

0. 简介
环视BEV已经是很多场景中需要的功能,也是视觉代替激光雷达的有效解决方案,而《SurroundOcc: Multi-camera 3D Occupancy Prediction for Autonomous Driving》一吻则代表了这个领域的SOTA算法,文中通过多帧点云构建了稠密占据栅格数据集,并设计了基于transformer的2D-3D Unet结构的三维占据栅格网络。同时也开源立相关的算法,并可以在Github中找到。
1. 主要贡献
文中提出了一种SurroundOcc方法,旨在通过多摄像头图像输入来预测密集和准确的三维占据情况。
- 我们首先使用一个二维骨干网络从每个图像中提取多尺度特征图。然后,我们执行二维-三维空间注意力,将多摄像头图像信息提升到三维体积特征而不是BEV特征。
- 然后,我们使用三维卷积网络逐步上采样低分辨率体积特征,并将其与高分辨率特征融合,以获得细粒度的三维表示。在每个级别上,我们使用衰减加权损失来监督网络。
- 为了避免昂贵的占据注释,我们设计了一个流程,只使用现有的三维检测和三维语义分割标签生成密集的占据真值。具体而言,我们首先分别组合动态物体和静态场景的多帧点云。然后,我们利用Poisson重建[24]算法进一步填补空洞。最后,我们使用NN和体素化来获得密集的三维占据标签。有了密集的占据真值,我们训练模型并在nuScenes [7]数据集上与其他最先进的方法进行比较。定量结果和可视化结果都证明了我们方法的有效性。
2. 整体流程
2.1 问题阐述
在这项工作中,我们的目标是通过多摄像头图像I = {I_1,I_2,···I_N}来预测周围场景的三维占用情况。形式上,三维占用预测表示为: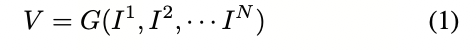
G是一个神经网络,V ∈ \mathbb{R} ^{H×W×Z}是3D占用。V的值介于0和1之间,表示网格的占用概率。将V提升为一个(L, H, W, Z)张量,我们可以获得3D语义占用,其中L是类别数,类别0表示非占用网格。
3D占用是多摄像机3D场景重建的良好表示。首先,由于3D占用是在3D空间中预测的,理论上满足多摄像机一致性。其次,网络可以根据周围的语义信息预测被遮挡的区域,这在深度估计中是不可用的。第三,3D占用很容易扩展到其他下游任务,如3D语义分割和场景流估计。
2.2 概述
图2展示了我们方法的流程。给定一组周围的多摄像头图像,我们首先使用一个骨干网络(例如ResNet-101 [19])提取N个摄像头和M个层级的多尺度特征X = {{X^j_i}^N_{i=1}}^M_{j=1}。对于每个层级,我们使用一个变换器来融合多摄像头特征和空间交叉注意力。2D-3D空间注意力层的输出是一个3D体积特征,而不是BEV特征。然后,我们利用3D卷积网络来上采样和组合多尺度体积特征。每个层级的占用预测都受到生成的稠密占用地面真值的监督,其中损失权重会衰减。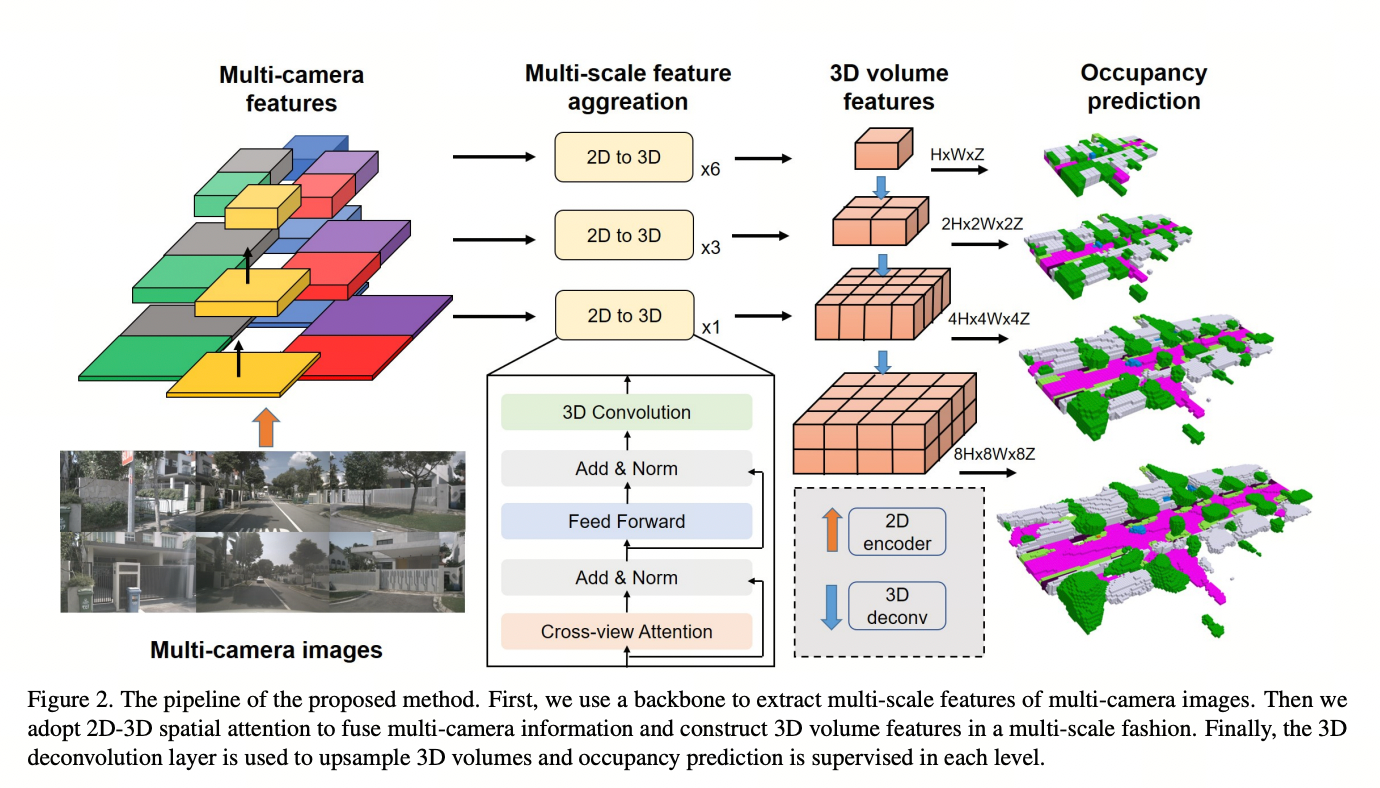
图2. 提出方法的流程。首先,我们使用骨干网络提取多摄像头图像的多尺度特征。然后,我们采用2D-3D空间注意力来融合多摄像头信息,并以多尺度方式构建3D体积特征。最后,使用3D反卷积层对3D体积进行上采样,并在每个层级上进行占据预测的监督
2.32D-3D空间注意力
许多3D场景重建方法[8, 37]通过将多视角2D特征重新投影到已知姿态的3D体积中,将2D特征整合到3D空间中。网格特征通过简单地对该网格中的所有2D特征进行平均计算得到。然而,这种方法假设不同视角对3D体积的贡献相等,这并不总是成立,特别是当一些视角被遮挡或模糊时。
为了解决这个问题,我们利用跨视角注意力来融合多摄像机特征。我们将3D参考点投影到2D视图中,并使用可变形注意力[71, 29]来查询点并聚合信息。如图3所示,我们不再使用2D BEV查询,而是构建3D体积查询以进一步保留3D空间信息。具体而言,3D体积查询被定义为Q ∈ \mathbb{R}^{C×H×W×Z}。对于每个查询,我们根据给定的内参和外参将其对应的3D点投影到2D视图中。我们只使用3D参考点所命中的视图。然后我们在这些投影的2D位置周围采样2D特征。跨视角注意力层的输出F ∈ \mathbb{R}^{C×H×W×Z}是根据可变形注意力机制对采样特征进行加权求和的结果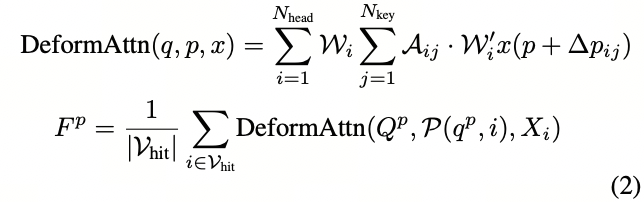
F^p和Q^p 表示输出特征和3D体积查询的第p个元素。q^p是查询的相应3D位置,P是3D到2D投影函数。V_{hit}表示3D查询点的命中视图。W_i和W’_i是可学习的权重,A_{ij}∈[0,1]是通过查询和关键字的点积计算得出的注意力权重。x(p+∆p_{ij})是位置p+∆p_{ij}处的2D特征。我们不使用昂贵的3D自注意力,而是使用3D卷积来交互相邻的3D体素之间的特征。
图3. 基于3D和BEV的交叉视图注意力的比较。基于3D的注意力可以更好地保留3D信息。对于每个3D体积查询,我们将其投影到相应的2D视图中进行特征采样
2.4 多尺度占用预测(重点内容)
我们进一步将2D-3D空间注意力扩展到多尺度的方式。与3D检测任务不同,3D场景重建需要更多的低级特征来帮助网络学习细粒度的细节。为了解决这个问题,我们设计了一个2D-3D U-Net架构。具体来说,给定多尺度的2D特征X = {{X^j_i}^N_{i=1}}^M_{j=1},我们采用不同数量的2D-3D空间注意力层来提取多尺度的3D体积特征{F_j ∈ \mathbb{R}^{C_j×H_j×W_j×Z_j}}^M_{j=1}。然后,我们使用3D反卷积层对第j-1级的3D体积特征Y_{j-1}进行上采样,并与F_j融合:

对于每个层级,网络输出一个具有不同分辨率的占用预测结果V_j ∈ \mathbb{R}^{C_j×H_j×W_j×Z_j}。为了获得强大的高级和低级3D特征,网络在每个尺度上都进行监督。具体而言,我们使用交叉熵损失和场景类别亲和损失作为监督信号,这些损失在[8]中有介绍。对于3D语义占用预测,我们采用多类交叉熵损失,对于3D场景重建,我们将其改为二类形式。由于高分辨率预测更重要,我们使用衰减的损失权重α_j = \frac{1}{2^j}进行第j层级的监督。
3.密集占用地面真实情况(构建稠密occupancy数据集,本文重点)
在我们的实验中,我们发现由稀疏的LiDAR点监督的网络无法预测足够密集的占用情况。因此,有必要生成密集的占用标签。然而,正如在SemanticKITTI [2]中提到的那样,注释具有数百万个体素的3D场景的密集占用是复杂的,需要巨大的人力。为此,我们设计了一个流程,在不需要额外的人工注释的情况下,利用现有的3D检测和3D语义分割标签生成密集的占用地面真实情况,如图4所示。一种直观的方法是直接将多帧LiDAR点序列转换为统一的坐标系,然后将连接的密集点转换为体素网格。然而,这种直接的解决方案只适用于完全静态的场景,并忽略了移动物体。此外,多帧点云不够密集,仍然存在许多空洞,这将导致错误的占用标签。为了解决这些问题,我们提出了分别拼接动态物体和静态场景的多帧LiDAR点的方法。此外,我们采用泊松重建[24]来填补空洞,并将得到的网格转换为体素以获得密集的体积占用情况。由于LiDAR扫描表面点,我们的方法还生成表面占用情况。
3.1. 多帧点云拼接
我们提出了一个两流程的流程,分别拼接静态场景和物体,并在体素化之前将它们合并成一个完整的场景。具体而言,对于每一帧,我们首先根据3D边界框标签从LiDAR点中剪切出可移动的物体,以便我们可以获得静态场景和可移动物体的3D点。在遍历场景中的所有帧之后,我们分别将收集到的静态场景片段和物体片段集成到一个集合中。为了合并多帧片段,我们然后通过已知的校准矩阵和自我姿态将它们的坐标转换为世界坐标系。我们将转换后的静态场景片段和物体片段表示为P_{ss} = {P^1_{ss}, P^2_{ss}, · · · P^n_{ss}}和P_{os} = {P^1_{os}, P^2_{os}, · · · P^m_{os}},其中n和m分别是序列中的帧数和物体数。注意,不同帧中的相同物体可以根据边界框索引进行识别。因此,我们可以将整个静态场景表示为P_s = [P^1_{ss}, P^2_{ss}, · · · P^n_{ss}],而物体表示为P_o = [P^1_{os}, P^2_{os}, · · · P^m_{os}],其中[·]是连接运算符。最后,根据当前帧的物体位置和自我姿态,可以通过合并静态场景和物体来获得该帧的3D点:P = [T_s(Ps), T_o(Po)],其中T_s和T_o分别是从世界坐标系到当前帧坐标系的静态场景和物体的转换。通过这种方式,当前帧的占用标签利用了序列中所有帧的LiDAR点。
3.2 使用泊松重建方法增加密度
虽然P的密度比单帧LiDAR要大得多,但仍然存在许多间隙,并且点的分布不均匀,这是由于有限的LiDAR光束引起的。为了解决这个问题,我们首先根据局部邻域的空间分布计算法向量。然后,我们使用泊松表面重建方法[24]将P重建为三角网格M,其输入是带有法向量的点云,输出是一个三角网格(见图4)。得到的网格M = {V, E}用均匀分布的顶点V填充了点云的空洞,这样我们可以进一步将网格转换为密集的体素V_d。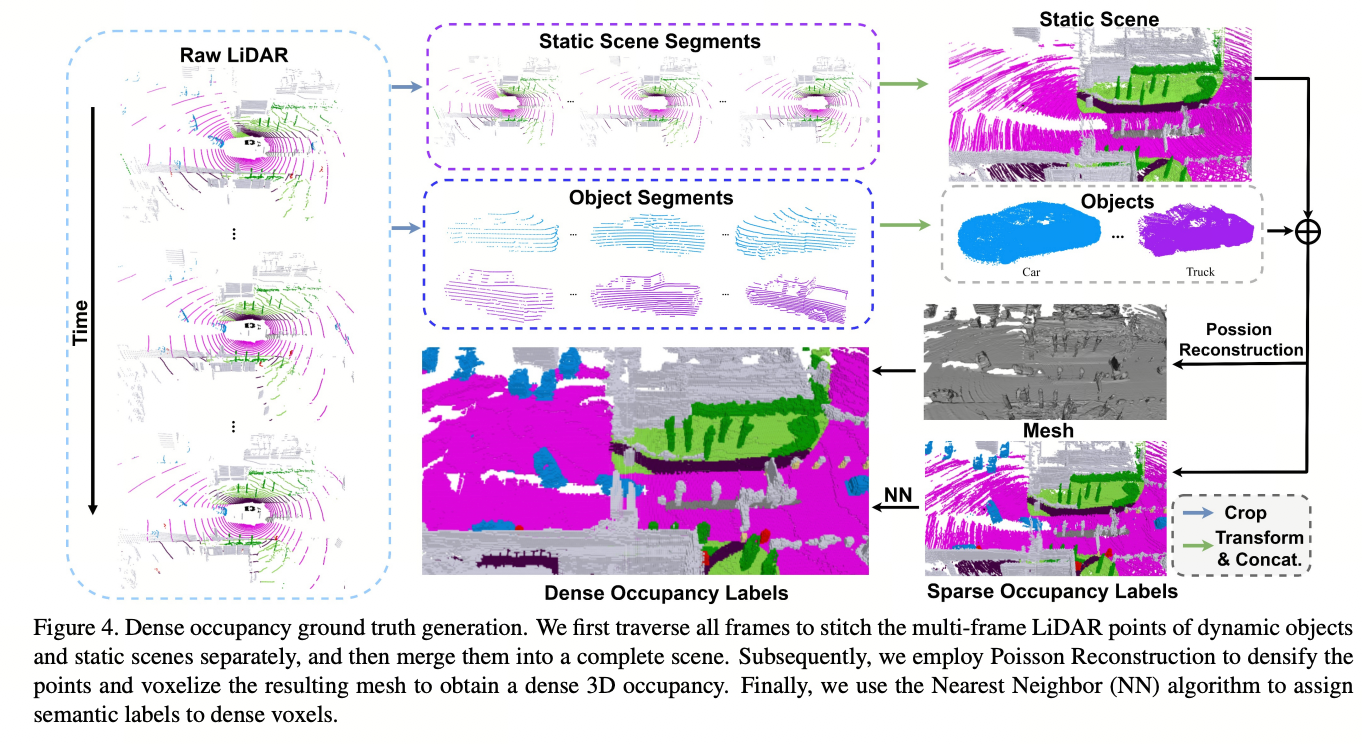
图4. 密集占用地面真实生成。我们首先遍历所有帧,分别将动态物体和静态场景的多帧LiDAR点进行拼接,然后将它们合并成一个完整的场景。随后,我们使用泊松重建方法来增加点的密度,并将生成的网格进行体素化,以获得密集的三维占用情况。最后,我们使用最近邻算法将语义标签分配给密集的体素。
3.3. 使用最近邻算法进行语义标注
在获得密集体素V_d的占用情况之后,我们的目标是为每个体素分配语义标签,因为位置重建只能应用于三维空间,而不能应用于语义空间。为此,我们提出利用最近邻(NN)算法来搜索每个体素的最近语义标签。具体而言,我们首先将带有语义信息的P进行体素化,得到比V_d稀疏的体素V_s,这是由于有限的LiDAR光束。然后对于V_d中的每个占用体素,我们使用NN算法在V_s中搜索最近的体素,并将语义标签分配给它。需要注意的是,这个过程可以通过在GPU上进行并行计算来加速。因此,V_d中的所有占用体素都可以从V_s中获得它们的语义标签。
图5显示了单帧LiDAR点云、稀疏占用标签和密集占用标签之间的详细视觉比较。我们观察到,我们的密集体素可以提供更加真实的占用标签,并具有清晰的语义边界。
我们认为将稀疏语义标签传播到密集语义标签并不是一个简单的问题,因为它是一个不适定的问题。所提出的多帧点云拼接方法可以聚合多帧语义信息,并为NN提供足够密集的参考点。然而,我们发现NN对原始LiDAR语义标签中的注释噪声非常敏感,我们将在未来的工作中尝试解决这个问题。

图5. 不同占用标签的比较。与单帧LiDAR点和从多帧点转换而来的稀疏占用相比,我们的密集体素能够提供更真实的占用标签



评论(0)
您还未登录,请登录后发表或查看评论