

前言
本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。
代码及工具箱
本专栏的代码和工具函数已经上传到GitHub:1571859588/xiaobai_AI: 零基础入门人工智能 (github.com),可以找到对应课程的代码
正文
上节课我们学习了如何使用词嵌入将句子转换为词向量序列。由于语言数据在时间上的关联性,我们需要一种能够处理这种关联性的神经网络。这节课,我们将探讨如何改造神经网络来实现这一点。
假设每个词都已经被转换为一个300维的词向量,我们现在要改造神经网络来更好地处理这些序列数据。上节课我们使用了全连接神经网络,将所有词向量平铺开,然后作为输入。但这种方法无法捕捉到语言在时间上的关联性。
为了处理这种时间上的关联性,我们通常使用循环神经网络(RNN)或者其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU)。这些网络结构能够记住先前的输入,并在处理当前输入时考虑到这些信息,从而更好地理解和预测序列数据。
RNN通过引入隐藏状态来存储之前的信息,并在处理下一个词向量时将其考虑进去。LSTM和GRU是RNN的两种改进形式,它们能够更好地捕捉长序列数据中的长期依赖关系。
通过使用这些网络结构,我们可以更好地理解和处理语言数据,从而提高情感分类等任务的性能。接下来,我们将探讨如何在实际应用中使用这些网络结构。
RNN循环神经网络的结构
首先为了让改造过程的讲解简明一些,我们把网络结构图的画法做个简化,忽略具体的神经元之间的连线,用箭头表示数据的输入和输出,然后我们把这个句子中每个词向量分别命名为x1、x2、x3和x4。第一步先把这个句子的第一个词向量x1作为这个隐藏层的输入,直到输出a1,这时候还没完,还不到最后输出预测值的时候,我们把这个输出值a1保存起来。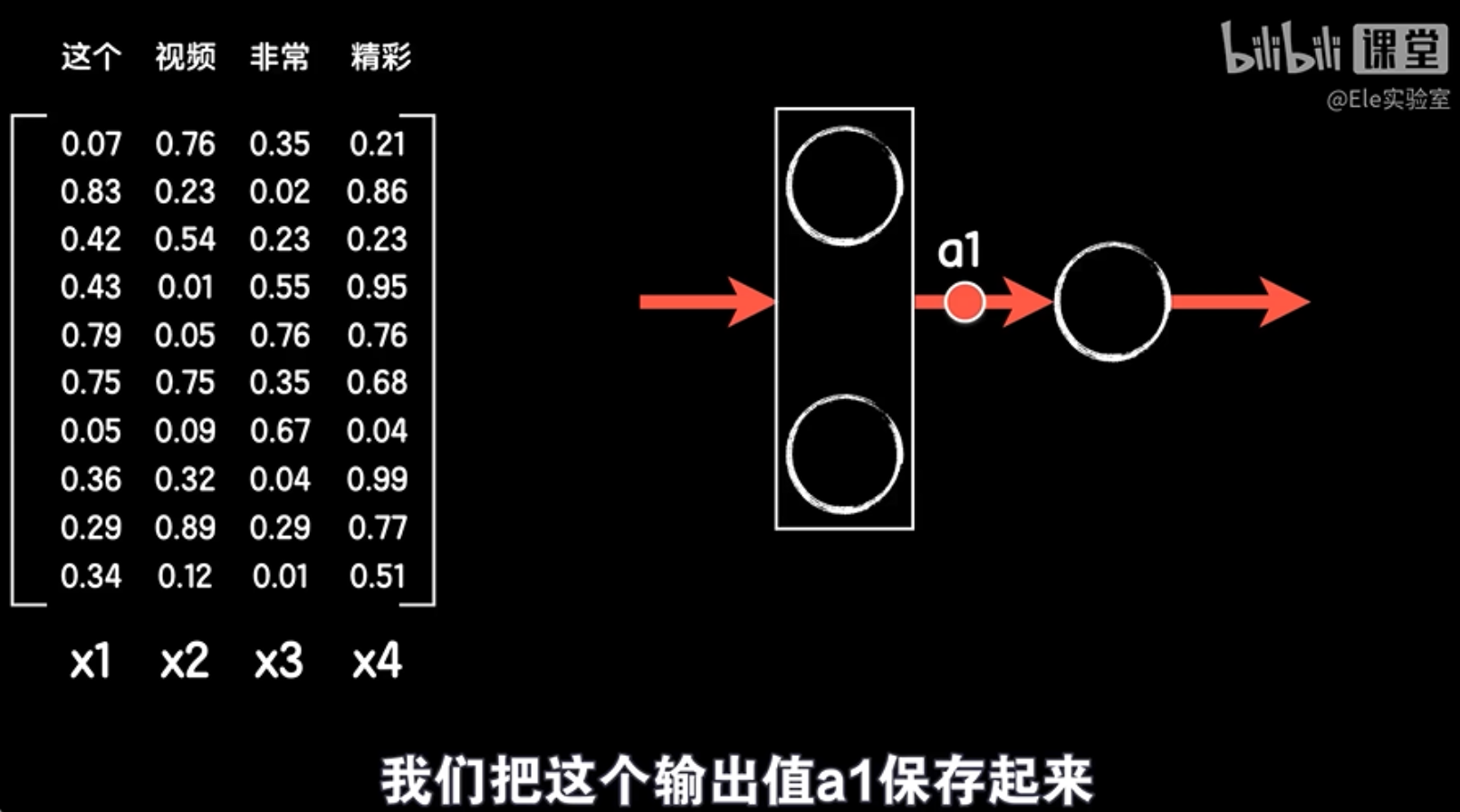
第二步再拉出句子的第二个词,向量x2和这个第一个词向量输出的结果a1一起作为这一步的输入,得到本次的输出a2,继续保存这个a2。
第三步再拿出句子的第三个词向量x3,同样和上一次的输出a2一起作为本次的输入得到输出a3。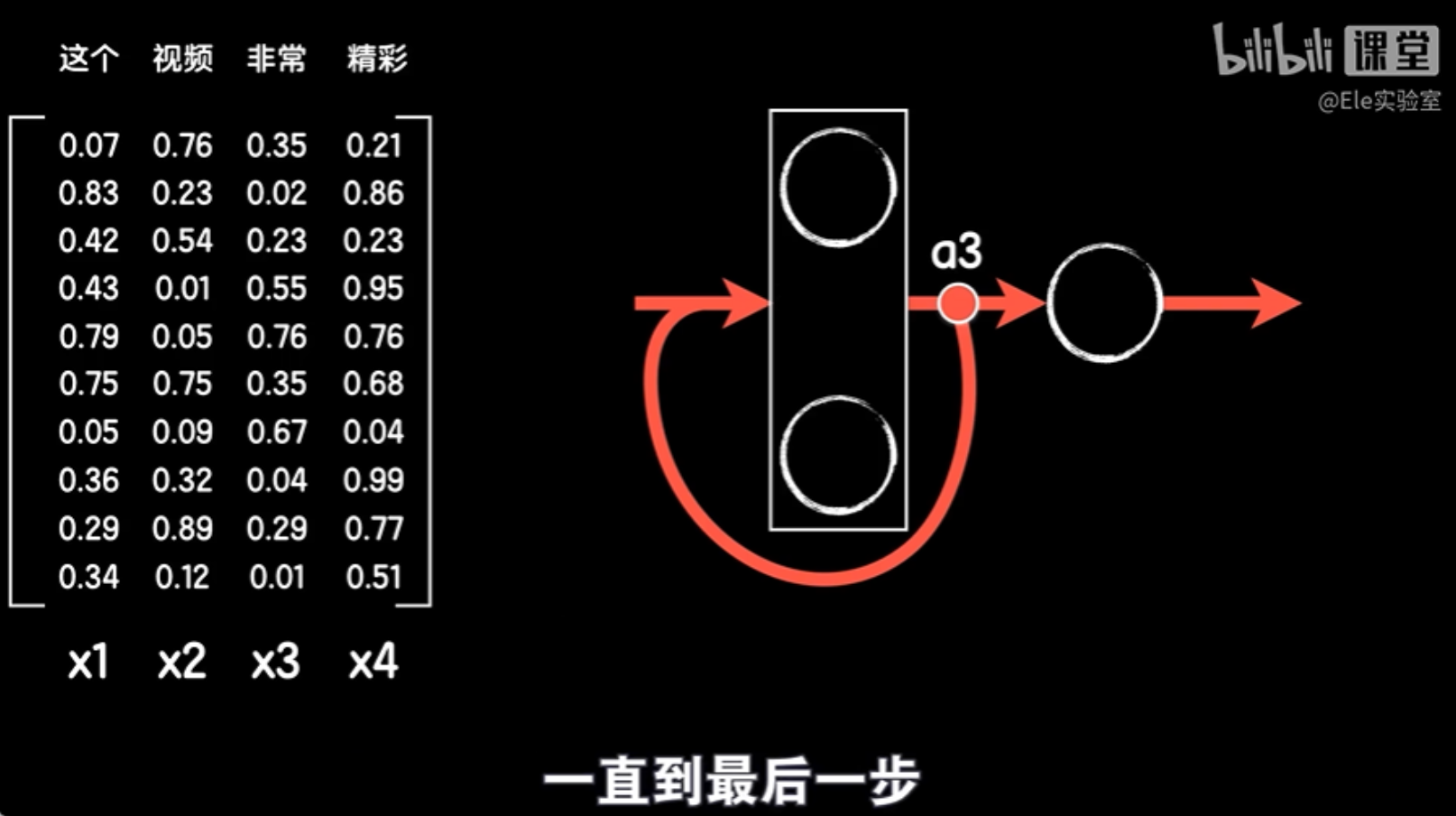
一直到最后一步:句子的最后一个词向量x4和a3一起输入得到输出a4,此时我们才让a4经过输出层得到最后的预测输出。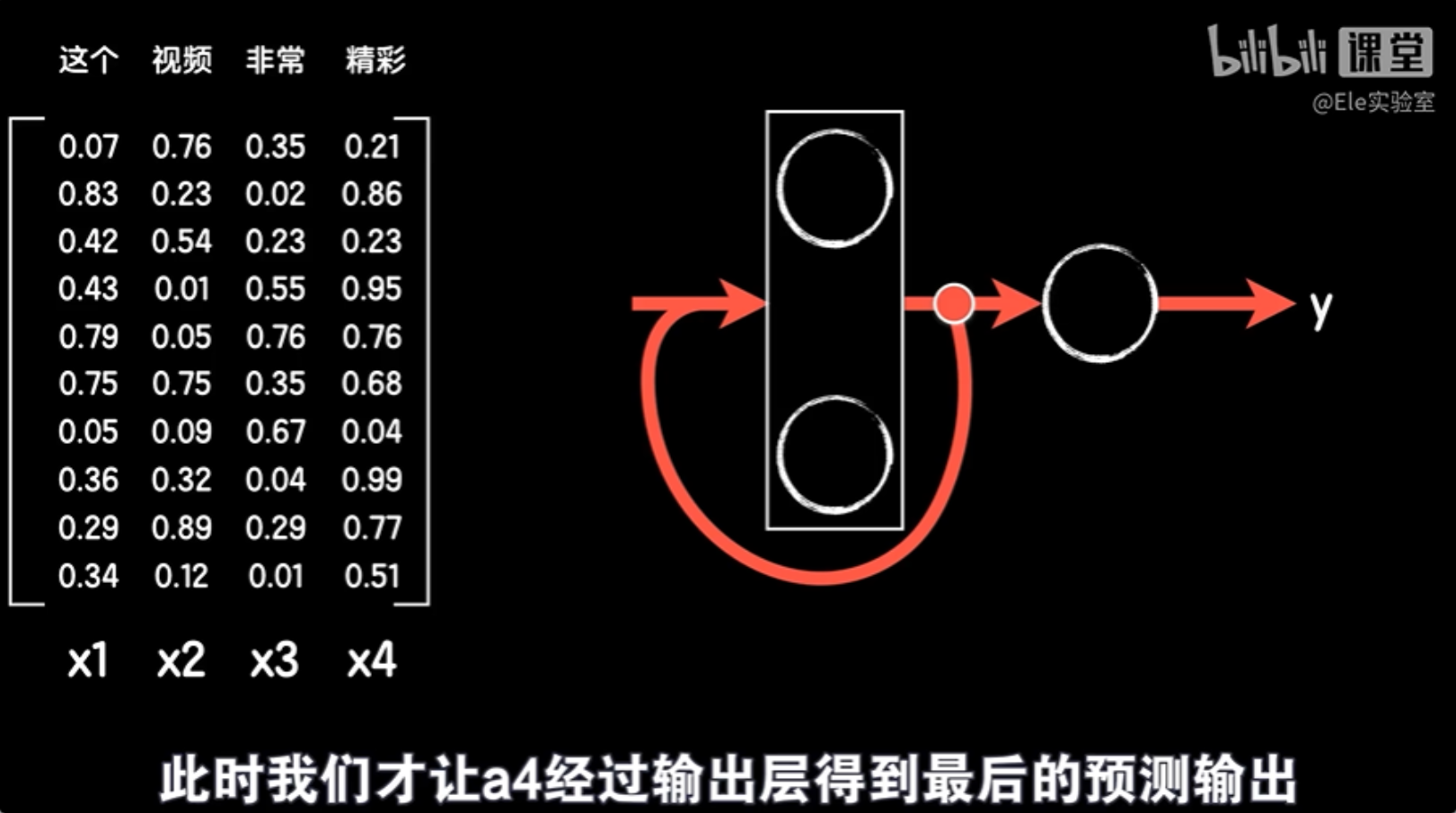
这样一个句子,每个词对最后预测输出的影响就在每一次的保存并和下一步数据的共同作用中持续到了最后,这样序列中的数据就产生了循环的特点,所以我们把这样改造的神经网络称之为循环神经网络RNN。很简单吧,当然其中有一些细节可能比较繁琐一点,首先循环神经网络中的激活函数多采用双曲正切函数tanh,而不是relu。当然也可以使用relu,像keras这种编程框架中的循环神经网络默认使用的激活函数就是tanh。
然后循环神经网络中的第一步不像后面那样有上一个输出反送回来的数据一起作为输入,但为了保证每一步操作的统一性,我们一般也会手动添加一个共同的输入(a0),比如一个全0的向量。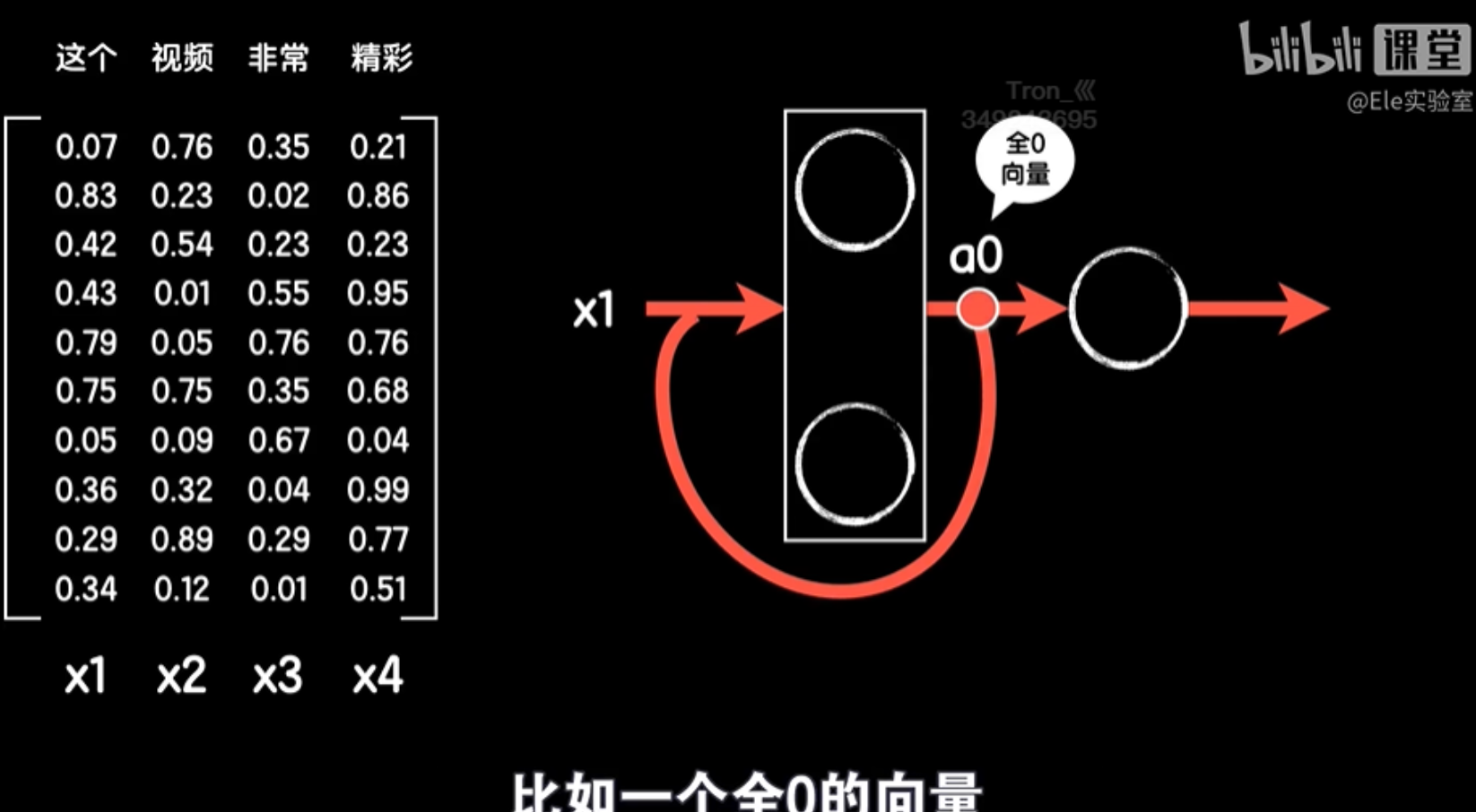
最后是这个循环神经网络的结构图,我们这么画是为了让大家看到如何从一个普通的全连接层改造成为RNN结构,但是大家一般喜欢把输入x画在下面,最后的输出画在上面,中间的返送箭头画在侧边,这么做图的好处就是能够很方便的把网络在时间上逐步的行为在空间上展开,而展开后就能很清楚的展示出每个时间步骤上神经网络的工作流程。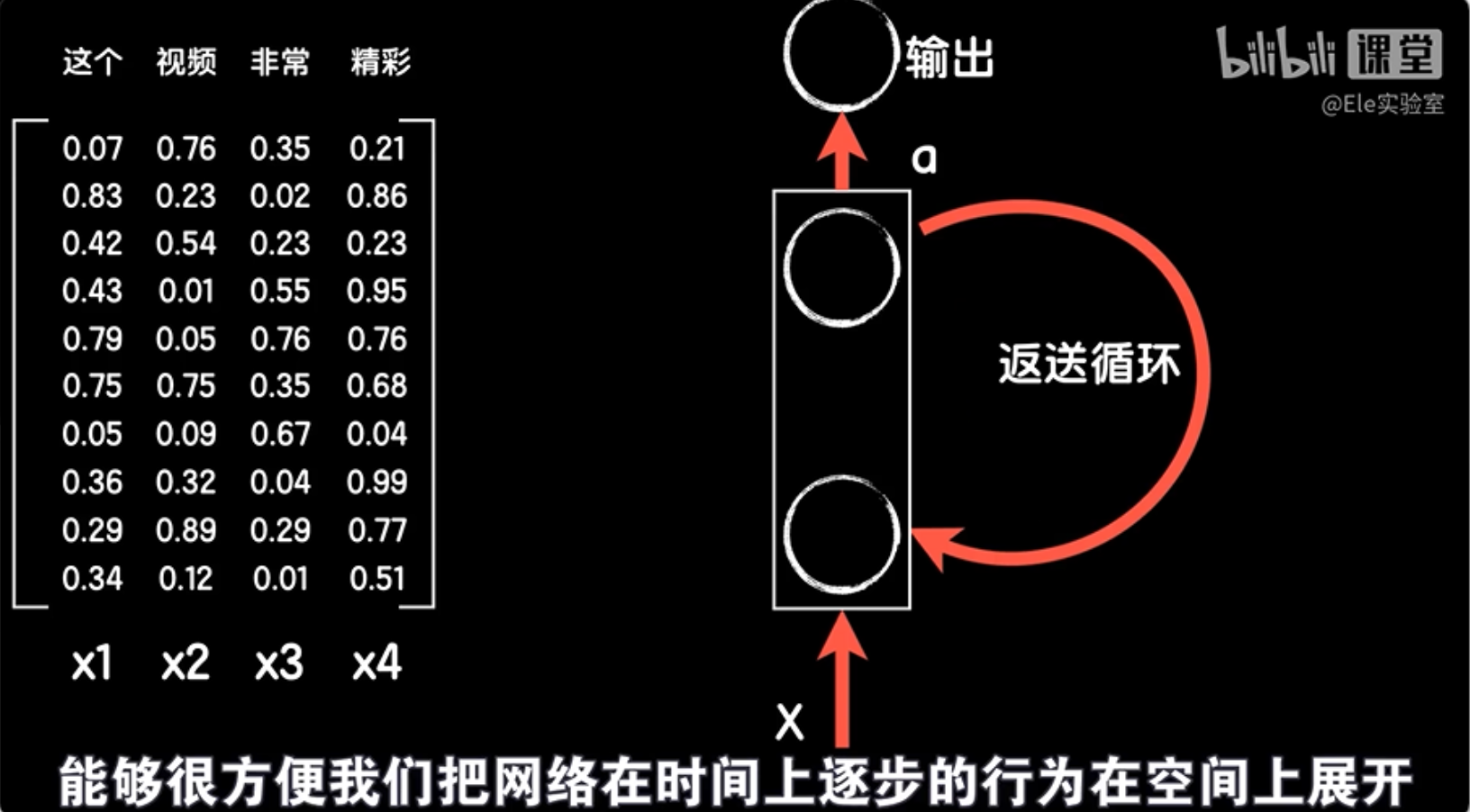
好的,我们来看一下如何使用循环神经网络(RNN)来处理序列数据。假设我们有一个包含4个词的句子,每个词都已经转换为一个词向量。在RNN中,我们首先将第一个词向量x1和初始隐藏状态a0一起输入到网络中,得到第一个输出a1。在情感分类任务中,我们不需要每个时间点的预测输出,所以我们只关注激活值a1。
接下来,我们将第二个词向量x2和前一个时间点的激活值a1一起输入到网络中,得到第二个输出a2。同样地,我们只保留激活值a2,而不关心预测输出。
这个过程会在句子的每个词上重复进行,直到处理完所有的词。在RNN中,每一步的输出都会作为下一步的输入的一部分,这样网络就能够考虑到前面的词对当前词的影响。
请注意,虽然我们在图上看到了两个时间点的样子,但这并不意味着有两个独立的网络。实际上,这只是一个网络在时间上的行为,而不是空间上的行为。这个网络结构在时间上是共享的,也就是说,我们在每个时间点使用的都是同一个网络参数。
通过这种方式,RNN能够捕捉到语言数据中的时间关联性,这对于理解和预测序列数据非常重要。在情感分类任务中,这种结构可以帮助模型更好地理解评论的情感倾向。接下来,我们将探讨如何在实际应用中使用RNN来处理情感分类任务。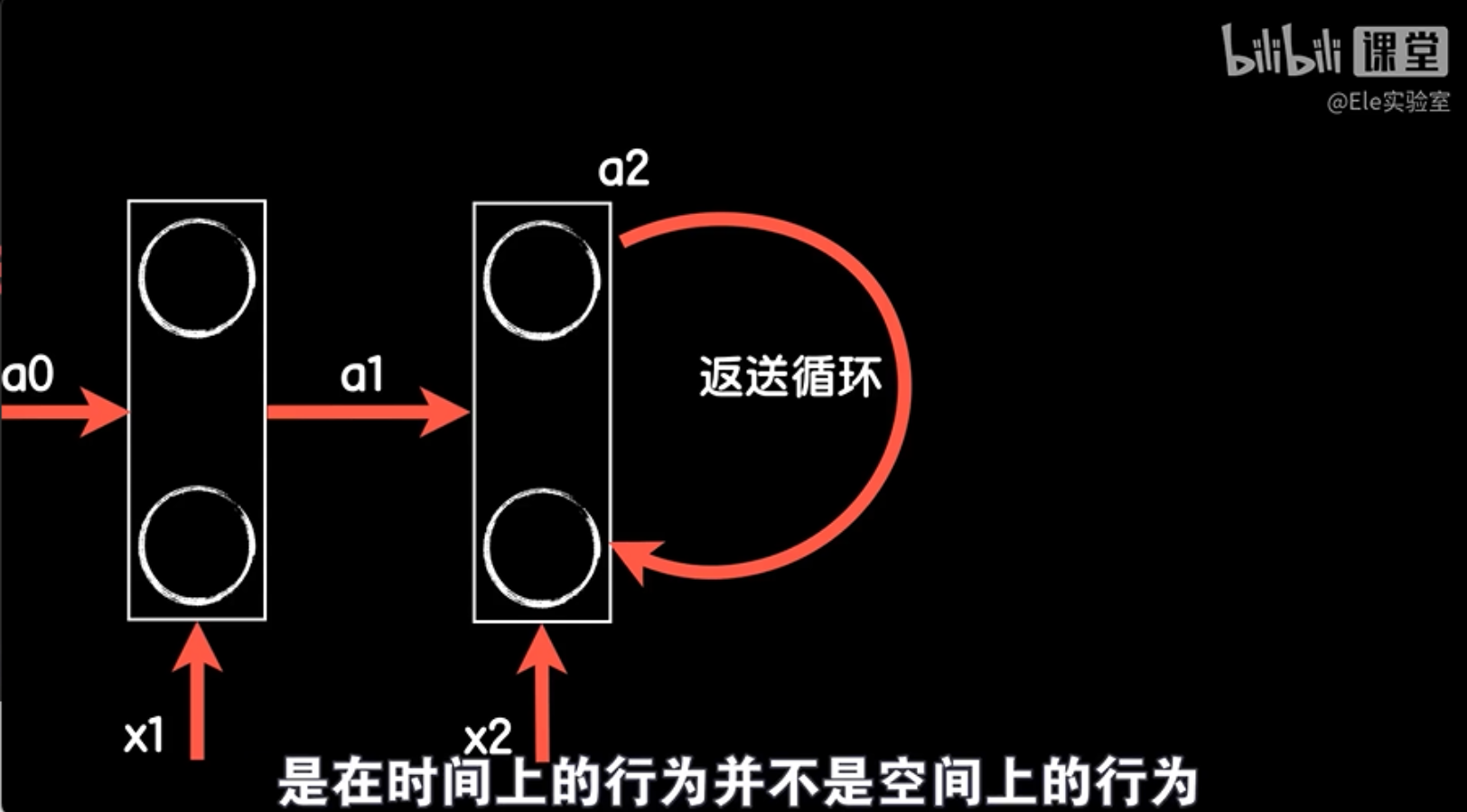
同样第三个词向量x3和a2一起输入得到第三个输出a3,我们再在右边画一个x4和a3得到a4再画一个,到此这句话就结束了,我们再让a4在通过输出层经过sigmoid或者softmax得到最后的分类预测输出,这样我们就把在时间上的每一步的行为在空间上展开了,如此我们就能清晰的看出来循环神经网络的前向传播的过程。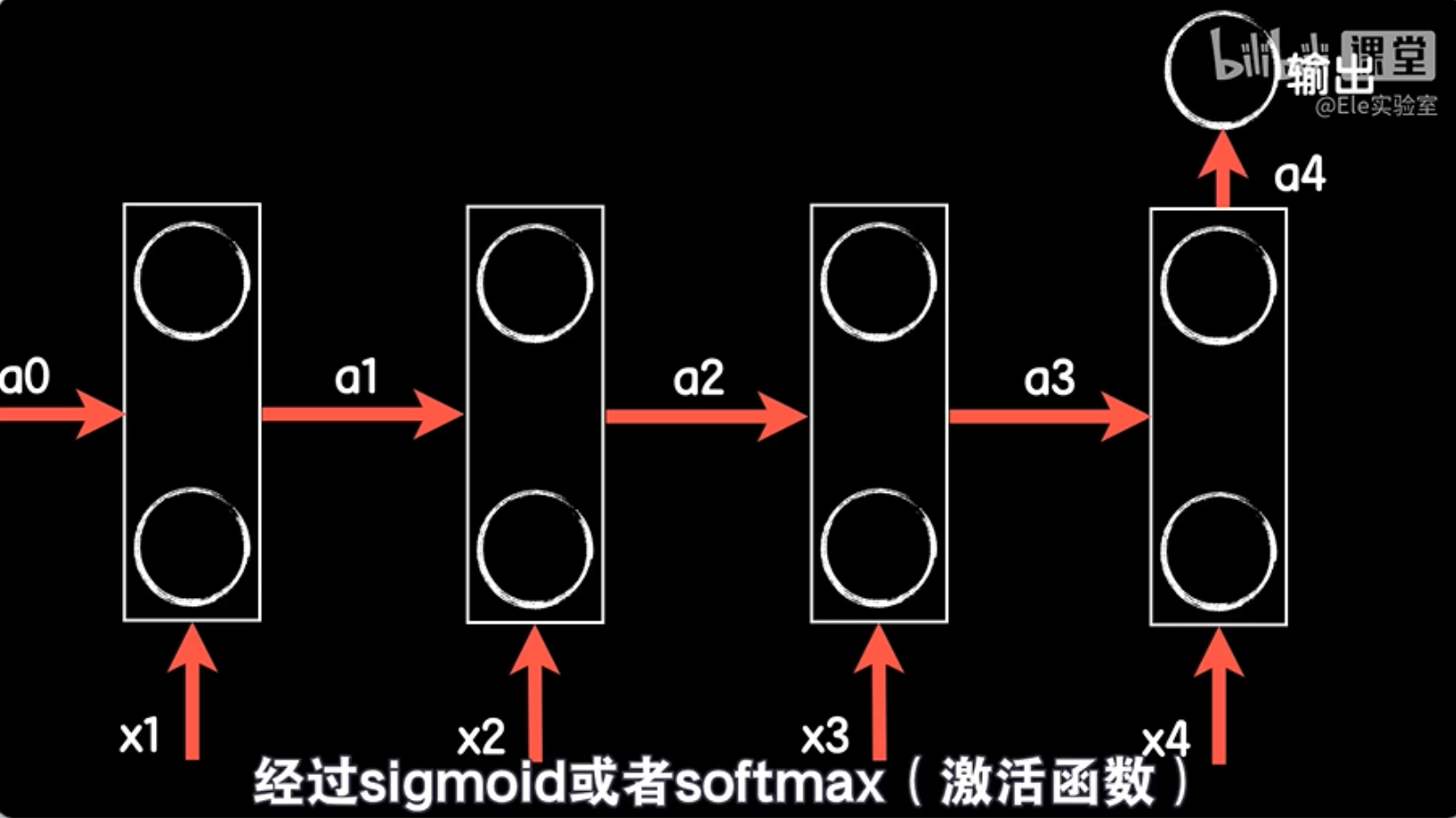
而反向传播则是从最后的输出层开始,把误差从相反的方向依次从后往前传播,当然这个反向传播的过程也是按照时间进行的,换句话说我们让时光逐步倒流进行反向传播,详细的过程我们就不展开了,现在的深度学习变成框架会帮我们处理得很好。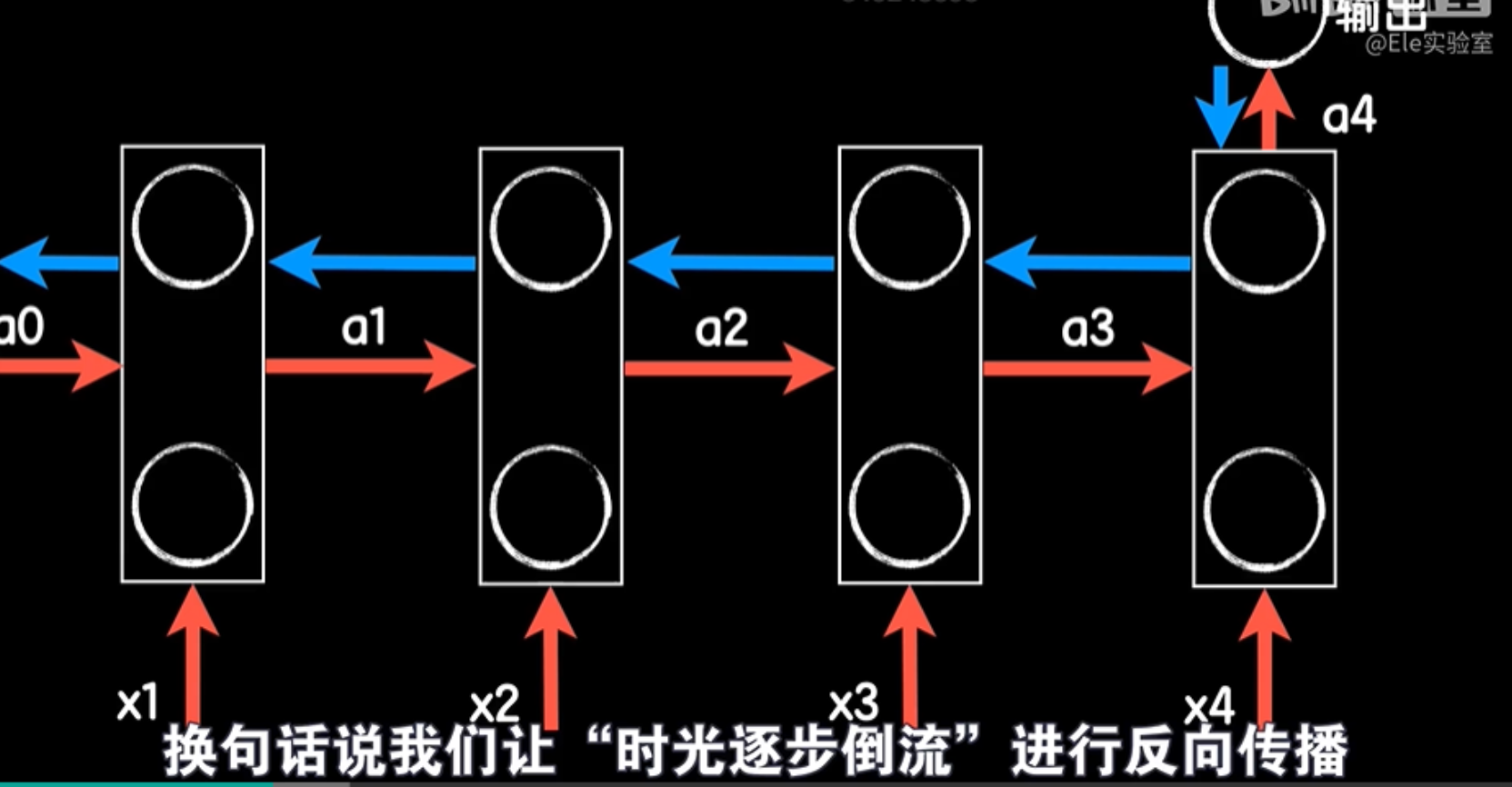
循环神经网络之所以能够处理时间上彼此依赖的序列问题,是因为它们能够记住之前的信息。就像我们人类一样,当我们听到一个句子时,我们会记住前面的内容,并基于这些信息来理解后面的内容。
比如,当我们听到“这个视频好看”时,我们知道这是一个正面的评论。但如果我们听到“这个视频非常不好看”,情况就不同了。这里的“非常”是一个副词,它增强了“不好看”的程度,使得整个句子的情感倾向变为负面。
在循环神经网络中,每个词的输入不仅取决于当前的词,还取决于之前所有词的信息。这些信息被保存在网络的隐藏状态中,就像我们的大脑记住前面的内容一样。这样,网络就能理解句子的整体含义,而不仅仅是单个词的含义。
通过这种方式,循环神经网络能够处理和预测那些依赖于前文内容的序列数据,比如自然语言中的句子。这种处理能力使得循环神经网络能够用于情感分析、机器翻译、语音识别等任务,其中数据序列在时间上是连续的,并且依赖于前面的内容。通过这种方式,循环神经网络能够处理和理解复杂的时间序列数据,并做出准确的预测和分析。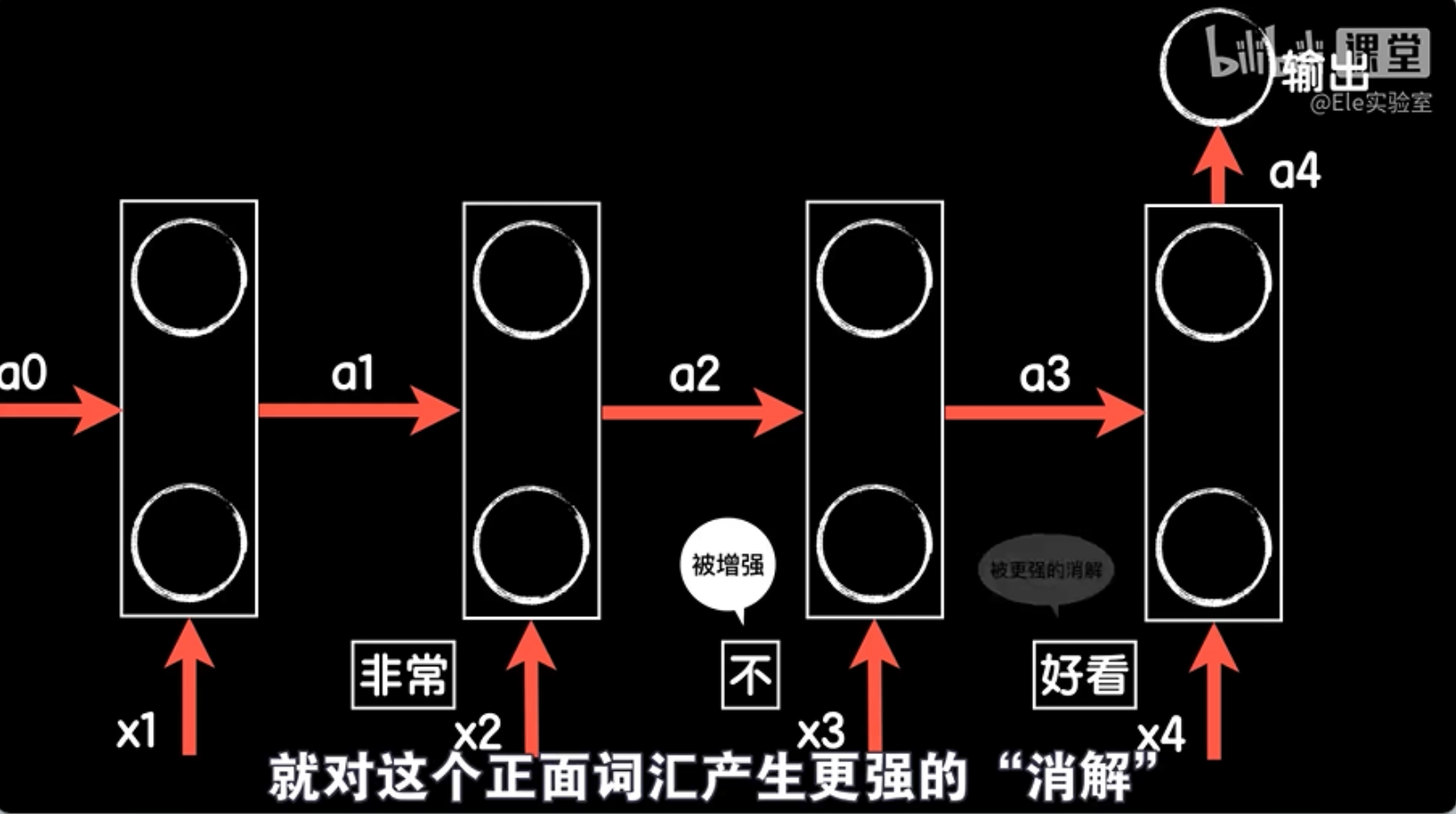
当然,我们也可以使用多个RNN层来构建一个多层的循环神经网络。这样,每一层RNN都会记住之前的信息,并在处理当前输入时考虑这些信息。
例如,我们可以构建一个两层的RNN结构。第一层RNN的输出会作为第二层RNN的输入,同时第一层RNN的每一步的激活值也会作为第二层RNN对应时间点的输入。
让我们来过一遍这个过程:
- 第一步,我们从句子中取出第一个词的词向量x1,与第一层RNN的初始隐藏状态$aL1_0$合并输入第一层RNN,得到第一层的输出$aL1_1$。
- aL1_1作为第二层的输入,与第二层的初始隐藏状态$aL2_0$合并输入第二层RNN,得到第二层的输出$aL2_1$。
- 第二步,我们从句子中取出第二个词的词向量x2,与第一层上一步保存的激活值$aL1_1$合并输入第一层RNN,得到第一层的输出$aL1_2$。
- $aL1_2$作为第二层的输入,与第二层上一步保存的激活值$aL2_1$合并输入第二层RNN,得到第二层的输出$aL2_2$。
- 以此类推,直到处理完句子的所有词。
最后,我们使用第二层RNN最后一步的输出,通过输出层得到最终的分类预测输出。
这个过程需要强调的是,第一层的输入并不是一次性送入第二层的,而是在时间上一步一步送入的。每一层RNN的每一步输出都会作为下一层对应时间点的输入。这种结构能够更好地捕捉句子中词与词之间的依赖关系,从而提高情感分析等任务的性能。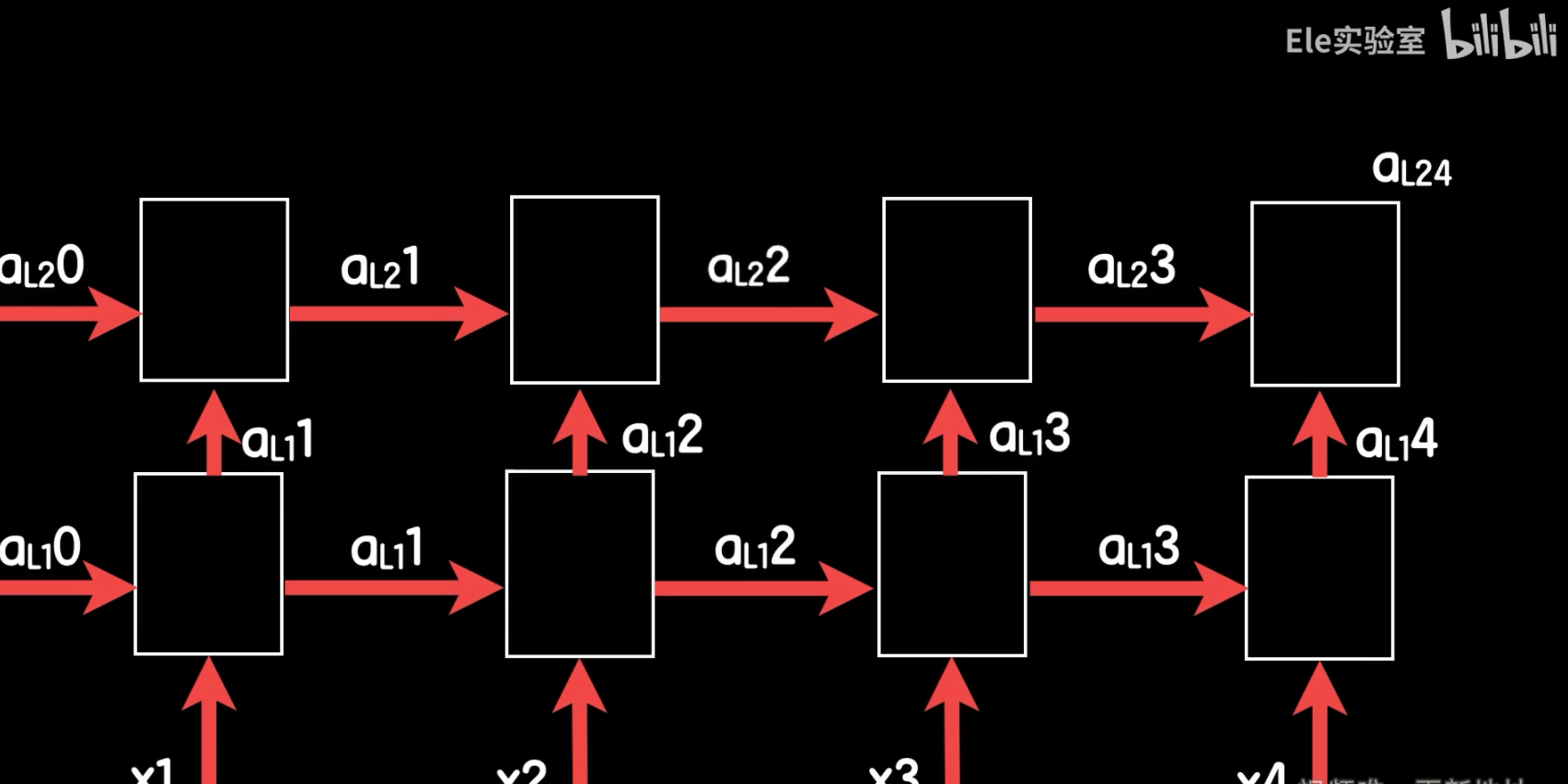
循环神经网络虽然也可以堆叠成多层的,但是人们轻易不会构造的太深。一般来说2~3层就可以了,因为循环神经网络会在时间上展开,所以网络结构将会变得很大,训练起来相对于其他的结构更加的困难。
长依赖的问题:引入LSTM
标准的循环神经网络(RNN)在处理长依赖问题时效果可能不太好。这是因为长依赖问题涉及到句子中较远的词之间的关联,而标准的RNN在处理这种长距离依赖时可能会出现问题。
举个例子,如果我们想预测句子“上海电视台记者在北京街头采访了一名来自四川的年轻人,他性格开朗热爱生活,家乡有一种著名的动物叫做____”中最后缺失的那个词是什么,我们需要考虑到前面提到的四川这个地点。然而,四川这个词距离后面提到的动物非常远,这意味着依赖路径非常长。
标准的RNN结构在这种长依赖问题上表现并不好,因为它在处理长距离依赖时可能会出现梯度消失或梯度爆炸的问题,这会影响到模型的训练和性能。
为了解决这个问题,研究人员提出了长短期记忆网络(LSTM)和门控循环单元(GRU)等变体。这些结构设计得更适合处理长距离依赖问题,因为它们能够更好地保持信息的流动和记忆,从而更准确地预测句子中较远词之间的关系。
为了更好地理解LSTM(长短时记忆网络)的工作原理,我们先从标准的RNN(循环神经网络)结构开始。在标准的RNN中,每一步的输入是由上一步的激活输出和当前的词向量合并而成的。这个过程可以想象成是在搭建积木,把两部分数据合并成一个整体。
当我们把at-1(上一步的激活输出)和xt(当前的词向量)合并在一起时,就形成了一个新的张量。这个张量包含了at-1和xt的所有信息,就像是我们把两个积木块放在一起形成一个新的形状。
在标准的RNN中,数据也可以从一个线路复制到另一个线路。这就像是我们把一个积木块从一条线路复制到另一条线路,这样就形成了两个相同的积木块,它们可以沿着不同的线路前进。
通过这种方式,标准的RNN结构能够处理时间序列数据,并在每一步处理中结合前一步的信息。这就是标准的RNN结构的工作原理。接下来,我们将探讨如何通过修改这个结构来创建LSTM,以解决长依赖问题。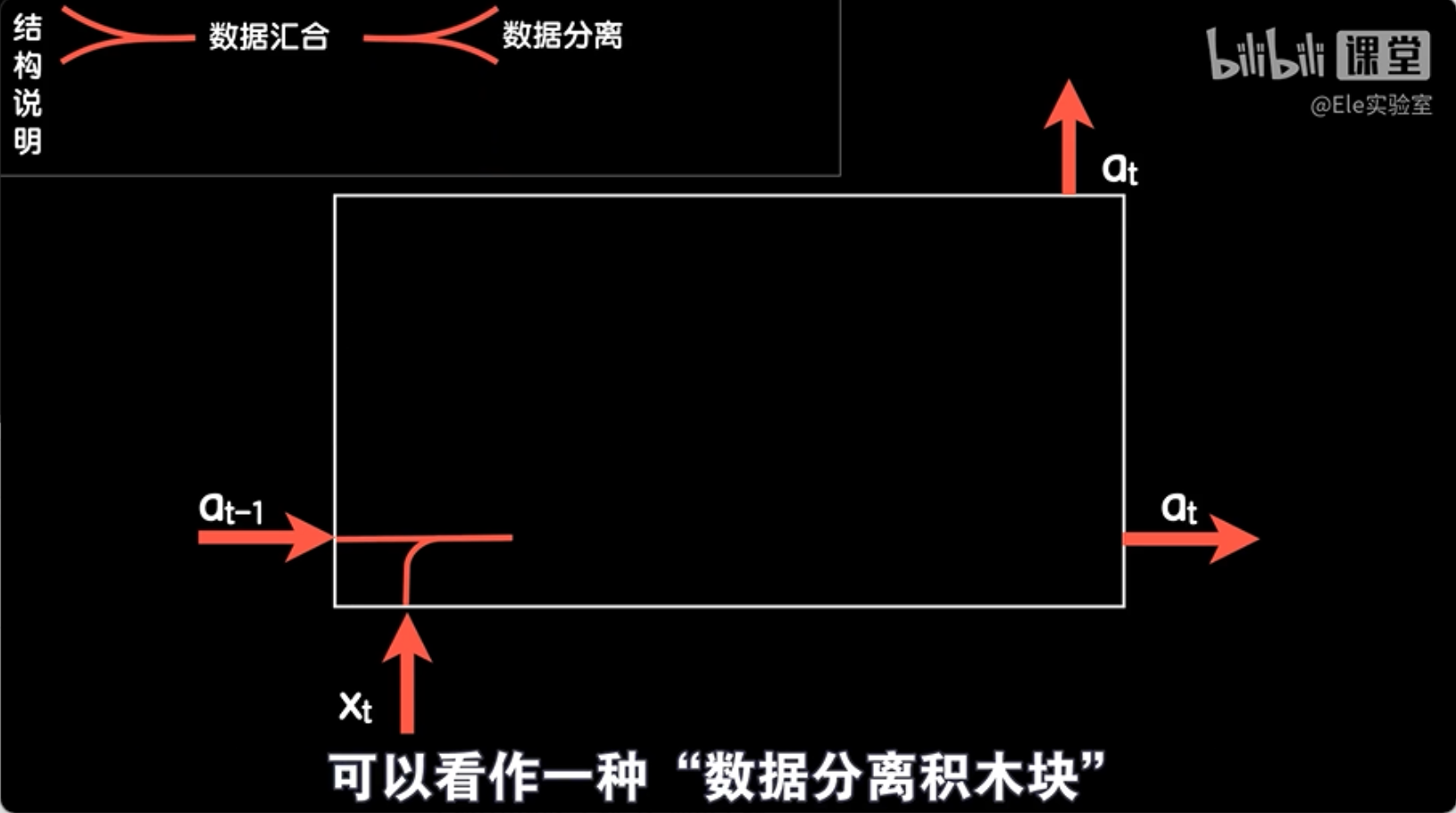
在标准的RNN结构中,合并的数据首先通过一个线性运算,然后通过tanh激活函数来输出本次的激活值at。这个过程可以想象成是搭建积木时,我们先用矩形来表示一个网络层,然后在矩形上标明tanh,说明这个层使用的是tanh激活函数。我们把这个层简称为tanh层,它可以作为一个积木块,代表一个使用tanh激活函数的神经网络层。
同样的道理,如果是一个使用sigmoid激活函数的网络层,我们称之为δ层,也可以看作是一个积木块。我们再从tanh层的输出at引出一条头目。如果这次需要输出一个预测值,就把at送入一个输出层;如果不需要,就不送。
这样,我们从拼积木的角度画出了一个标准RNN结构的细节,包括数据流转和计算的结构图。通过这个图,我们可以清晰地看到RNN中数据的流动和计算过程。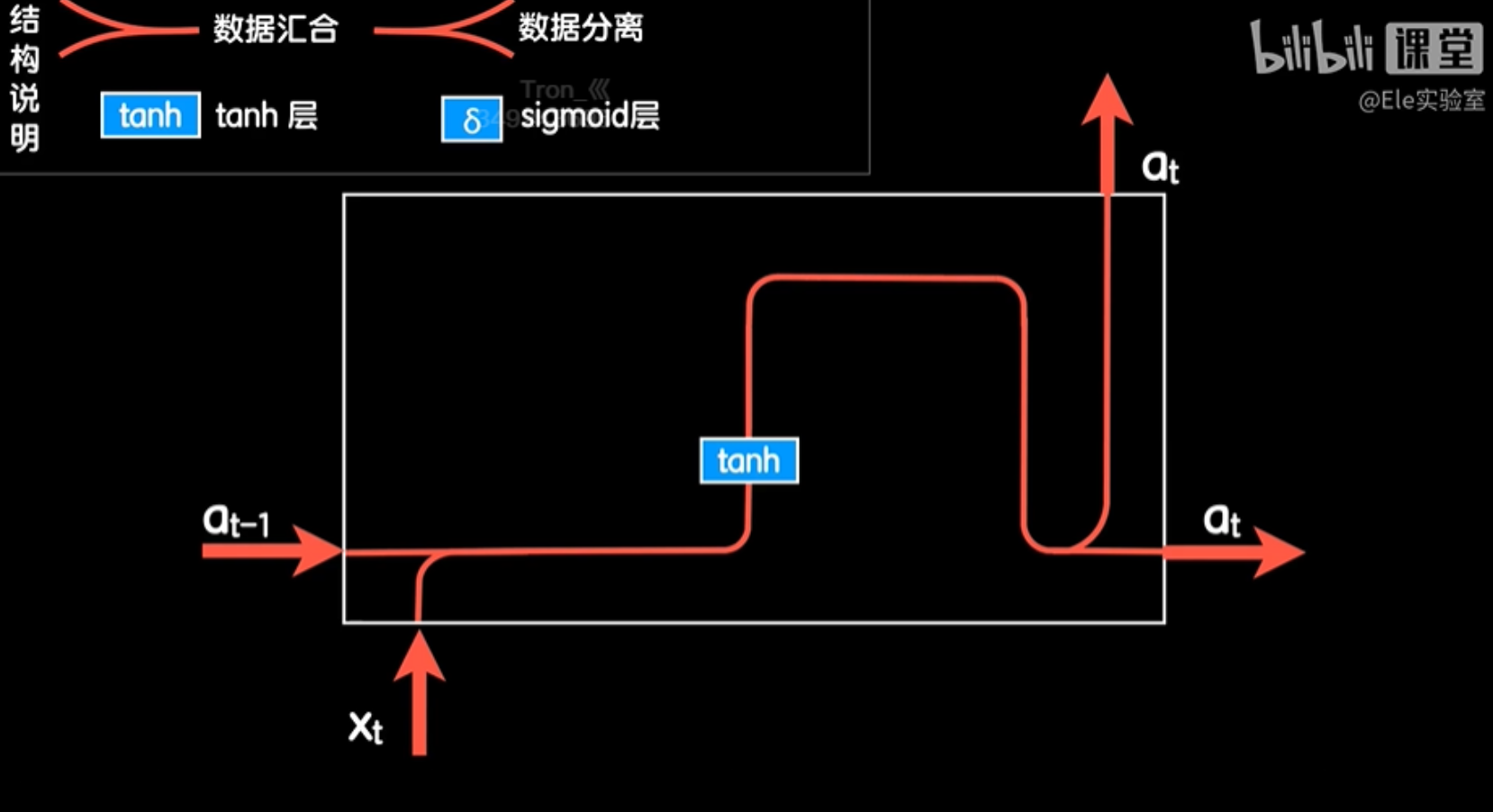
在改造RNN结构以创建LSTM(长短时记忆网络)的过程中,我们会使用一些新的积木块。首先,我们有加法积木块,用一个加号表示,它将两个数据a和b相加,输出a+b。还有乘法积木块,用一个乘号表示,它将两个数据a和b相乘,输出a*b。还有一种椭圆的函数及模块,用一个椭圆并在上面标注相应的函数名,比如tanh,表示数据通过这个模块后会被tanh函数运算,输出tanh(a)。
和tanh层不同,tanh层在tanh激活函数之前还包括了一个线性运算。这些积木块的组合将帮助我们构建LSTM结构,这是对标准RNN结构的一个重大改进,旨在更好地处理长依赖问题。
LSTM结构相对于标准的RNN结构,在设计上做了一些关键的改变,这些改变使得LSTM能够更好地捕捉长距离依赖关系,从而在处理自然语言、语音识别等任务时表现更佳。这些改变包括引入了特殊的门控机制和细胞状态,这些机制允许网络在需要时保持或忘记某些信息,从而更好地适应长序列数据。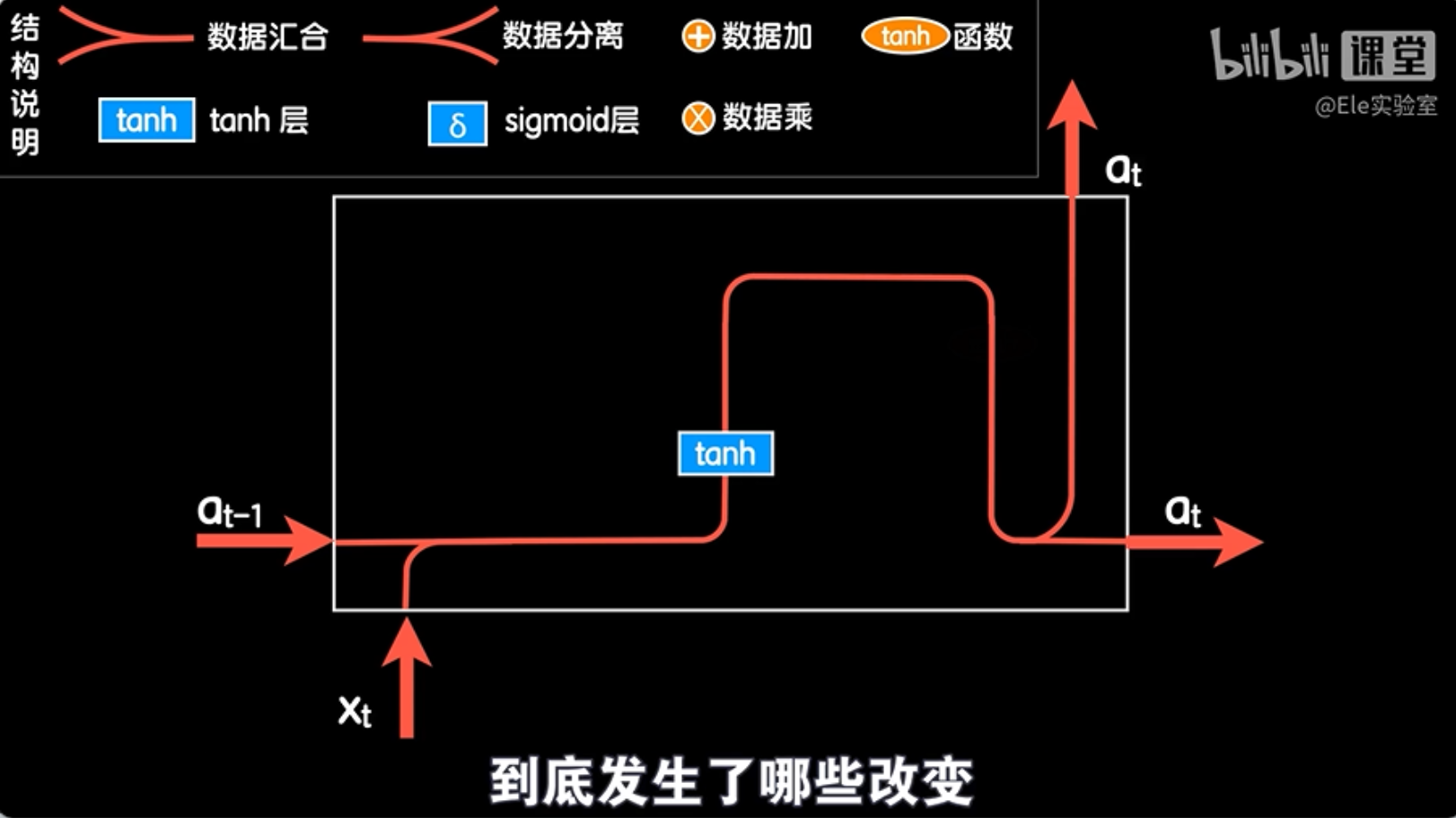
首先LSTM结构中的输出再次经过一个tanh函数,而原先的输出则变成了一个叫做细胞状态Ct的东西,这个细胞状态就是LSTM结构能够应对长依赖问题的关键,因为它能够让网络具有记忆和遗忘的效果。这样既然输出变成了细胞状态和输出两个部分,那么作为一个循环中的某一步,这个结构的输入必然相应的也就变成了上一步的细胞状态和上一步的输出。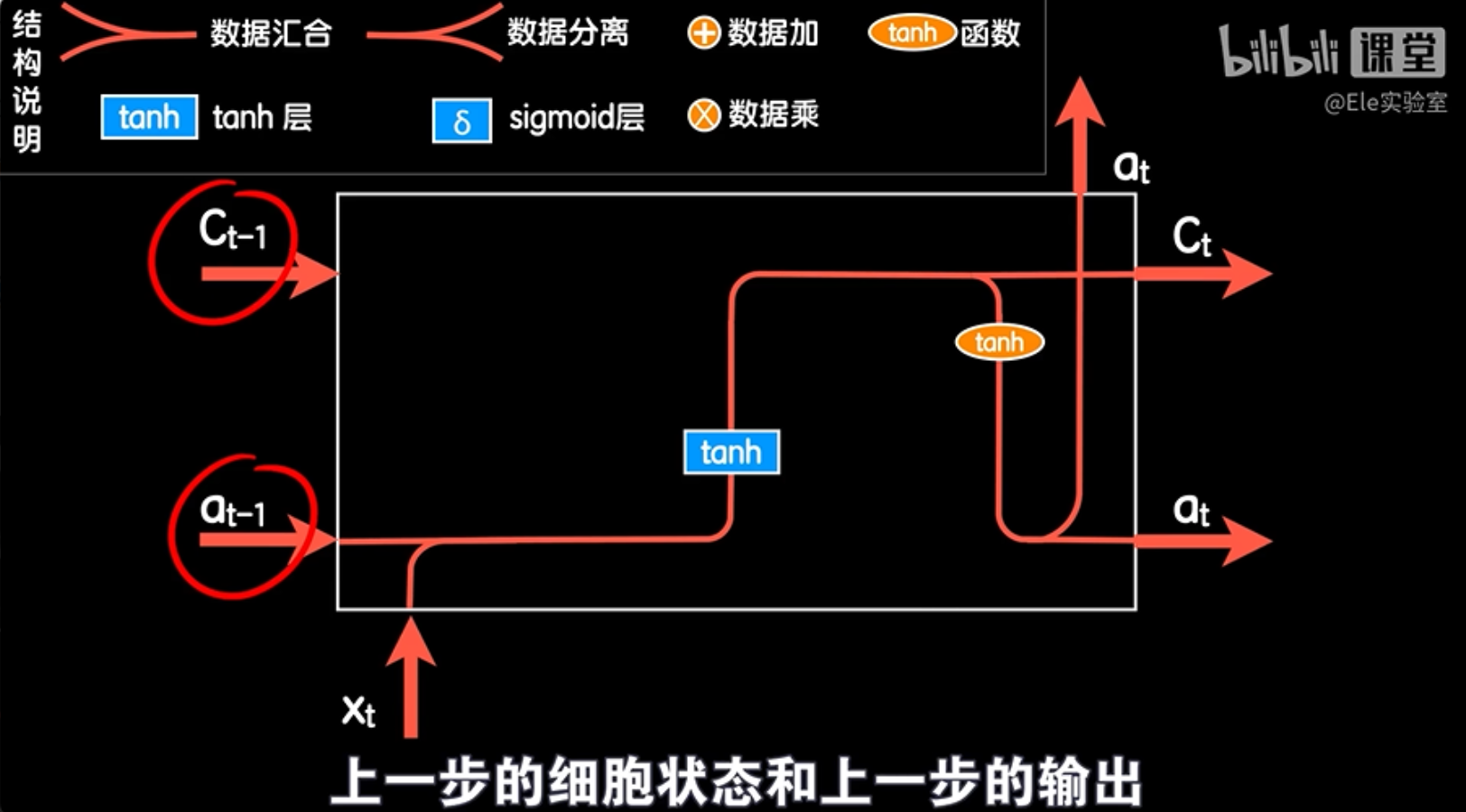
我们继续改造。本次输入数据也不仅仅依靠上一次的输出和本次的词向量,而把上一个细胞状态也一起作为输入,我们用加法积木把这两个部分加在一起,这就是LSTM主要的数据流转和运算的过程。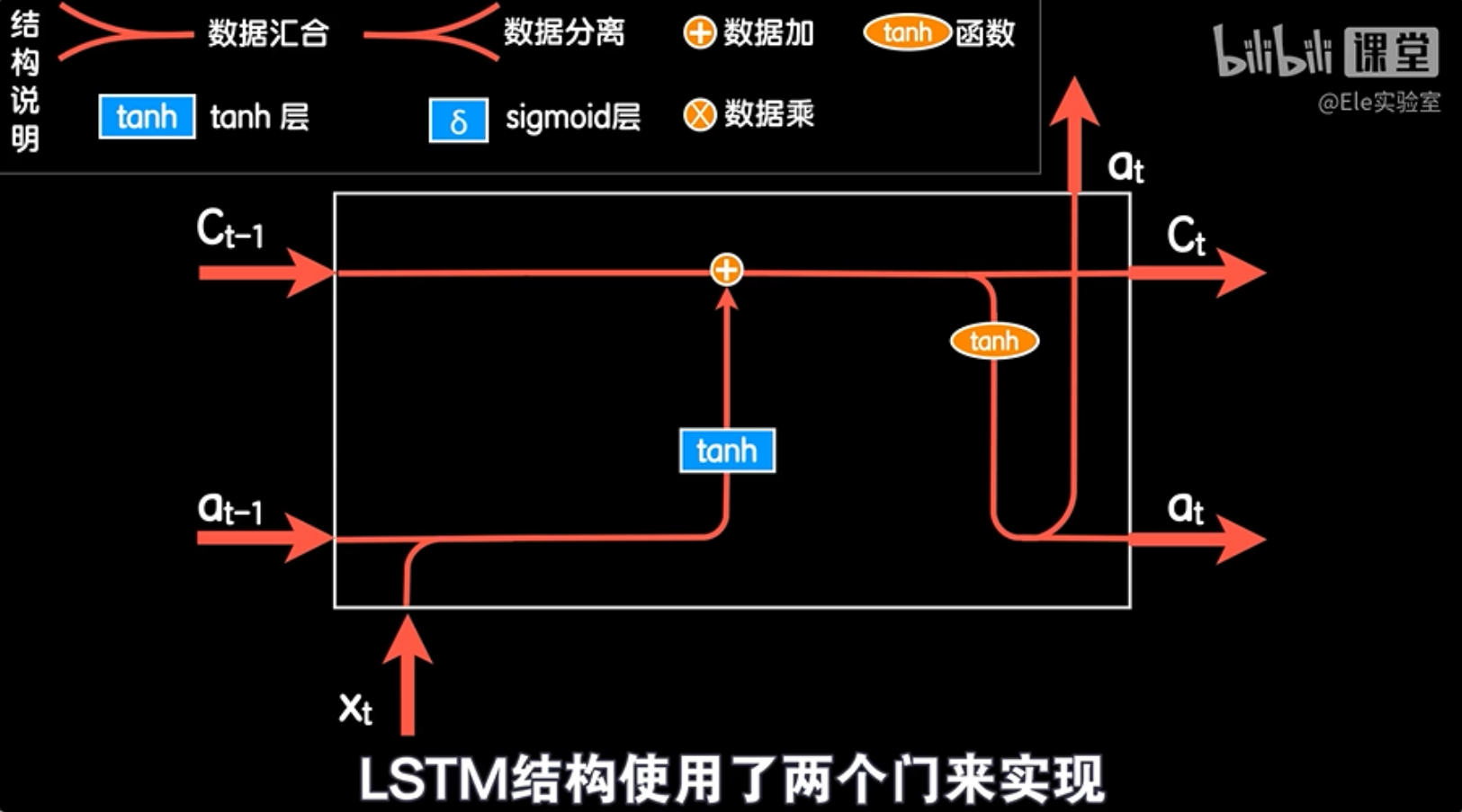
LSTM结构为了实现记忆和遗忘,使用了两个特殊的门:遗忘门和输入门。遗忘门是一个sigmoid网络层,它的输出值介于0到1之间。当我们把这个sigmoid层的输出和上一次的细胞状态值相乘时,可以控制上一次细胞状态值的遗忘程度。
如果sigmoid层的输出为0,那么上一次的细胞状态值就会被完全遗忘,相当于“全部忘记”。如果输出为1,那么上一次的细胞状态值会被完全保留,相当于“全部记忆”。如果输出介于0和1之间,那么上一次的细胞状态值就会被遗忘一部分,相当于“部分忘记”。
遗忘门的输入是当前的词向量和上一次的输出合并的数据。这意味着遗忘门可以根据当前和之前的数据共同决定遗忘多少之前的细胞值。
举个例子,当我们处理句子“上海电视台记者在北京街头采访了一名来自四川的年轻人”时,当我们遇到“四川”这个词时,遗忘门会根据这个词的上下文,决定是否忘记“北京”和“上海”这两个地点。这样,LSTM就能够根据当前的信息来调整其内部状态,从而更好地处理长依赖问题。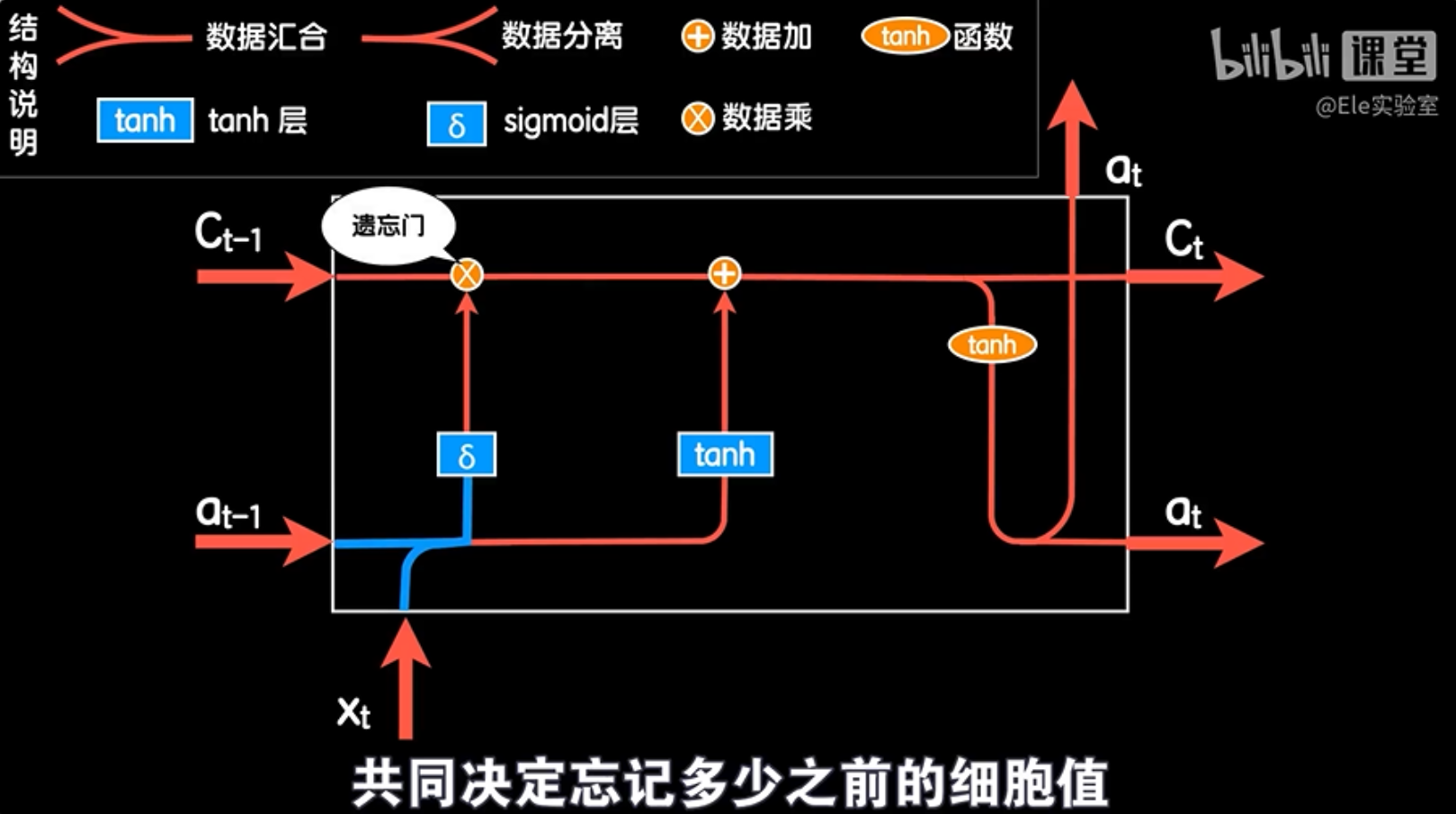
我们让本次的词向量和上一次输出合并的数据在再经过一个sigmoid层形成另外一个控制门,控制这个在之前标准RNN结构中用来更新的部分,换句话说这个门用来控制是否更新本次的细胞状态值,这就是第二个门——更新门,这样网络就会选择重要的词汇更新细胞状态,比如遇到四川这个词的时候,就选择更新我们的细胞状态。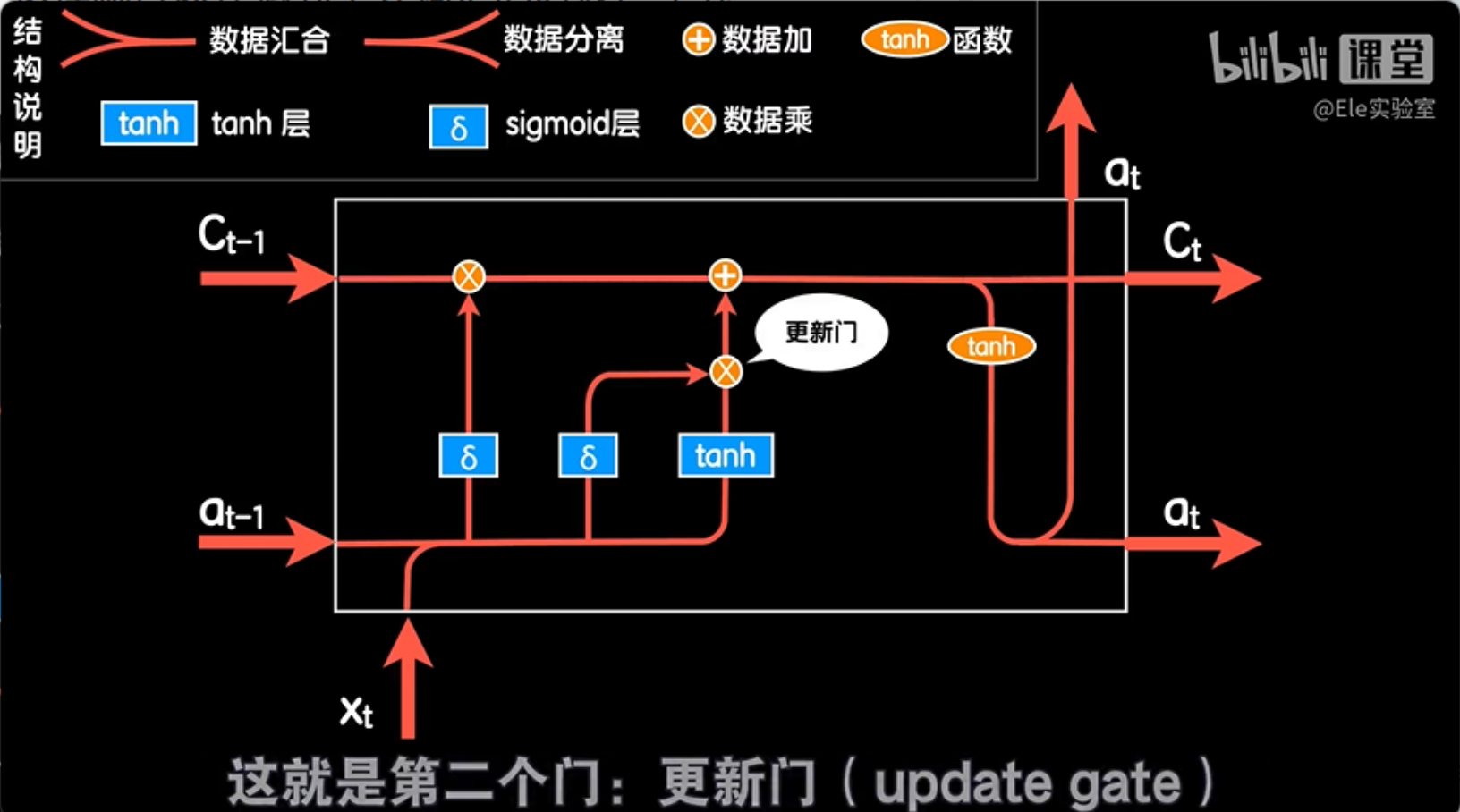
而除了记忆和遗忘这两个门以外,最终的输出还有一个输出门,我们说细胞状态值经过一个tanh函数之后,就是本次的输出值LSTM结构让它也被一个门控制着,这样就可以在遇到重要词汇的时候产生强输出,而不重要的时候产生弱输出。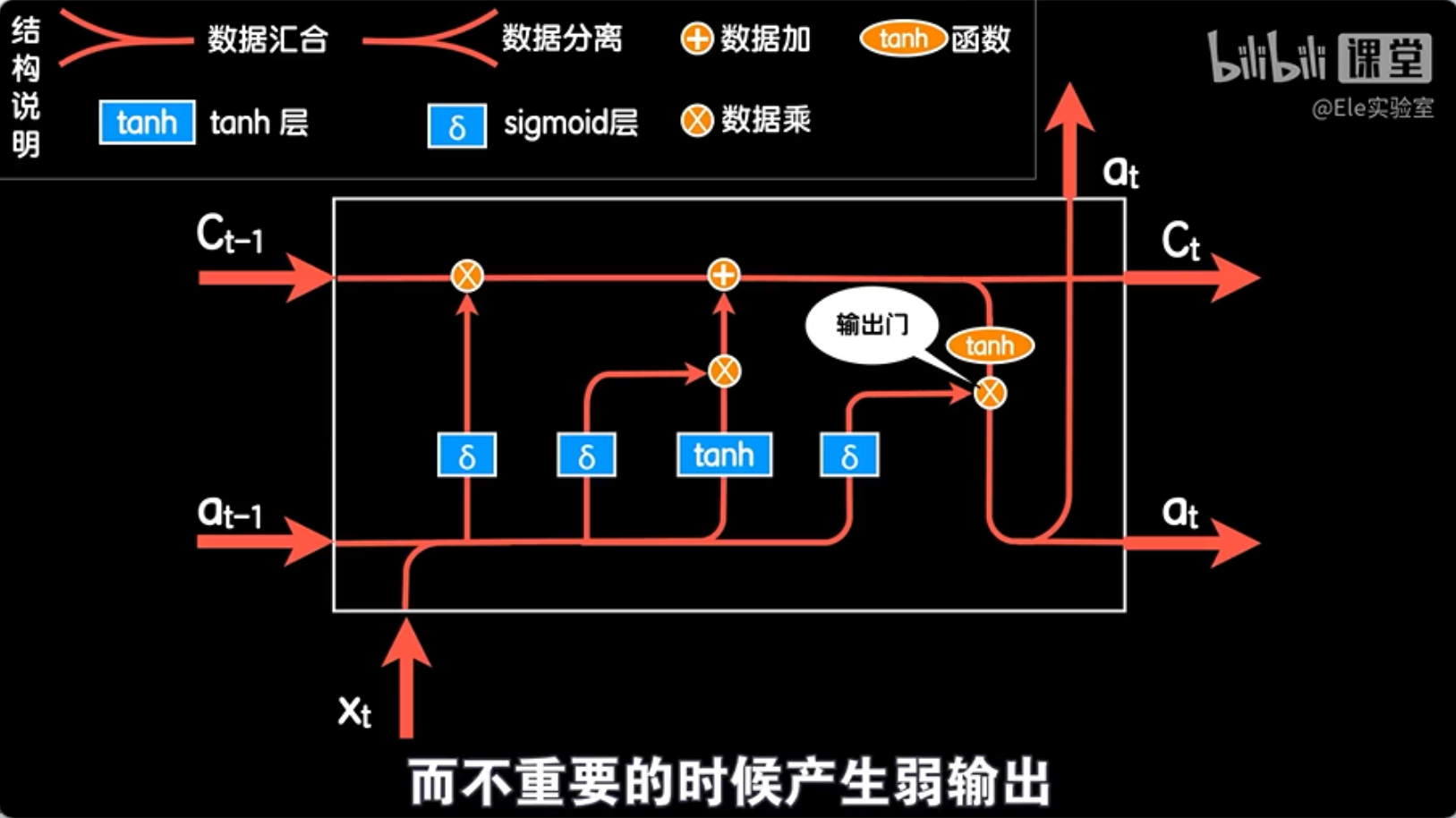
这就是LSTM模型的工作原理,从对其原理的基本讲解可以看出来,它之所以能够应对更长的序列依赖,正是因为除了输入和输出以外,他还添加了细胞状态的概念。如果我们单独看这个细胞状态的传递路径,你就会发现只要遗忘门和记忆门训练的得当,就能让像四川这种关键词在循环的过程中被传递的很长,甚至到最后一步,从而达到长时记忆的效果,而像性格这种对预测不重要的词,也能在短时间内被遗忘,从而达到短时记忆的效果。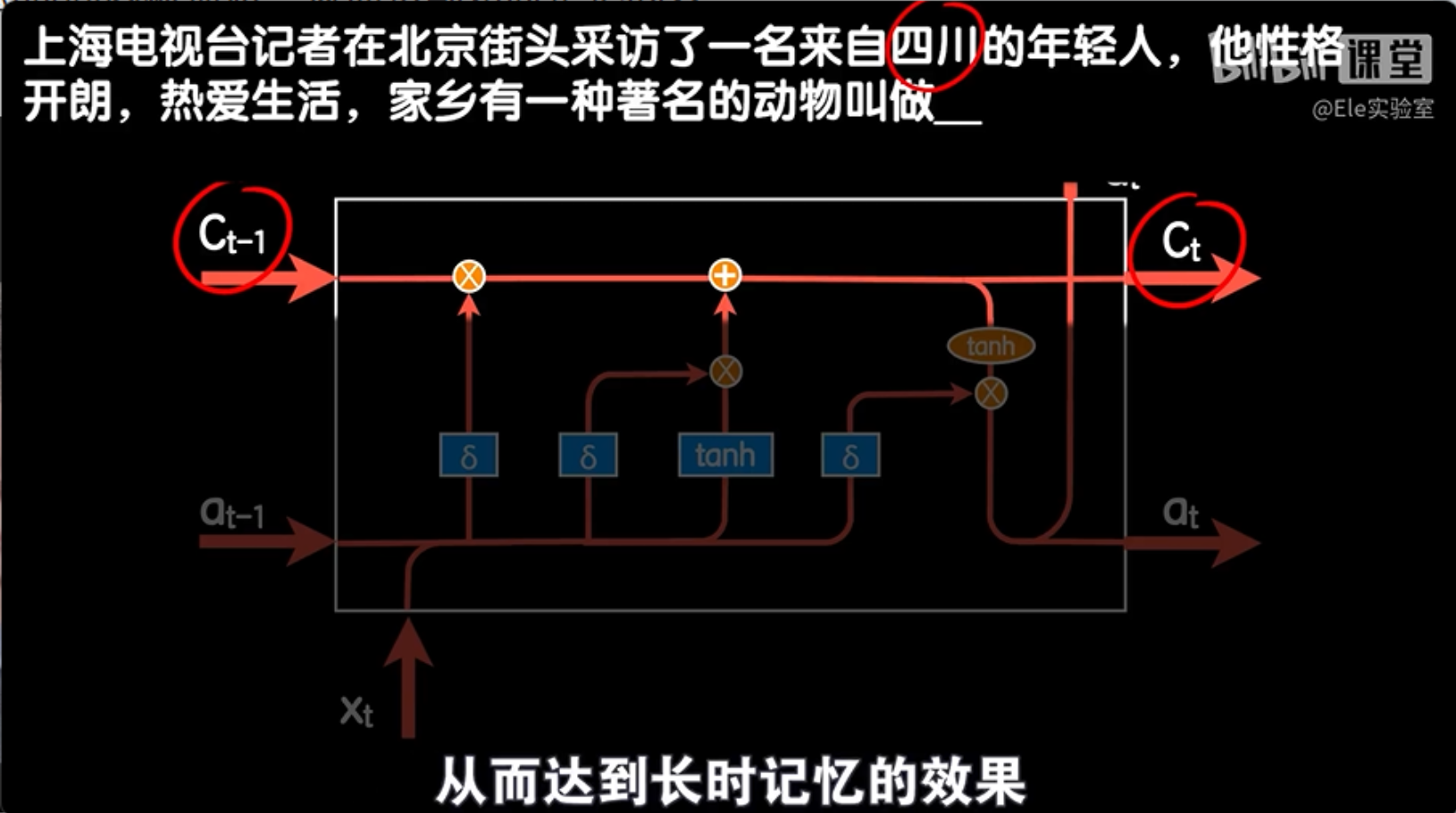
这就是LSTM长短时记忆这个名字的由来。Lstm网络是上个世纪90年代就已经出现了一种循环神经网络结构,在循环神经网络中有着极高的地位。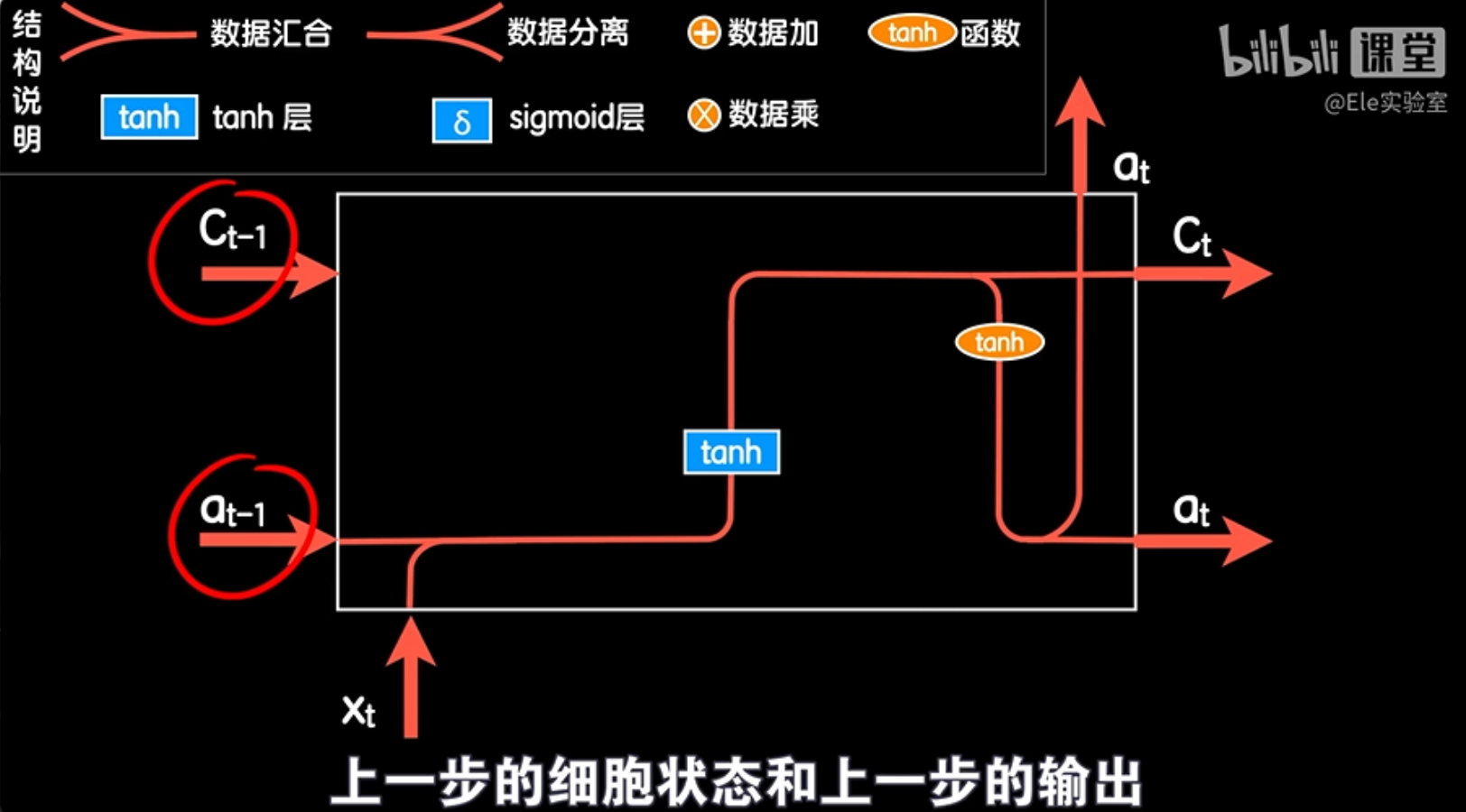
后来人们又提出了各种变种的循环身体网络,很多都是基于LSTM的改进。其中最为著名的就是GRU网络,它简化了LSTM结构,很多时候效果和LSTM也很接近,所以目前大家都乐于使用GRU结构。GRU结构很简单: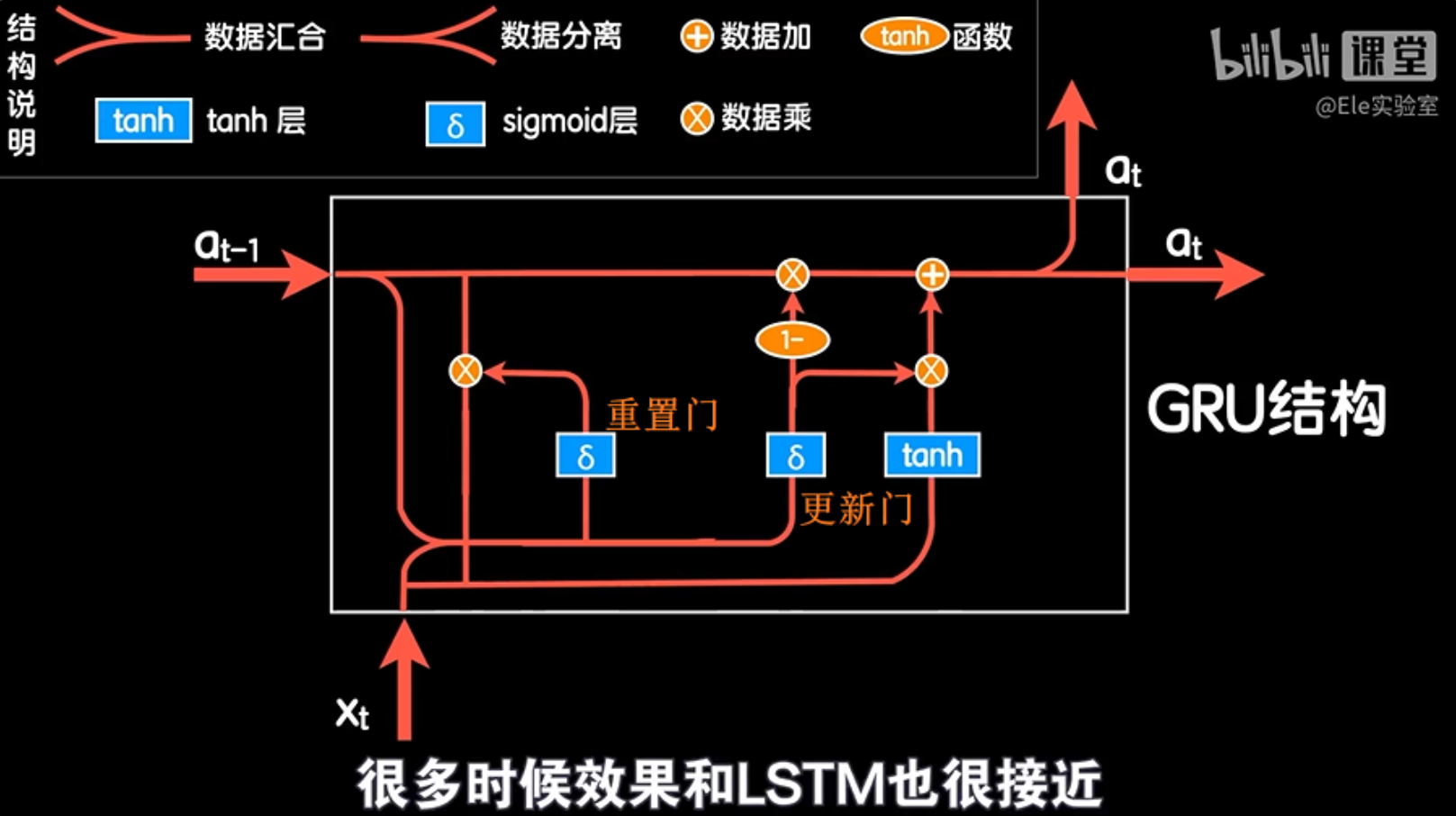
GRU对LSTM做了两个大改动:
- 将输入门(更新门)、遗忘门、输出门变为两个门:更新门(Update Gate)和重置门(Reset Gate)。将 LSTM 的“遗忘门”和“输入门”融合成了一个更新门。
- 将细胞状态与输出合并为一个状态
这里给大家推荐一个很有名的博客,Understanding LSTM networks,这个博客详细的解释了LSTM,最后介绍了一些包括GRU在内的LSTM的变种结构,同学们可以在课后自己研究一下,相比于LSTM,GRU了哪些改变和简化。
编程实验
好的,同学们,我们开始本节课的编程实验。我们将使用循环神经网络(RNN)来进行文本情感分类。首先,我们需要创建一个文件comments_lstm.py,然后将上节课的全连接神经网络代码复制过来,并对其进行修改,以适应LSTM结构。
我们首先删除上节课的全连接层,因为对于循环神经网络来说,词向量矩阵不需要平铺。因此,我们还需要删除Flatten层。
接着,我们导入keras中的LSTM模块,并直接在嵌入层后面添加LSTM层。这里的128是指LSTM输出数据的维度。我们还可以再添加一层LSTM,但通常来说,对于循环神经网络来说,堆叠的层数不宜过多。对于我们的问题,两层LSTM已经足够。为了在每一步都输出结果,我们给第一层的LSTM配置return_sequence=True。
最后,我们将嵌入层的trainable设置为False,以冻结嵌入层的参数,这样我们就不需要再训练词向量。我们运行模型,并在测试集上得到了84.9%的准确率,比上节课在全连接神经网络中的效果要好很多。
这样,我们就成功地将网络改造为使用LSTM结构的循环神经网络,并通过实验验证了其效果。
# 模型构建 #
model = Sequential()
model.add(Embedding(trainable=False, input_dim=vocalen,
output_dim=300, input_length=maxlen))
model.add(LSTM(128,return_sequences=True))
model.add(LSTM(128))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])
那我们再试试打开Embedding层的trainable,让词向量同时训练,看看有什么样的效果来运行一下。那最后呢在测试集上的准确率是85.6%。唉!这好像跟我们上节课差不多,那这是怎么回事呢?
model.add(Embedding(trainable=True, input_dim=vocalen,
output_dim=300, input_length=maxlen))
当我们打开嵌入层的训练时,嵌入层的参数矩阵会与网络的其他部分一起进行训练。嵌入层的参数数量很大,这会占用网络训练时的很大比重。换句话说,训练的重点会偏向于嵌入层,这可能导致LSTM和普通全连接层在训练时效果相近。
由于我们的语料数据集不是很丰富,所以如果开启嵌入层的训练,其效果可能不会很好。因此,更常用的方法是使用别人在海量数据集上训练好的词向量。
在本节课的项目文件夹中,有一个大文件,约1个多G,这是一个预训练的词向量文件,包含了几十万个中文词汇,每个词向量的维度是300。我们还提供了一个辅助代码chinese_vec.py,帮助大家读取这个文件。
首先,我们需要导入chinese_vec模块,然后调用它的load_word_vecs函数,这样就能将文件中的预训练词向量加载到我们创建的矩阵embedding_matrix中,这个矩阵就是一个使用别人训练好的词向量构成的词嵌入矩阵。通过这种方式,我们可以利用已经训练好的词向量,而不需要从头开始训练。
word_vecs = chinese_vec.load_word_vecs(input_file='./input/sgns.target.word-word.dynwin5.thr10.neg5.dim300.iter5')
embedding_matrix = np.zeros((vocalen,300))
for word, i in word_index.items():
embedding_vector = word_vecs.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
这样呢我们就可以把Embedding层的嵌入矩阵呢给替换掉我们。我们配置一下Embedding层的weights参数,让它等于我们的embedding_matrix。对了,别忘记这时候我们需要把trainable设置为False,冻结这一层,让他不参与训练,因为我们已经有了预训练的词向量了,嘛那这样呢我们就完成了改造,那我们来运行一下,看看使用别人训练好的词向量的效果。
# 模型构建 #
model = Sequential()
# Embedding层不训练,直接使用预训练好的词向量矩阵,得到词嵌入矩阵
model.add(Embedding(trainable=False, weights=[embedding_matrix],input_dim=vocalen,
output_dim=300, input_length=maxlen))
model.add(LSTM(128,return_sequences=True))
model.add(LSTM(128))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])
通过在测试集上使用预训练的词向量,我们这次的准确率达到了89.4%,接近90%,效果有了显著提升。实际上,我们也可以在上节课的全连接神经网络中使用同样的方法,但由于改造流程和这次一样,所以我们就不重复了。
课后,同学们可以自己尝试一下。我在课前测试的结果在测试机上的准确率大约是87%,比使用预训练词向量的LSTM在测试机上的准确率低2到3个百分点。
将上节课和这节课的几种方案在测试机上的准确率排列出来,我们可以清楚地看到,不使用预训练词向量也不自己训练的效果最差,自己训练的效果好一些,而使用第三方预训练的词向量的效果最好。同时,LSTM的效果在几种情况下都要比普通的全连接神经网络效果要好,这就说明循环神经网络在处理序列问题上确实技高一筹。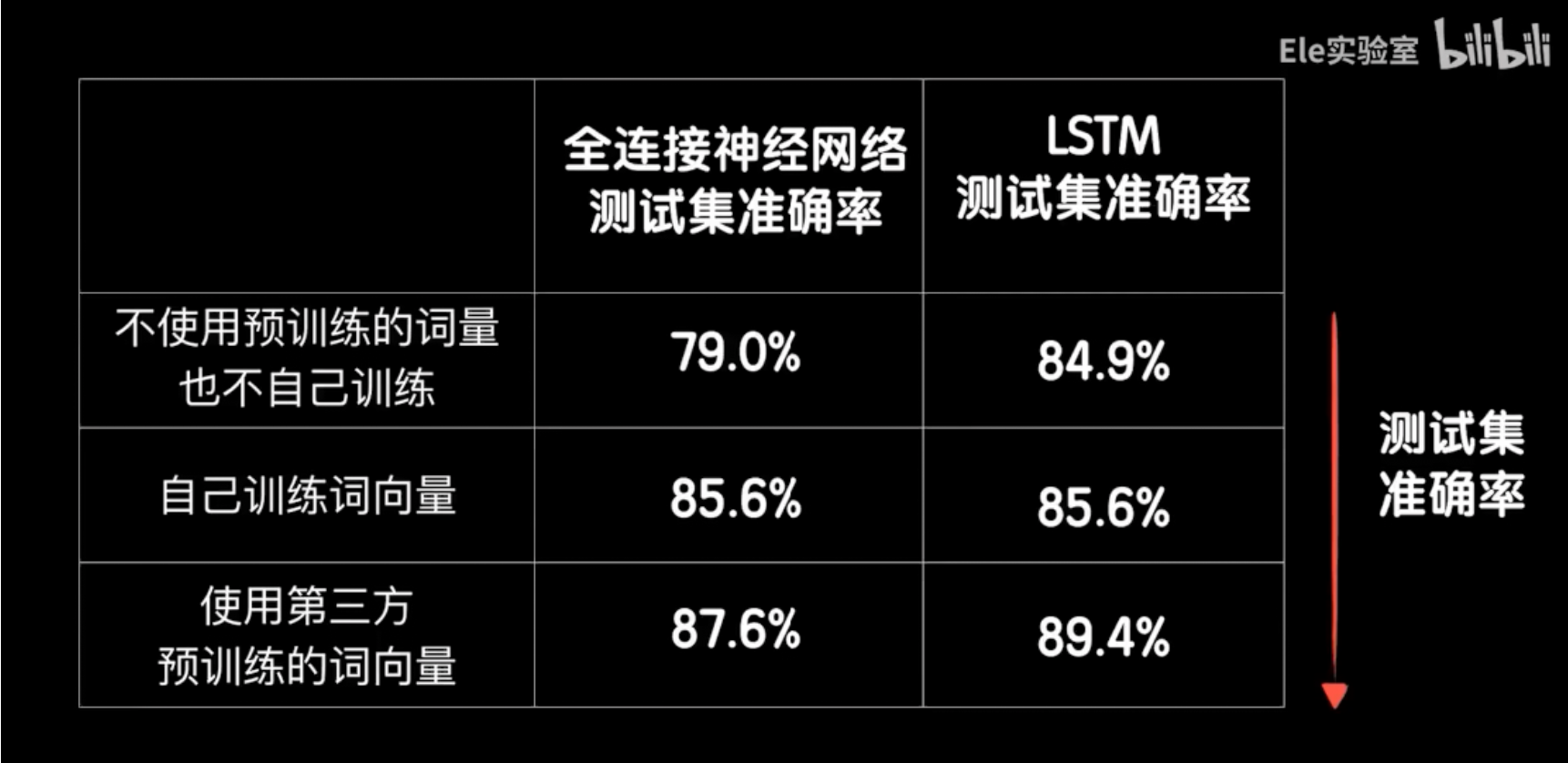



评论(0)
您还未登录,请登录后发表或查看评论