

0. 简介
Segment Anything Model (SAM) 最近在各种计算机视觉任务上展现了令人瞩目的零样本迁移性能 。然而,其高昂的计算成本对于实际应用仍然具有挑战性。MobileSAM 提出通过使用蒸馏替换 SAM 中的重图像编码器,使用 TinyViT,从而显著降低了计算需求。然而,由于自注意力机制导致的内存和计算开销,其部署在资源受限的移动设备上仍面临挑战。
最近,RepViT 通过将 ViTs 的高效架构设计集成到 CNN 中,实现了移动设备上的最佳性能与延迟权衡。在这里,为了在移动设备上实现实时分割任何事物,作者遵循 [27] 的方法,用 RepViT 模型替换 SAM 中的重型图像编码器,最终得到了 RepViT-SAM 模型。相关的代码已近在Github上开源了。
1. 方法论
SAM [13]由一个重量级的基于ViT的图像编码器和一个轻量级的基于提示的掩模解码器组成。它庞大的图像编码器占据了大部分推理时间开销。因此,MobileSAM [27]建议将SAM中默认的ViT-H [6]图像编码器替换为轻量级的TinyViT [24]。TinyViT由四个逐渐降低分辨率的阶段组成。TinyViT的初始阶段由利用反向残差块[20]的卷积块组成。为了在模型开始时降低分辨率,采用了步幅为2的两个卷积块。类似地,相邻阶段之间也采用了步幅为2的卷积块进行空间降采样。为了使TinyViT的最终分辨率与原始SAM中ViT-H图像编码器的分辨率保持一致,MobileSAM将TinyViT中最后一个降采样卷积的步幅设置为1。此外,MobileSAM提出了解耦蒸馏策略,以有效训练轻量级图像编码器,其中TinyViT模型直接从原始SAM中的ViT-H蒸馏而来,而无需提示引导的掩模解码器。尽管MobileSAM显著降低了分割任何物体的计算需求,但在移动设备上部署仍然面临着相当大的挑战。如表1所示,由于其巨大的内存占用,MobileSAM无法在iPhone 12上运行。此外,在Macbook上,其处理单张图像的推理时间为494毫秒,表明有很大的改进空间。
最近,RepViT [21]通过重新审视ViT视角下CNN的高效设计,展示了在移动设备上性能和延迟的权衡方面的最新成果。RepViT采用了早期卷积[25]作为起始模块,即两个步幅为2的卷积进行4×降采样。它采用了RepViT块,由结构重参数化的深度卷积[4, 5]和前馈模块组成。相邻阶段之间采用了深度降采样模块,利用步幅为2的深度卷积和逐点卷积进行空间降采样和通道维度调制。此外,在所有阶段中都采用了交叉块方式的squeeze-and-excitation [8]层。RepViT在高分辨率视觉任务的延迟方面显示出了显著优势[21],这归功于其纯卷积架构。如表1所示,将ViT-H图像编码器替换为RepViT-M2.3模型后,RepViT-SAM在延迟方面与其他模型相比显著减少。在iPhone 12上,RepViT-SAM可以顺利进行模型推理。此外,在Macbook上,RepViT-SAM比MobileSAM快近10倍。
根据[27],我们通过直接蒸馏图像编码器RepViT-M2.3,即从原始SAM [13]中的ViT-H蒸馏,利用简单的均方误差损失来训练RepViT-SAM。与[27]类似,RepViT中最后一个降采样深度卷积的步幅设置为1,以使输出分辨率与原始SAM [13]中的提示引导掩模解码器兼容。

表1. RepViT-SAM与其他模型在延迟方面的比较。延迟(毫秒)是使用iPhone 12和Macbook M1 Pro上的Core ML工具,以标准分辨率[7] 1024×1024进行测量的。OOM表示内存不足。
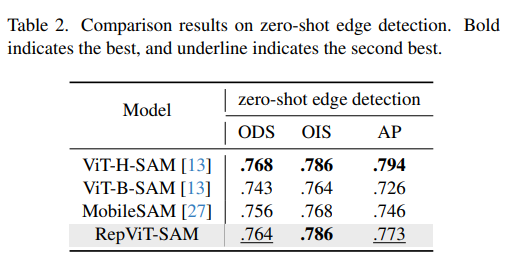
表2. 零样本边缘检测的比较结果。粗体表示最佳,下划线表示次佳。
2. 实验
2.1 实施细节
RepViT-SAM在与[27]相同的设置下进行了8个时期的训练。与MobileSAM [27]一样,我们只使用SAM-1B数据集[13]中的1%数据。为了加快训练过程,我们在蒸馏阶段之前预先计算并保存了来自ViT-H图像编码器的图像嵌入,这消除了在蒸馏过程中运行ViT-H的前向过程的需要,就像[27]一样。我们在BSDS500 [1, 17]上评估了RepViT-SAM在零样本边缘检测、使用COCO [14]进行零样本实例分割、在野外基准[29](SegInW)上进行分割、使用DAVIS 2017 [18]/UVO v1.0 [23]进行零样本视频对象/实例分割、使用DUTS [22]进行零样本显著对象分割,以及使用MVTec-AD [2]进行零样本异常检测的性能,遵循[3, 9, 12, 13, 19]。
2.2 零样本边缘检测
在[13]的基础上,我们利用一个16×16的前景点规则网格作为模型的提示。我们对概率图进行非极大值抑制(NMS)以去除冗余的掩模。此外,我们还对掩模的未阈值概率图应用Sobel滤波器,并进行标准的轻量级后处理,包括边缘NMS,如[13]中所述。如表2所示,我们的RepViT-SAM在所有指标上均优于MobileSAM和ViT-B-SAM。与ViT-H-SAM相比,后者是参数超过615M的最大SAM模型,我们的小型RepViT-SAM在ODS和OIS方面可以获得可比的性能。
2.3 零样本实例分割
我们利用最先进的H-Deformable-DETR [10]与Swin-L [16]作为目标检测器,使用其输出框作为模型的提示,类似于[12, 13]。如表3所示,我们的RepViT-SAM在零样本实例分割任务中显著优于MobileSAM和ViT-B-SAM,分别提高了1.7和1.9个AP。此外,可以观察到,通过解耦蒸馏策略获得的模型,即MobileSAM和RepViT-SAM,在大物体上通常优于通过耦合蒸馏获得的模型,即ViT-B-SAM,但在小物体上表现相对较差。这种现象可能归因于解耦蒸馏策略能够更好地传递宏观视觉特征,但在细粒度特征上表现不佳。
2.4 野外环境下的分割基准测试
我们遵循[12]的方法,将Grounding-DINO [15]作为框提示,以在零-shot轨道上评估模型。如表3所示,我们的RepViT-SAM在平均AP上分别比MobileSAM和ViT-B-SAM高出2.2和1.3个百分点。这充分表明了RepViT-SAM对不同下游分割任务的强大可迁移性。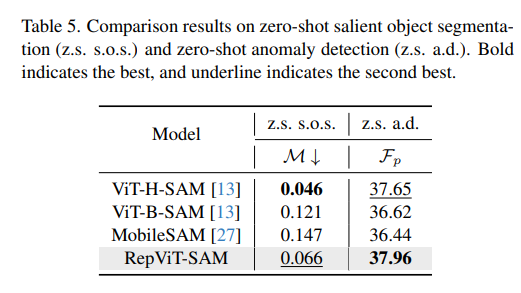
表5. 零样本显著目标分割(z.s. s.o.s.)和零样本异常检测(z.s. a.d.)的比较结果。粗体表示最佳,下划线表示次佳。
2.5 Zero-shot视频对象/实例分割
我们利用SAM-PT [19]来评估RepViT-SAM在DAVIS 2017 [18]和UVO [23]数据集的验证集上的性能。我们简单地用我们的RepViT-SAM替换SAM-PT中的原始SAM,使用CoTracker [11]作为点跟踪器,而不使用重新初始化策略。如表4所示,在DAVIS 2017上,我们的RepViT-SAM获得了73.5的平均J & F分数,明显优于MobileSAM和ViT-B-SAM分别为2.4和2.2。此外,在UVO上,RepViT-SAM分别以2.6和6.2的显著优势超过了MobileSAM和ViT-B-SAM。这些结果表明,与其他轻量级模型相比,RepViT-SAM的优越性不仅限于图像分割任务,还可以扩展到视频分割任务。
2.6 零样本显著目标分割
我们遵循[9]首先利用RepViT-SAM为给定图像生成N个潜在对象掩模。随后,我们通过评估其与地面真相的对齐来选择最合适的掩模。交并比(IoU)分数被采用作为对齐度量。按照[9]的做法,我们报告平均绝对误差(MAE)分数。需要注意的是,较低的MAE表示更好的分割结果。如表5所示,我们的RepViT-SAM在MAE分数方面表现出了与MobileSAM和ViT-B-SAM相比的优越性。
2.7 零样本异常检测
我们利用SAA+ [3]来评估RepViT-SAM在MVTec-AD基准数据集上的性能。我们简单地用我们的RepViT-SAM替换SAA+中的原始SAM。我们遵循[3]报告最大F1像素(Fp),它量化了在最佳阈值下像素级分割的F1分数。如表5所示,我们的RepViT-SAM在Fp方面取得了最佳性能,甚至优于ViT-H-SAM。这表明,对于某些特定的下游任务,解耦的精简模型可以实现比原始SAM更好的性能,同时延迟更低,展示了RepViT-SAM的有前途的应用。

图1. SAM、MobileSAM 和 RepViT-SAM 的面具预测结果,其中包括点提示(顶部)和框提示(底部)
3. 总结
Segment Anything Model (SAM) 展现了出色的零样本迁移性能,但其高昂的计算成本限制了实际应用。MobileSAM通过替换SAM的重型图像编码器为轻量级TinyViT,显著降低了计算需求。然而,MobileSAM在移动设备上部署仍面临挑战,特别是由于自注意力机制导致的内存和计算开销。最新的RepViT集成了ViTs的高效架构设计到CNN中,优化了移动设备上的性能和延迟权衡。RepViT-SAM模型,通过替换SAM的重型图像编码器为RepViT模型,成功在移动设备上实现实时分割任何事物。该模型在性能和处理延迟方面都有显著改进,尤其是在移动设备上的应用。


评论(0)
您还未登录,请登录后发表或查看评论