

描述
接上一篇,对论文中的实验结果进行分析
PLARD使用的网络:视觉PSPNet,雷达ResNet-101
IV. EXPERIMENT
在本节中,我们评估了基于KITTI道路检测的PLARD的有效性。我们首先采用5倍交叉验证来说明PLARD中各个部分的有效性。然后,我们在测试集上评估PLARD,并将其与其他最先进的道路检测算法进行比较。
A. Dataset数据集
KITTI道路基准[16]因其全面性而受到道路检测研究人员的欢迎。KITTI使用多种评估指标来评估算法性能,并提供各种传感器(包括视觉摄像机、激光雷达传感器和GPS)捕获的信息。KITTI包含289幅用于训练的图像和290幅用于测试的图像,均包含三种不同的道路场景类别,包括城市标记道路(UM)、城市多标记车道(UMM)和城市无标记道路(UU)。为了公平评估,KITTI没有提供测试图像的真实情况,在线评估的提交数量有限。所有结果均可在其官方网站上公开获取。
我的分析:KITTI数据集的介绍,没什么可说
B. Evaluation Metrics评估指标
我们遵循KITTI使用的标准评估指标,详见[43]。这些度量包括最大F1度量(MaxF)、平均精度(AP)、准确率(PRE)、召回率(REC)、误报率(FPR)和误报率率(FNR)。MaxF依靠后四种度量计算得到。根据KITTI的评估系统,将所有结果转换为鸟瞰空间进行评估,对评估算法进行排序使用的是MaxF这一评估指标。
我的分析:评价指标使用的是参考文献43的设计,这篇文章的名字我列在下面,并给出该文献设置的度量方式的公式
文献43:A New Performance Measure and Evaluation Benchmark for Road Detection Algorithms
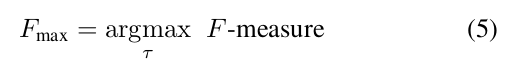
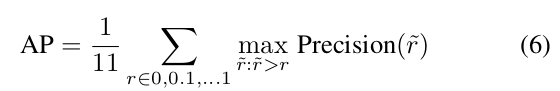
C. Implementation and Model Training实验和模型训练
PLARD的实现简单明了。在本节中,我们将讨论应考虑的一些实现细节。
在处理高差图像时,我们将N_x和N_y设置为以(x,y)为中心的7×7窗口内的位置,因此M的最大值为48(不包括中心)。高度差图像中的所有值在范围[0,255]内重新缩放。
我的分析:邻域设置为7×7窗口
在PLARD中,我们使用PSPNet[42]作为基于视觉图像的DCNN,并使用ResNet-101[41]作为主干。我们还使用101层DCNN作为f_{lidar}并提取激光雷达特征。为了避免使用两个DCNN带来过多的计算负荷,在同一层我们让基于激光雷达的DCNN的通道数是基于视觉图像的DCNN的通道数的8分之一。此外,我们在基于激光雷达的DCNN中使用混合卷积[45],以较少的通道数增强其表达能力。在融合过程中,我们使用统一的通道数,即256。等式10中的参数λ设置为0.1。关于等式11中的损耗权重,我们根据经验将w_{parsing}、w_{aux}和w_{lidar}分别设置为1.0、0.16和0.4。
我的分析:提出方法中的参数设置,基本上是经验值(意思就是反正这些数字用起来就是效果好)。
在训练和测试期间,我们将所有图像调整为384乘1280。我们采用SGD算法优化所有参数,学习率从1×10^{-4}逐渐下降至1×10^{-6}。我们使用80个epoch训练模型,并使用NVIDIA的GTX Titan GPU进行计算。在消融研究(类似于控制变量)和测试集评估中,PLARD的实施和实验设置基本一致(也有部分差异)。差异是这样的:首先,为了更好地说明模型不同部分的有效性,我们在消融研究中从头训练模型。与消融研究相反,我们使用外部数据[46],来预训练PLARD系统中要使用的基于视觉图像的DCNN,以提高测试集评估的鲁棒性。此外,为了测试集,我们通过采用多种数据增强技术来改进PLARD,包括多尺度训练和测试、随机裁剪和干扰图像亮度。最后,我们将测试集评估的训练时间延长到消融研究的三倍。
我的分析:消融实验下一节会介绍。消融实验是为了说明,本文提出方法的各个部分:数据空间自适应和特征空间自适应等的有效性,因此会采用控制变量,并且每一次都会重新训练。而评价PLARD整体的好坏,首先需要提出的全部子部分一起参与,再增加一些trick来说明,PLARD是很棒的。作者说了,他先将视觉DCNN用别的数据预训练了,并且对训练数据进行了一系列的数据增强,并增加了训练时间,这些都是为了提升PLARD的性能。
D. Ablation Study消融实验
我们首先评估不同PLARD组件的有效性,并在训练集上使用5倍交叉验证将其性能与baseline进行比较。表一显示了所有“UM”、“UMM”和“UU”任务的平均结果。特别是,我们研究了两个重要的点
(1)与直接投影的激光雷达点相比,基于高度差的变换操作的好处
(2)与简单级联的直接融合相比,所提出的基于学习的特征空间自适应模块,通过级联融合结构的方式实现的性能提升。
可以看出,基于高度差的变换技术和特征空间自适应技术与它们的对应技术相比都实现了有希望的改进。具体而言,使用高度差图像(L-ADT)进行的训练比使用直接投影激光雷达点(L-Proj)的道路检测模型“MaxF”高出约3个点。此外,融合视觉和激光雷达信息可以改善基于视觉图像的道路检测基线,表明激光雷达有助于增强鲁棒性。通过通过级联融合结构进一步引入特征空间自适应过程,最终模型(Img+L-ADT+FSA)在比较方法中实现了最高性能,证明了特征变换和级联融合结构的有效性。注意,基于激光雷达的道路检测的速度不包括原始数据投影和转换的处理时间。
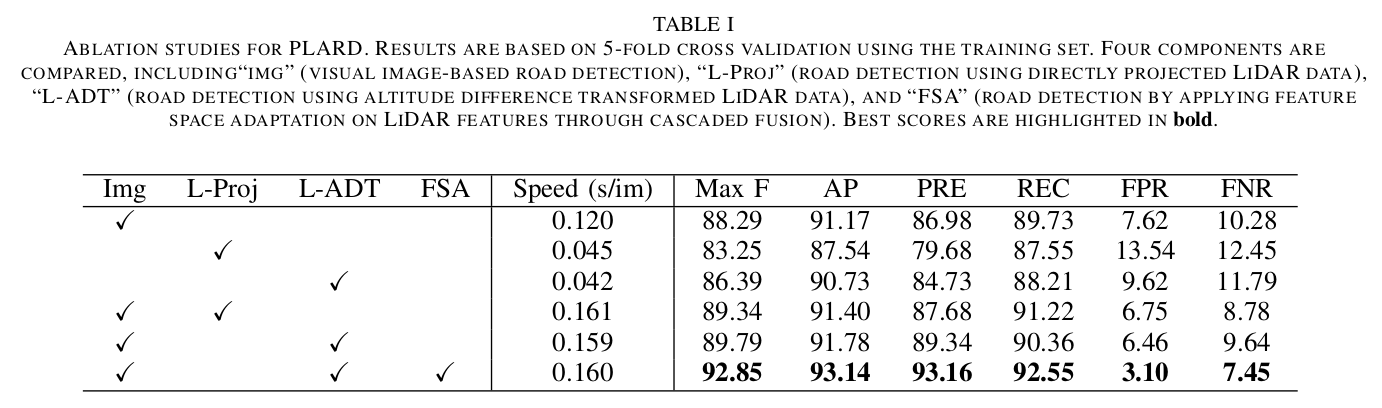
我的分析:消融实验结果分析得出了上表。可以看出仅仅L-ADT(点云高度差)比L-Proj(点云单纯投影)效果好,图像+L-ADT比图像+L-Proj的效果好(只有召回率和FN稍微差了一点点)。完整的PLARD(增加了FSA,级联融合的特征自适应)后,效果是最好的。也就是说,PLARD每一个部分都是很有用的
E. Evaluation on the Test Set测试集上的评估
1) Quantitative Results定量结果
使用baseline中的所有训练图像,我们评估基于视觉图像的PSPNet作为道路检测基线,并使用多尺度增强测试评估单个PLARD模型和3模型PLARD集成的性能。我们将基于视觉图像的PSPNet和我们的模型与其他最先进的道路检测算法进行了比较,包括SPRAY[4]、FCN-LC[8]、HybridCRF[15]、FTP[29]、Up Conv[39]、LoDNN[12]、MultiNet[38]、Stixel Net II[44]、RBNet[10]、LidCamNet[11]和NF2CNN。所有结果均在KITTI评估服务器上计算,其他研究的结果基于KITTI网站上报告的分数。整体算法性能如表二所示,不同任务(如UM、UMM和UU)的详细性能如表三所示。
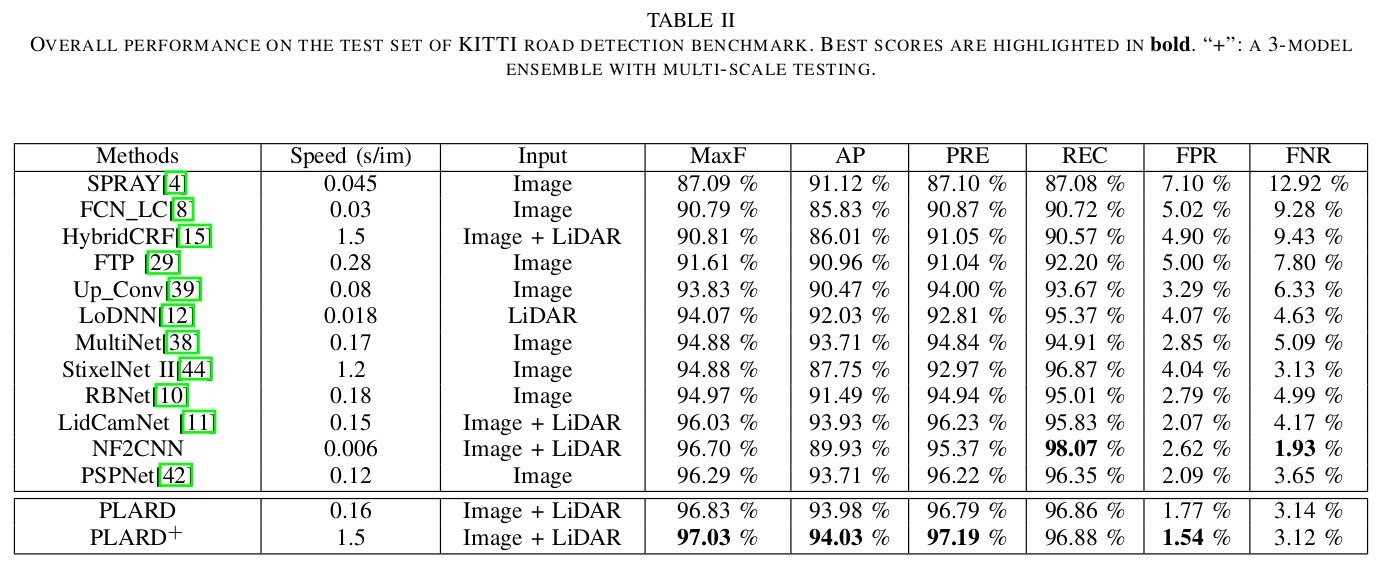
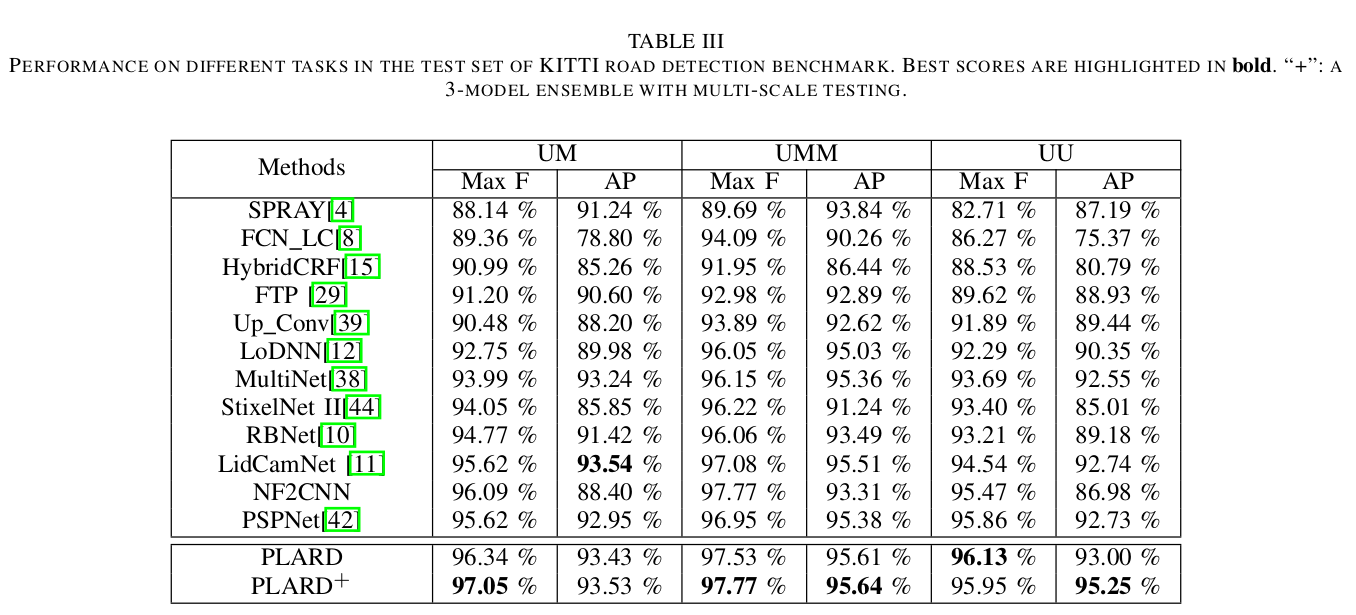
我的分析:从表中可以看出,PLARD的性能基本上是完全领先的,显而易见。尤其是PLARD+,使用了多尺度的测试并且进行了数据增强,进一步提高了结果。
PLARD和其他最先进道路检测系统的总体结果详见表二。与其他道路检测算法相比,单PLARD模型显著改善了基于视觉图像的PSPNet,并获得了更高的MaxF分数。通过使用多尺度测试和模型集成进一步增强PLARD,我们获得了大多数度量的最佳分数,证明了所提出的系统对于鲁棒道路检测的有效性。特别是,我们的方法实现了最高的MaxF和AP分数,而通常MaxF和AP会被用作评价算法的性能指标。
除总体结果外,我们还比较了表三中单独任务(“UM”、“UMM”和“UU”)的性能。可以观察到,PLARD在大多数MaxF和AP度量方面也优于其他比较算法。特别是,在“UM”上,增强的PLARD系统比其他方法中性能最好的算法NF2CNN的MaxF性能高出约1个百分点。此外,对于“UU”任务上的AP,我们的方法比第二级方法LidCamNet[11]高出约2.5个点,证明了所提出的PLARD系统的可推广性。
Qualitative Results定性结果

图5显示了PLARD在baseline测试集上的一些定性结果。从左到右的列分别显示PLARD对UM、UMM和UU任务的道路检测结果。可以看出,我们的方法对严重的光照条件(如重阴影和过度曝光区域)具有鲁棒性
V. CONCLUSIONS
在本研究中,我们介绍了一种新的道路检测方法,称为PLARD,该方法通过将激光雷达信息逐步适应视觉信息。PLARD首先执行数据空间适应,该适应方法通过应用基于高度差的变换,将激光雷达数据适配到2D图像空间以与透视图对齐。然后,PLARD通过级联融合层执行特征空间自适应,以使学习的激光雷达特征适应视觉特征。通过连续利用这两个自适应模块,PLARD利用了视觉和激光雷达信息,并对城市场景的各种挑战性方面具有鲁棒性。我们在著名的KITTI道路检测基准上验证了PLARD模型,该模型优于其他最先进的道路检测模型,目前排名领先,证明了其相对于现有方法的有效性和优越性。
总结
这一篇文章主要介绍了PLARD的实验结果,并给出了我的理解。这篇文章也提到了算法使用的神经网络是PSPNet和ResNet-101。值得注意的是,表2说明了PLARD+的每帧检测速度是1.5s,如何工程化应用还需要我再进一步实验看一下,至少现在看来时间是有点久的。
我已经在跑它的代码了,后期看有没有时间再写一篇关于代码的分析吧

评论(2)
您还未登录,请登录后发表或查看评论