

前言
本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。
代码及工具箱
本专栏的代码和工具函数已经上传到GitHub:1571859588/xiaobai_AI: 零基础入门人工智能 (github.com),可以找到对应课程的代码
正文
卷积层在神经网络中的应用
在上节课中,我们学到了卷积操作的基本概念。现在,让我们看看如何将卷积运算应用到神经网络中。
假设我们有一个8×8像素的灰度图像,我们用一个3×3的卷积核对其进行卷积处理,得到一个6×6的结果。执行这个卷积运算的层叫做卷积层。处理完卷积后,我们可以将得到的结果转换成一个数组,然后送入后面的全连接层进行进一步处理。
你可能会好奇卷积核中的数值是如何确定的。实际上,这些值在开始时是随机初始化的,就像神经网络中的其他权重一样。通过训练过程,这些卷积核的值会学习调整,以更好地捕捉图像中的特征,比如垂直边缘、水平边缘或其他模式。
简而言之,卷积层通过其卷积核学习到的值,能够自动提取图像的特征,并为后续的全连接层提供更有意义的输入数据。这个过程使得神经网络能够更有效地理解和分类图像内容。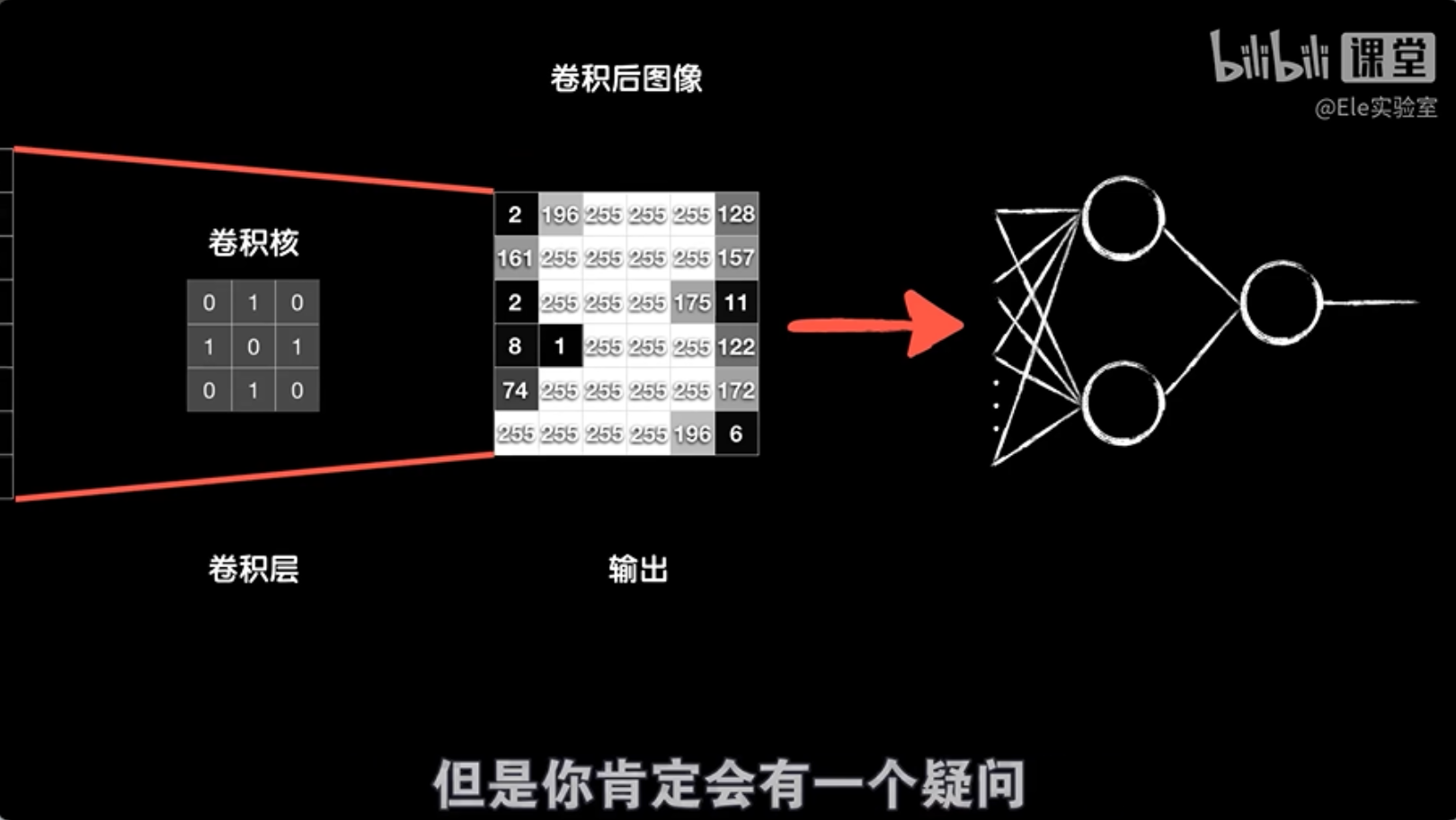
通过训练,我们可以找到合适的卷积核来提取图像中的不同特征。那么,卷积层中的参数是如何学习的呢?答案和全连接层的神经元一样,是通过反向传播和梯度下降来学习的。
卷积层和其他层一样,通过反向传播过程,我们可以将误差从最后一层逐步传回到前面的层。假设我们的原始图像是4×4的大小,使用一个3×3的卷积核进行卷积,得到一个2×2的矩阵。然后,这个结果被送入全连接层,假设全连接层只有两个神经元,最终通过输出层(对于MNIST数据集,输出层有10个神经元,对应10个分类)得到预测结果。这是前向传播的过程。
在反向传播过程中,我们首先计算代价函数,然后使用链式法则将误差传回到全连接层的权重和偏置参数上。那么,如何将误差传回到卷积层呢?
虽然卷积层的操作看起来和全连接层不同,但实际上我们可以将其类比为普通神经元的操作。卷积过程涉及卷积核与图像中的小区域(比如3×3的区域)对应元素相乘后求和,这与普通神经元的加权求和过程非常相似。
因此,尽管卷积层在前向传播时处理数据的方式不同,但在反向传播时,我们仍然可以应用类似全连接层的方法来更新卷积层的参数。这样,卷积层就可以通过训练学习到最佳的卷积核,以有效地提取图像特征。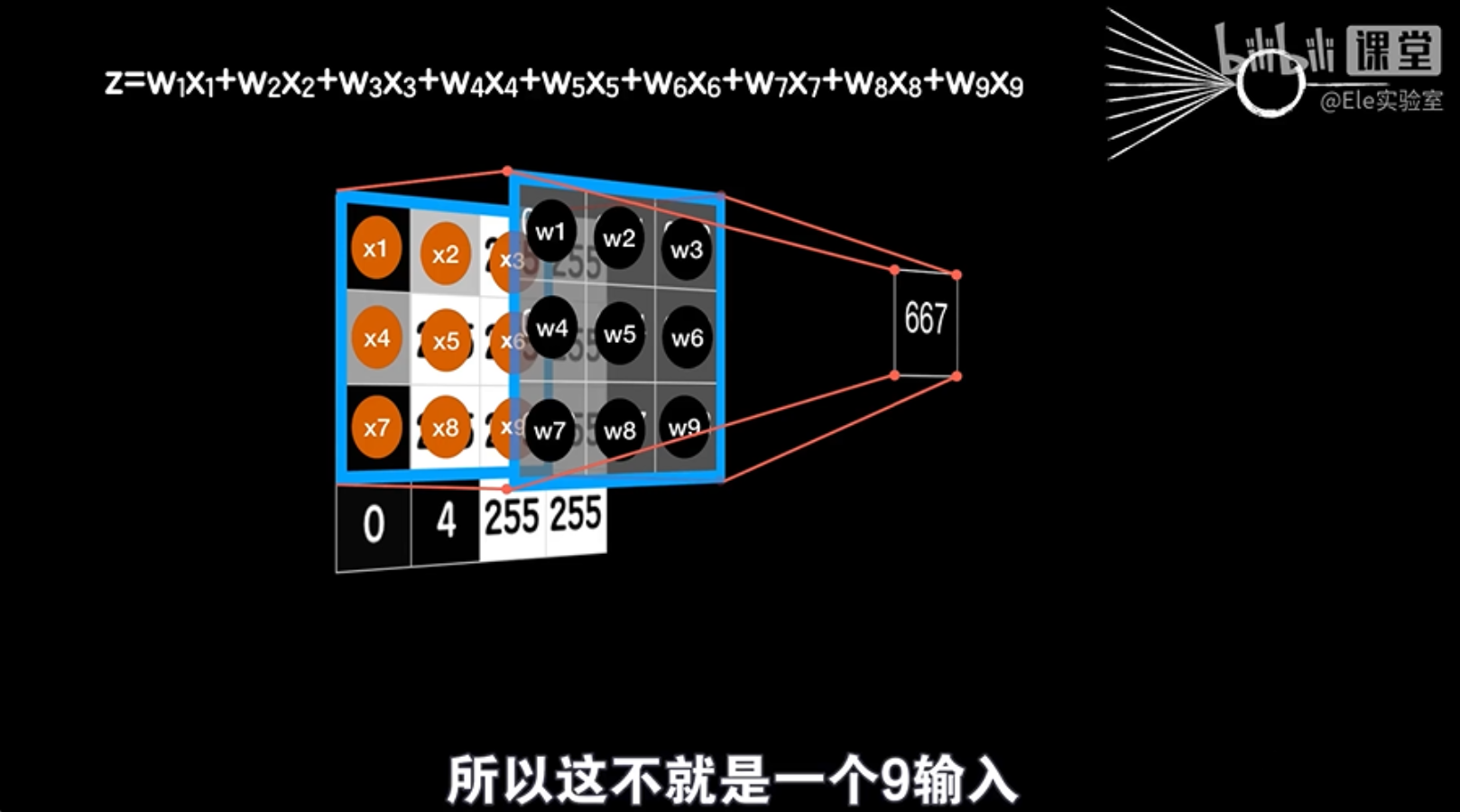
卷积层可以看作是多个普通神经元的组合,每个神经元都处理图像的一部分,并通过线性运算和激活函数得到输出。
举个例子:
想象一个3x3的图像作为输入,卷积核也是一个3x3的矩阵。我们将卷积核滑动到图像上,每次覆盖一个3x3的区域,并计算这个区域中所有像素点与卷积核对应元素相乘再相加的结果,再加上一个偏置项b。这个过程就相当于一个普通神经元的线性运算。
重复这个过程:
我们将卷积核在图像上滑动多次,每次都得到一个新的结果,这些结果分别对应不同的神经元。最终,我们将所有神经元的输出组合起来,并通过激活函数进行非线性变换,得到卷积层的最终输出。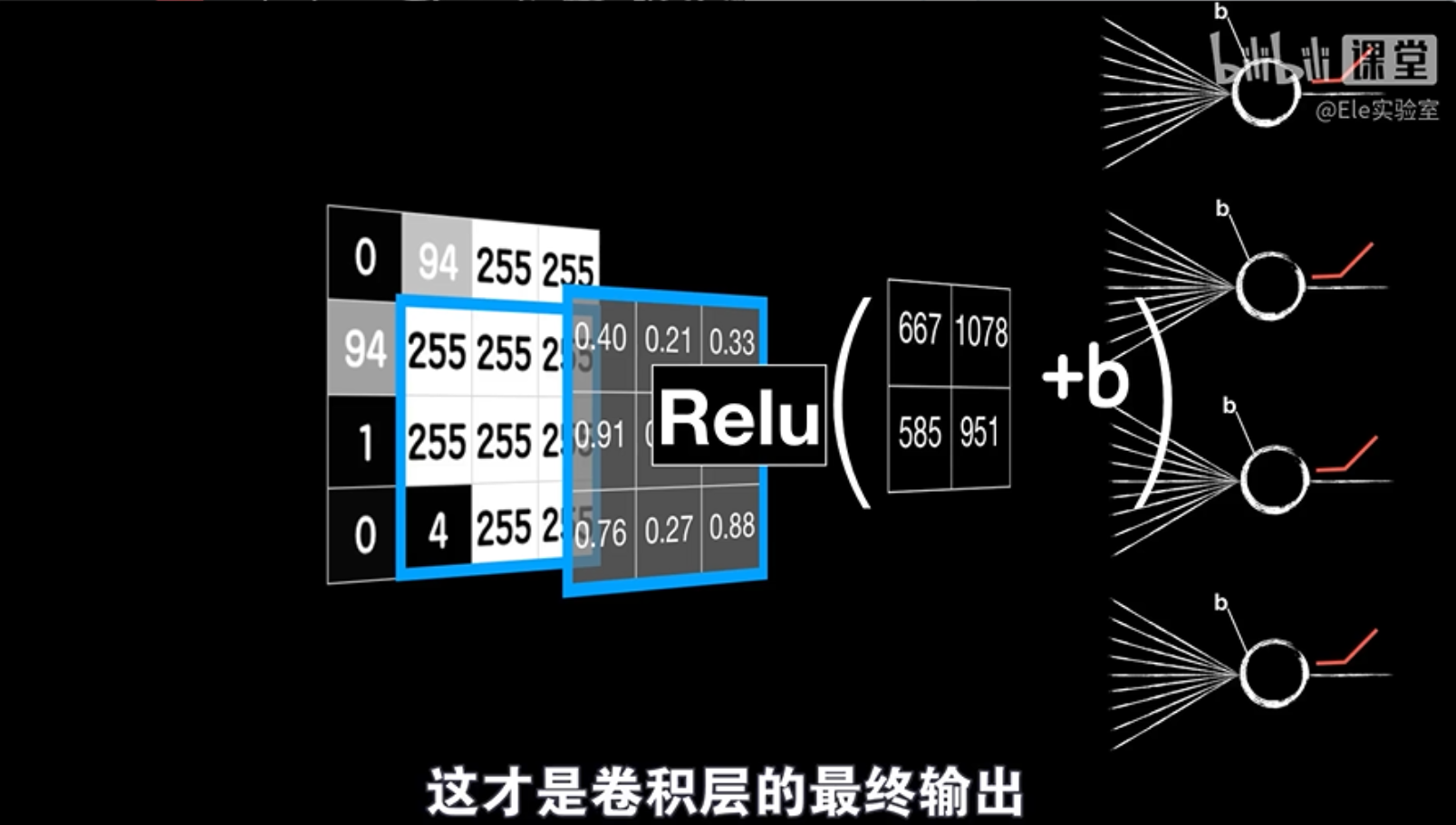
卷积层就像一个特殊的“积木”,它由多个小积木(神经元)组成,每个小积木都处理图像的一部分,并提取其中的特定特征,例如边缘或纹理。
这些小积木的特别之处在于,它们使用相同的“图纸”(权重参数)来建造,这意味着它们提取特征的方式是一样的。无论图像中的特征出现在哪个位置,它们都会用同样的方法去识别。这就是所谓的“参数共享”,它使得卷积层能够用更少的积木建造出复杂的结构,就像乐高积木一样。
相比于普通的神经元,卷积层中的小积木的输出是二维的,而不是一维的。当需要将卷积层的输出送到其他层时,需要将这个二维的输出“压扁”成一维的向量。
卷积层之所以能够通过参数共享提取特征,是因为图像具有平移不变性。这意味着图像中的特定特征,例如垂直边缘,在不同的位置具有相同的表达方式。因此,一个卷积核可以提取图像中的所有垂直边缘,而不需要为每个位置单独设计一个卷积核。
卷积层通过多个卷积核提取图像的不同特征,例如边缘、纹理等。每个卷积核都对应一个神经元,其输出是图像中特定特征的响应。卷积层的最终输出是所有神经元输出的组合。
卷积层是卷积神经网络的核心组件,它能够有效地提取图像特征,并降低模型参数数量,从而降低训练难度和计算量。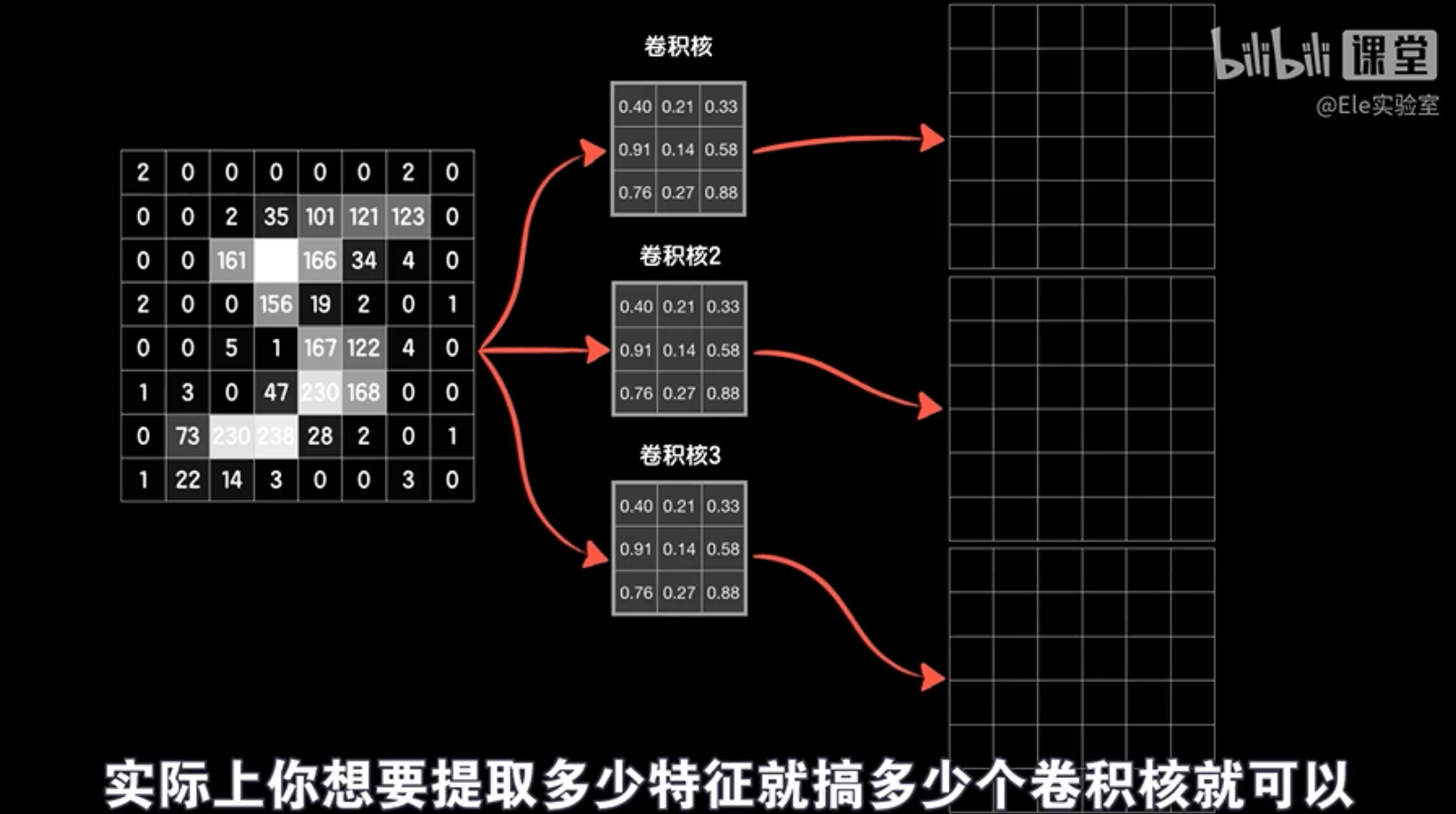
卷积层就像一个“积木工厂”,可以制造出许多“积木”,每个“积木”都能提取图像的不同特征,例如边缘或纹理。我们可以根据需要制造任意数量的“积木”,然后将它们堆叠起来,形成更复杂的结构。
在卷积层中,每个“积木”都由多个“小积木”(神经元)组成,每个“小积木”负责处理图像的一部分。这些“小积木”使用相同的“图纸”(权重参数)来建造,这意味着它们提取特征的方式是一样的。
我们可以将卷积层的输出“压扁”成一维的向量,然后将其输入到全连接层中进行进一步处理。但是,在将输出送入全连接层之前,我们可以继续对输出进行卷积操作,以提取更复杂的特征。
卷积运算不仅可以在二维图像上进行,还可以在三维数据上进行。例如,如果我们有一个包含多个通道的彩色图像,我们可以使用三维卷积核对其进行卷积,以提取跨通道的特征。
三维卷积的原理与二维卷积类似,只是将操作扩展到三维空间。三维卷积核在三维数据上滑动,找到对应位置并进行元素相乘和求和,得到卷积结果。
通过堆叠多个卷积层,我们可以构建出深度卷积神经网络,从而提取更复杂和抽象的特征,最终实现更强大的图像识别和分类能力。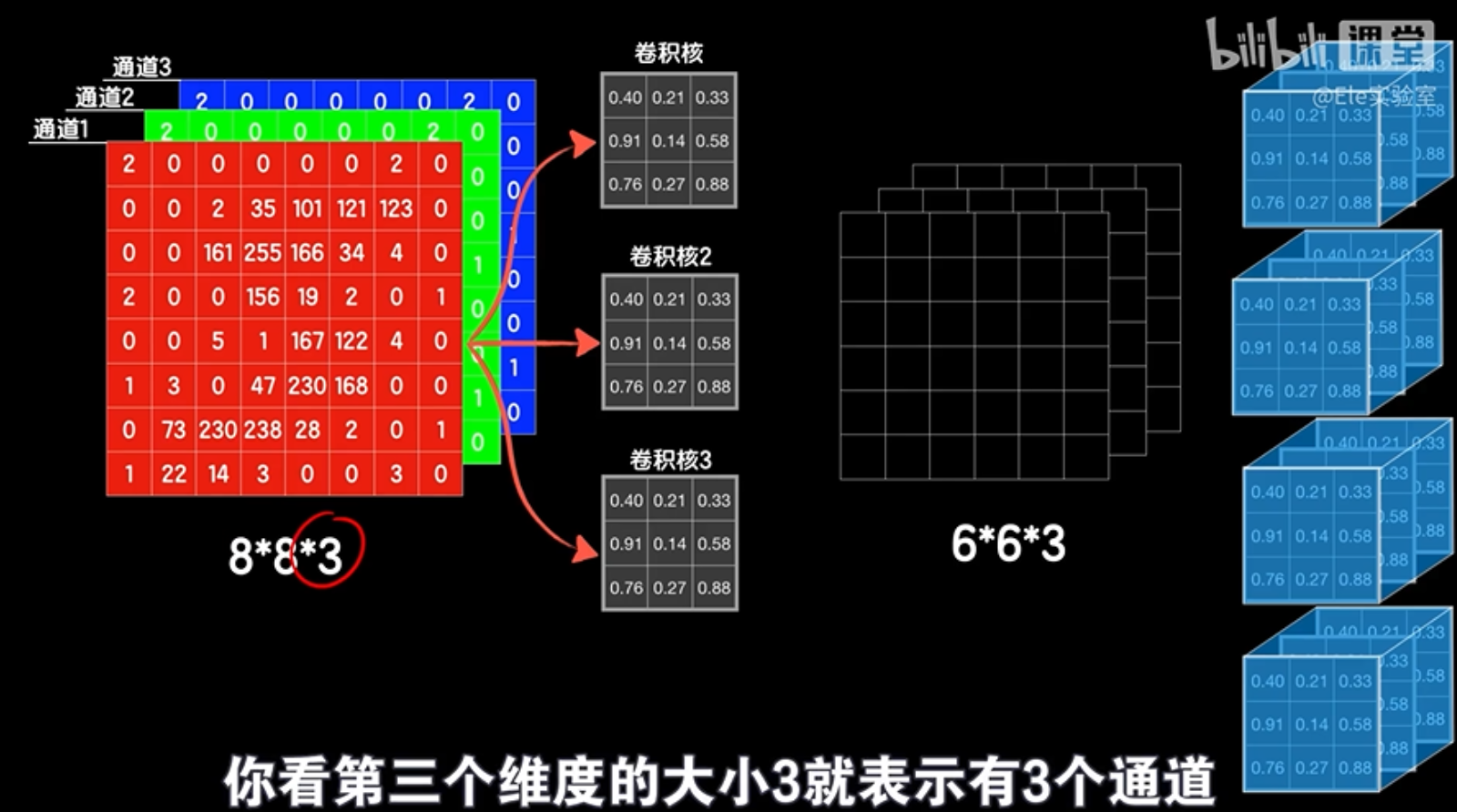
在处理图像等高维数据时,我们经常使用卷积神经网络(CNN)。这些网络通过应用卷积层来提取图像特征。卷积层使用的是三维卷积核,其第三个维度的大小必须与输入数据的通道数相匹配。例如,如果输入数据有三个通道,那么卷积核也必须有三个通道。
当我们在神经网络中连续使用多个卷积层时,后续卷积层的卷积核的第三个维度必须与前一层的输出通道数相匹配。例如,如果第一个卷积层的输出是2×2×5的张量,那么第二个卷积层的卷积核可以是3×3×5,其中的5确保了卷积核能够与前一层的输出匹配。
除了卷积层,卷积神经网络还经常使用池化层。池化层通过减小数据的维度来简化网络计算。最常见的池化操作是最大池化和平均池化。最大池化通过选择2×2(或其他尺寸)区域内的最大值来简化数据,而平均池化则计算这些区域的平均值。池化层有助于保留重要特征并减少计算量,但它们没有需要学习的参数。
总的来说,卷积神经网络通过卷积层提取图像特征,并通过池化层简化数据,以便进行更高效的处理。
编程实验
LeNet-5卷积神经网络模型:识别acc98.4%
-
模型

- 6核(5,5)卷积层+平均池化层(2,2)+6核(5,5)卷积层+平均池化层(2,2)+120个神经元全连接层+84个神经元全连接层+10个神经元softmax输出层
- 除了最后一层输出层激活函数选择softmax,其他层激活函数都选择relu
- optimizer选择SGD。学习率0.05,损失函数选择categorical_crossentropy
- 训练epochs=3000, batch_size=4096
- 使用60000个手写图片进行训练
-
测试结果:使用10000个手写图片进行测试
- 总的识别率:98.4%
-
代码
import numpy as np import matplotlib.pyplot as plt from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD from keras.models import load_model from keras.datasets import mnist from tensorflow.keras.utils import to_categorical from keras.layers import Conv2D from keras.layers import AveragePooling2D from keras.layers import Flatten (X_train, Y_train), (X_test, Y_test) = mnist.load_data() X_train = X_train.reshape(X_train.shape[0], 28,28,1)/255.0 X_test = X_test.reshape(X_test.shape[0], 28,28,1)/255.0 Y_train = to_categorical(Y_train, 10) Y_test = to_categorical(Y_test, 10)
创建模型
model = Sequential()
"""
strides = (1,1):每次滑动步长为1
padding ='valid'不加填充 / 'same' 填充前后不变
"""
model.add(Conv2D(filters=6, kernel_size=(5,5), strides=(1,1),padding='valid',activation='relu', input_shape=(28,28,1)))
model.add(AveragePooling2D(pool_size=(2,2))) # 平均池化层
model.add(Conv2D(filters=16, kernel_size=(5,5), strides=(1,1),padding='valid',activation='relu'))
model.add(AveragePooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(units=120, activation='relu'))
model.add(Dense(units=84, activation='relu'))
model.add(Dense(units=10, activation='softmax')) # 输出层用softmax函数,做多分类
送入训练
model.compile(loss='categorical_crossentropy', optimizer=SGD(
learning_rate=0.05), metrics=['accuracy']) # 多分类问题使用交叉熵做代价函数
model.fit(X_train, Y_train, epochs=3000, batch_size=4096, verbose=1)
训练完毕,查看loss和accuracy
loss, accuracy = model.evaluate(X_test, Y_test)
print(f"{loss=}")
print(f"{accuracy=}")
保存模型
-
模型搭建

- 32核(3,3)卷积层+最大池化层(2,2)+64核(3,3)卷积层+64核(3,3)卷积层+64个神经元全连接层+10个神经元softmax输出层
- 除了最后一层输出层激活函数选择softmax,其他层激活函数都选择relu
- optimizer选择adam,损失函数改用sparse_categorical_crossentropy
- 训练epochs=200, batch_size=32
- 使用60000个手写图片进行训练
-
测试结果:使用10000个手写图片进行测试
- 总的识别率:99.21%,79个手写数字(总共10000个测试图片)未成功识别
-
各手写数字识别率
- 0: 99.49%
- 1: 99.21%
- 2: 99.22%
- 3: 99.60%
- 4: 99.29%
- 5: 98.88%
- 6: 98.85%
- 7: 99.32%
- 8: 99.49%
- 9: 98.71%
- 识别率最高的数字是:3,识别率为:99.60%
- 识别率最低的数字是:9,识别率为:98.71%
-
代码
model.save('./model/11_LeNet-2.h5')
自行搭建的卷积神经网络模型:识别acc99.21%
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.models import load_model
from keras.datasets import mnist
from keras.layers import Conv2D
from keras.layers import AveragePooling2D,MaxPooling2D
from keras.layers import Flatten
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28,28,1)/255.0
X_test = X_test.reshape(X_test.shape[0], 28,28,1)/255.0
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
创建模型
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(
1, 1), padding='valid', activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(
1, 1), padding='valid', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(
1, 1), padding='valid', activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train, Y_train, epochs=200, batch_size=32, verbose=1)
训练完毕,查看loss和accuracy
loss, accuracy = model.evaluate(X_test, Y_test)
print(f"{loss=}")
print(f"{accuracy=}")
保存模型
model.save('./model/11_CNN.h5')



评论(0)
您还未登录,请登录后发表或查看评论