

0. 简介
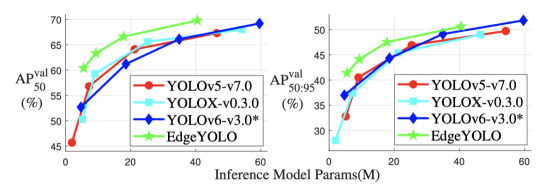
Yolo家族从1-8,目前已经迭代了很多次,但是他们期望的仍然是能够以更低的算力去运行精度更高更快速的算法.目前《EdgeYOLO: An Edge-Real-Time Object Detector》提出了一种基于最先进的YOLO框架的高效、低复杂度和无锚点的目标检测器,可以在边缘计算平台上实时实现。同时文中提到开发了一种增强的数据增强方法,有效抑制训练期间的过拟合,并设计了一种混合随机损失函数,以提高小物体的检测精度。文中结果展示基准模型可以在MS COCO2017数据集中达到50.6%的AP50:95和69.8%的AP50的准确率,在VisDrone2019-DET数据集中达到26.4%的AP50:95和44.8%的AP50的准确率,并且在边缘计算设备Nvidia Jetson AGX Xavier上满足实时要求(FPS≥30)。模型目前也可以在Github中拿到。
1. 主要贡献
本文的贡献总结如下:
- 设计了一种无锚点的目标检测器,可以在边缘设备上实时运行,在MS COCO2017数据集中达到50.6%的AP准确率
- 提出了一种更强大的数据增强方法,进一步确保训练数据的数量和有效性
- 在我们的模型中使用可重新参数化的结构来减少推断时间
- 设计了一种损失函数,以提高小物体的精度。
2. Enhanced-Mosaic & Mixup
许多实时目标检测器在训练过程中使用Mosaic+Mixup 策略进行数据增强,可以有效地缓解训练过程中的过拟合情况。如图3(a)和(b)所示,有两种常见的组合方法,在数据集中单个图像具有相对充足的标签时表现良好。由于数据增强中的随机过程,数据加载器可能会提供没有有效对象的图像,而在标签空间中仍有响应,如图3(a),并且这种情况的概率随着每个原始图像中标签数量的减少而增加。
我们在图3©中设计了一种数据增强结构。首先,我们对几组图像使用Mosaic方法,因此组数可以根据数据集中单个图像的平均标签数量的丰富程度进行设置。然后,通过Mixup方法将最后一个简单处理的图像与这些Mosaic处理的图像混合。在这些步骤中,我们的最后一个图像的原始边界在转换后的最终输出图像的边界内。这种数据增强方法有效地增加了图像的丰富性以缓解过拟合,并确保输出图像必须包含足够的有效信息。
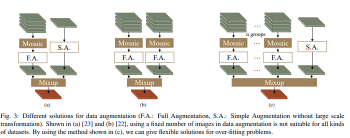
图3:数据增强的不同解决方案(F.A.:完全增强,S.A.:没有大规模变换的简单增强)。如(a)[23]和(b)[22]所示,使用固定数量的图像进行数据增强并不适用于所有类型的数据集。通过使用图(c)中所示的方法,我们可以为过拟合问题提供灵活的解决方案。
3. 轻量级解耦头(比较重要)
图4中的解耦头首先在FCOS [15]中提出,然后被用于其他无锚点目标检测器,如YOLOX [23]。确认使用解耦结构作为最后几个网络层可以加速网络收敛并提高回归性能。
由于解耦头采用了分支结构,导致额外的推断成本,因此提出了Efficient Decoupled Head [20],具有更快的推断速度,将中间的3×3卷积层的数量减少到仅一个层,同时保持与输入特征图相同的更大通道数。然而,在我们的实验测试中,随着通道数和输入大小的增加,这种额外的推断成本变得更加明显。因此,我们设计了一个更轻的解耦头,通道和卷积层更少。此外,我们为了获得更好的回归性能,将隐式表示层[24]添加到所有最后的卷积层中。通过重新参数化的方法,隐式表示层被集成到卷积层中,以降低推断成本。盒子和置信度回归的最后卷积层也被合并,这样模型可以进行高并行计算的推断。

图4:如图所示,我们设计了一个更轻量级但更高效的解耦头。通过重新参数化技术,我们的模型在减少精度损失的情况下获得了更快的推断速度。
4. 分阶段的损失函数 (比较重要的点)
对于目标检测,损失函数通常可以写成如下形式:
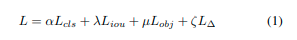
其中,L_{cls}、L_{iou}、L_{obj}和L_∆分别代表分类损失、IOU损失、目标损失和规则化损失,而α、λ、µ、ζ则是超参数。在我们的实验中,我们将训练过程分为三个阶段。
在第一阶段,我们采用最常见的损失函数配置之一:IOU损失使用gIOU损失,分类损失和目标损失使用平衡交叉熵损失,并将规则化损失设置为零。在最后几个数据增强启用的时期,训练过程进入第二阶段。
在第二阶段,分类损失和目标损失的损失函数被混合随机损失(Hybrid-Random Loss)所取代。同时,我们逐渐增加规则化损失的权重,以确保模型的泛化能力。
在第三阶段,我们进一步增加规则化损失的权重,并在每次训练迭代时随机选择损失函数的一部分进行计算,以进一步增加模型的泛化能力。
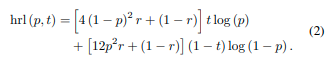
其中,p代表预测结果,t代表真实标签,r是一个0到1之间的随机数。对于一张图片中的所有结果,我们有如下公式
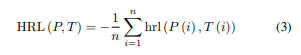
它展现了在小目标精度和总精度之间更好的平衡。当进入第三个阶段时,我们关闭数据增强,将L1损失作为规则化损失,将gIOU损失替换为cIOU损失。更多细节如下:
训练:文中模型在具有4个RTX 3090 GPU的工作站上部署了训练环境。作者选择ELAN-Darknet [22]作为我们模型的骨干网络,并在轻型模型中用RepConv [25]层替换了一些3×3卷积层。此外作者使用随机梯度下降(SGD)优化器训练网络,最大学习率为0.005,批量为32张图片。每张图片的最大学习率固定为1/6400,这意味着最大学习率随批量大小而变化。文中从第5个warm-up epochs开始训练,学习率从0逐渐增加到0.005。考虑到MS COCO2017和VisDrone2019-DET具有丰富的标签,作者将mosaic组数设置为2。
推理:作者在具有512个CUDA核心的NVIDIA Jetson AGX Xavier上测试每个模型的推理,使用TensorRT版本7.1.3.0以FP16精度测量FPS。 主要训练超参数。
• Weight decay:0.0005
• Momentum:0.9
• Total epochs:300
要查看更多超参数,请访问网站:https://github.com/LSH9832/edgeyolo,所有超参数都在文件“edgeyolo/train/default.yaml”中。



评论(0)
您还未登录,请登录后发表或查看评论