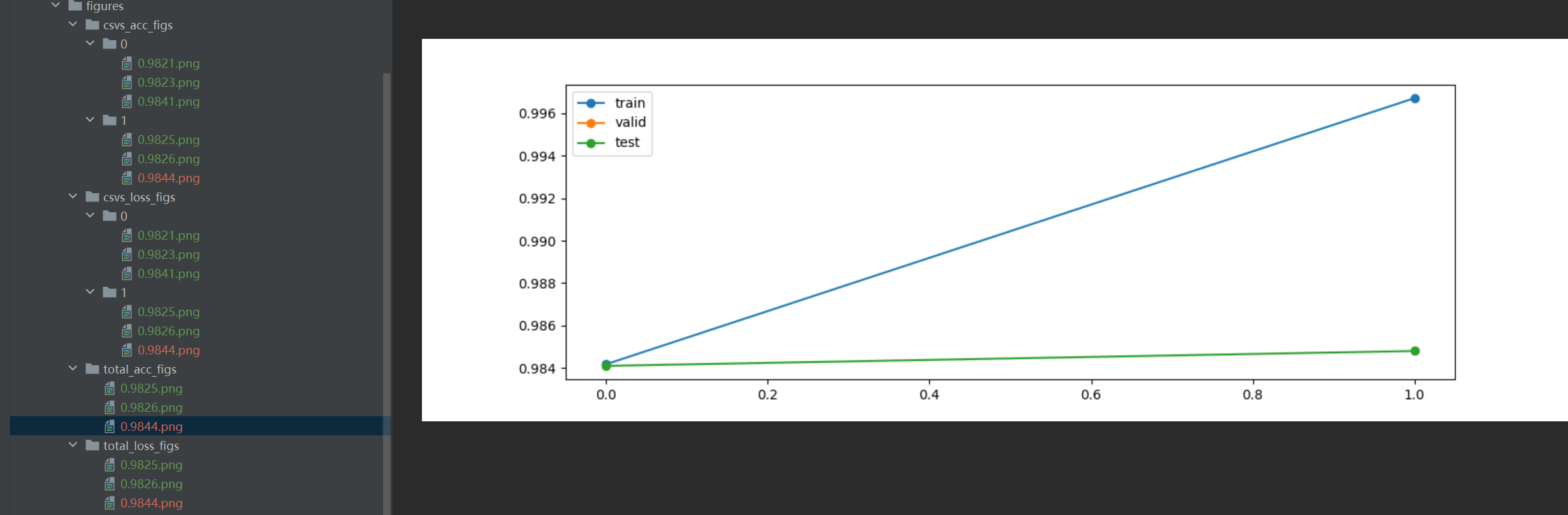
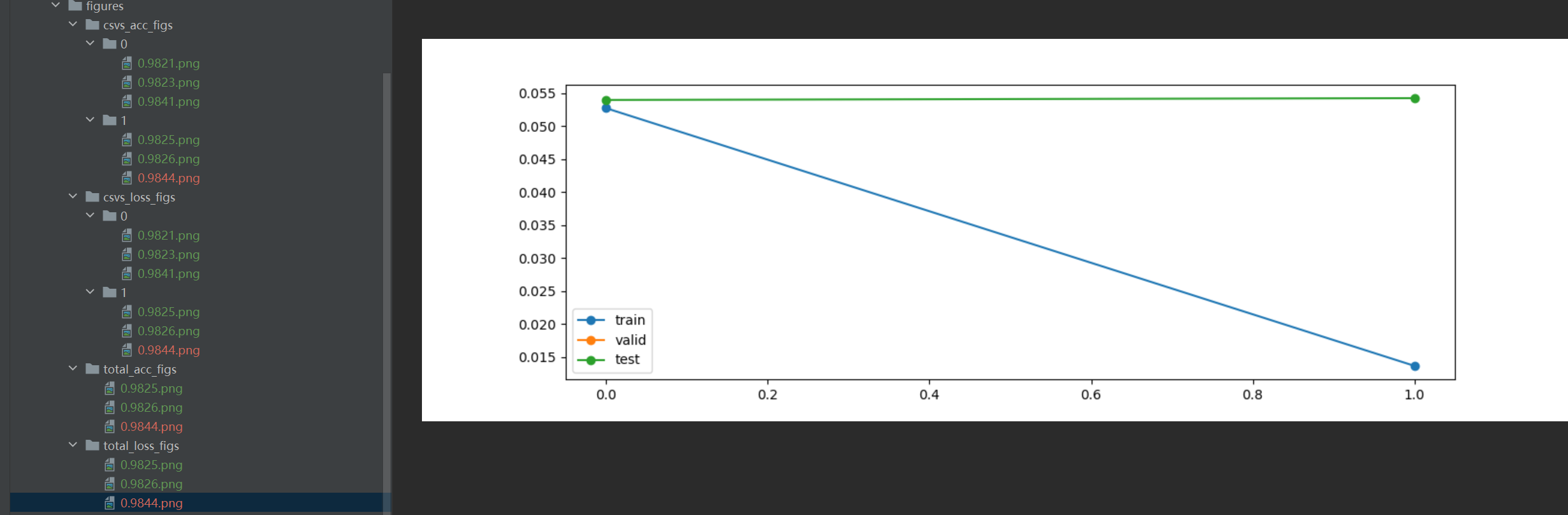
文件名都是一一对应的



评论(0)
您还未登录,请登录后发表或查看评论