

0. 简介
最近世界模型的概念也比较火,世界模型可以无监督方式进行快速训练,以学习环境的稀疏时空表征。通过使用提取自世界模型的特征作为智能体的输入,训练面向任务的小规模控制器,用简单的策略。甚至可以完全通过由世界模型本身生成的虚幻梦境训练本文的智能体,并把从中学会的策略迁移进真实环境之中。《UniWorld: Autonomous Driving Pre-training via World Models》一文中,我们从Alberto Elfes在1989年的开创性工作中获得了灵感,他引入了占据栅格作为机器人世界模型的概念。我们为机器人提供了时空世界模型,称为UniWorld,以感知其周围环境并且预测其他参与者的未来行为。UniWorld最初预测4D几何占据作为基础阶段的世界模型,随后在下游任务上微调。UniWorld可以估计有关世界状态的缺失信息,并且预测世界可能的未来状态。此外,UniWorld的预训练过程是无标注的,可以利用大量的图像-激光雷达对来构建基础模型。代码可以在Github上找到。
1. 主要贡献
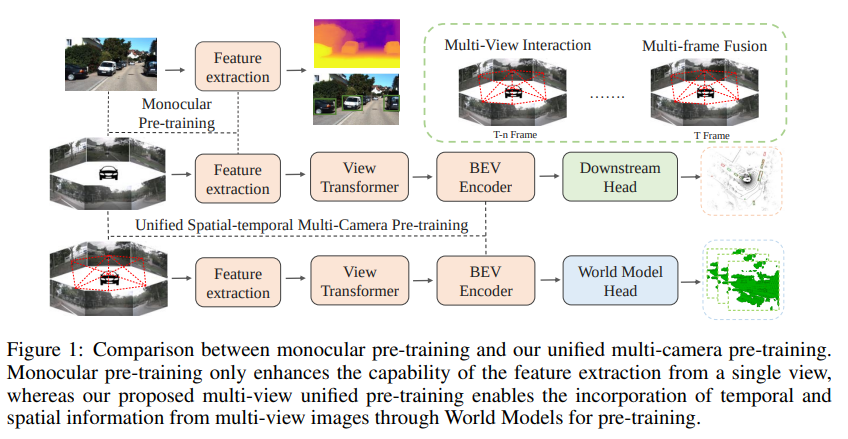
图1:单目预训练与我们的统一多摄像头预训练的比较。单目预训练仅增强了从单个视角提取特征的能力,而我们提出的多视角统一预训练通过世界模型的预训练,实现了从多视角图像中融合时空信息的能力。
本文的贡献总结如下:
-
本文提出了学习用于统一自动驾驶预训练的时空世界模型,其中包括初始重建4D周围场景作为基础阶段,然后在下游任务上微调;
-
UniWorld具有估计有关3D世界状态的缺失信息以及预测4D世界可能的未来状态的能力;
-
UniWorld的预训练过程是无标注的,能够利用自动驾驶汽车采集的大量图像-激光雷达对来构建基础模型;
-
通过采用本文统一的预训练方法,可以将昂贵的标注成本降低25%,为现实世界自动驾驶的实现提供了重要的实用价值。
2. 主要方法
本节详细描述了UniWorld所采用的网络架构,如图2所示。我们首先在第3节中研究基于视觉的鸟瞰(BEV)感知方法。接着,在第3.2节中,我们介绍了用于预训练的提出的4D世界模型。此外,在第4节中,我们将该模型与现有的单目预训练、知识蒸馏和3D静态预训练方法进行了比较。
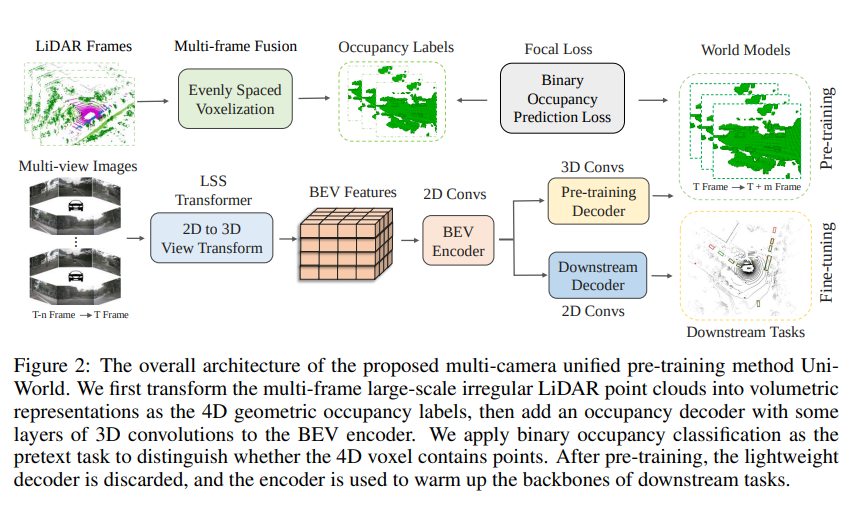
图2:所提出的多摄像头统一预训练方法UniWorld的整体架构。我们首先将多帧大规模不规则LiDAR点云转换为体积表示,作为4D几何占据标签,然后在BEV编码器中添加一些3D卷积层的占据解码器。我们将二进制占据分类作为预训练的预文本任务,以区分4D体素是否包含点云。在预训练之后,轻量级解码器被丢弃,编码器用于预热下游任务的主干网络。
3. BEV感知综述
正如相关工作中所讨论的,将2D图像转换为3D空间有两种主要的基于学习的方法:基于LSS的[16]和基于Transformer的[7]视图转换。然而,我们的方法并不限于任何特定的视图转换技术。在接下来的章节中,我们将提供基于鸟瞰图的多摄像头感知算法的工作流程的全面概述。
多个摄像头的输入图像,表示为I = {I_i,i = 1, 2, …, N_{view}},首先通过图像主干网络(如ResNet-101 [54])进行处理,生成每个摄像头视图的特征图F_{2d} = {F^i_{2d}}^{N_{view}}_{i=1}。然后,这些特征通过2D到3D视图转换操作,投影到统一的鸟瞰图表示F_{bev} ∈ \mathbb{R}^{C×H×W}上。通过结合特定的头部,可以在鸟瞰图上执行各种自动驾驶感知任务,包括3D物体检测、地图分割、物体跟踪等[33]。
当前的鸟瞰感知算法[8, 7, 9]通常依赖于特征提取模型(例如,ImageNet [13])或深度估计模型(例如,V2-99 [14])在单目图像上进行训练。然而,这些方法没有考虑从不同相机视角和帧捕获的图像之间的相互作用和相关性,导致缺乏一个利用不同相机视角之间的空间和时间关系的统一预训练模型。为了充分利用这些关系,我们提出了一个多相机统一预训练模型。
像BEVDepth [10]和DD3D [14]这样的方法展示了深度估计对基于视觉的感知算法的重要性。然而,深度估计只能估计物体表面的位置,忽略了物体的遮挡。对于多相机系统,精确的占据预测有助于感知的准确性。为了使模型同时具备占据场景补全和未来预测的能力,我们提出通过4D几何占据预测来构建多相机统一预训练的世界模型。
3.1 4D几何占据解码器(重点内容)
为了使用BEV特征F_{bev}预测4D几何占据情况,我们首先将BEV特征转换为F’_{bev} ∈ \mathbb{R}^{C^′×D×H×W},其中D表示高度通道的数量,而C = C^′× D。随后,我们使用专门设计的3D解码器生成4D几何占据情况。该解码器由轻量级的3D卷积层组成,最后一层提供每个体素包含点的概率。解码器的输出表示为P = {P^i ∈ \mathbb{R}^{D×H×W×1}, i = 1, 2, …, m}。在预训练阶段,解码器的主要目标是重构占据的体素。
3.2 预训练目标
考虑到单帧激光雷达点云的稀疏性以及由于动态物体导致的大量帧融合可能出现的不准确性,我们采用了选择性关键帧融合激光雷达点云的策略来生成占据标签。遵循3D感知模型的标准做法[55, 56, 57, 58],将激光雷达点云划分为均匀间隔的体素。对于激光雷达点云在Z × Y × X维度上的尺寸(表示为D × H × W),体素的尺寸分别确定为v_Z × v_H × v_W。基于体素的占据情况,生成4D的真实值T = {T_i ∈ {0, 1}^{D×H×W×1}, i = 1, 2, …, m},表示每个体素是否包含点云。值为1表示占据的体素,而值为0表示空闲的体素。
我们提出了二进制几何占据分类任务作为多摄像头感知模型预训练过程的一部分。该任务的目标是训练网络根据多视角图像准确预测4D场景中的几何占据分布。然而,由于空体素的数量相当大,预测占据网格存在着不平衡的二进制分类挑战。为了解决这个问题,我们采用了二进制占据分类的焦点损失函数,利用预测的4D占据值P和4D的真实占据体素T:
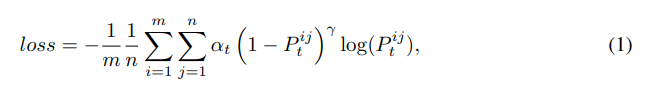
其中,P^{ij}是第i个占据中第j个体素的预测概率。n = D × H × W是体素的总数,batch是批次大小。正/负样本的加权因子α设为2,易/难样本的加权因子γ设为0.25。α_t = α,P^{ij}_t = P^{ij}表示类别1的情况。α_t = 1 - α,P^{ij}_t = 1 - P^{ij}表示类别0的情况。
目前,算法中使用的4D几何占据标签是从多帧LiDAR点云中获取的。将来,也可以利用从3D场景重建中生成的点云,例如使用NeRF [59, 60, 61, 62]或MVS [63, 64, 65, 66]等技术。
3.3 周围语义占据预测的预训练
最近,一些算法,如TPVFormer [67],OpenOccupancy [68]和Occ3D [69],已经将多摄像头BEV感知的范围扩展到周围语义场景完成的任务上[70, 71, 72, 73, 74]。然而,直接预测多视图图像的三维语义需要大量的三维语义注释进行训练,这可能既昂贵又耗时。为了克服这个挑战,我们提出将我们的多摄像头统一预训练算法扩展到包括周围语义场景完成任务。这涉及首先进行几何占据预测,然后在语义场景完成任务上对模型进行微调。
4. 与现有方法的比较
4.1 与单目预训练的比较
目前,多摄像头感知算法主要利用在ImageNet [13]上进行的单目图像预训练或深度估计预训练[14]。在图1中,我们突出了我们提出的多摄像头统一预训练模型相对于单目预训练的几个优点:
(1)时空整合:通过利用多个摄像头视角的空间和时间信息,模型对环境的动态特性有更好的理解,从而实现更准确的预测。
(2)统一表示:统一预训练方法使模型能够学习不同摄像头视角之间的共享表示,促进了知识传递的改善,减少了任务特定预训练的必要性。
(3)遮挡区域的感知:单目深度估计只能预测物体的表面位置,而我们提出的多摄像头统一预训练方法能够对遮挡物体进行全面的三维重建。
4.2 与知识蒸馏的比较
最近,知识蒸馏算法取得了一些进展,例如BEVDistill [75]、TiG-BEV [76]和GeoMIM [77],旨在将来自已建立的3D LiDAR模型(如CenterPoint [57])的知识转移到多摄像头目标检测算法中。类似地,我们的方法旨在利用3D点云中丰富的空间信息,并将其转移到多摄像头算法中。我们独特的预训练算法消除了对注释或预训练的LiDAR检测模型的需求,显著减少了对3D注释的要求。



评论(0)
您还未登录,请登录后发表或查看评论