

0. 简介
自从发现可以利用自有数据来增强大语言模型(LLM)的能力以来,如何将 LLM 的通用知识与个人数据有效结合一直是热门话题。关于使用微调(fine-tuning)还是检索增强生成(RAG)来实现这一目标的讨论持续不断。检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
用一个简单的比喻来说, RAG 对大语言模型(Large Language Model,LLM)的作用,就像开卷考试对学生一样。在开卷考试中,学生可以带着参考资料进场,比如教科书或笔记,用来查找解答问题所需的相关信息。开卷考试的核心在于考察学生的推理能力,而非对具体信息的记忆能力。同样地,在 RAG 中,事实性知识与 LLM 的推理能力相分离,被存储在容易访问和及时更新的外部知识源中,具体分为两种:
- 参数化知识(Parametric knowledge): 模型在训练过程中学习得到的,隐式地储存在神经网络的权重中。
- 非参数化知识(Non-parametric knowledge): 存储在外部知识源,例如向量数据库中。

1. 了解LangChain

从上图可以看到,LangChain 目前有四层框架:
- 最下层深色部分:LangChain的Python和JavaScript库。包含无数组件的接口和集成,以及将这些组件组合到一起的链(chain)和代理(agent)封装,还有链和代理的具体实现。
- Templates:一组易于部署的参考体系结构,用于各种各样的任务。
- LangServe:用于将LangChain链部署为REST API的库。
- LangSmith:一个开发人员平台,允许您调试、测试、评估和监控基于任何LLM框架构建的链,并与LangChain无缝集成。
2. RAG基础使用
首先,你需要建立一个向量数据库,这个数据库作为一个外部知识源,包含了所有必要的额外信息。填充这个数据库需要遵循以下步骤:
- 收集数据并将其加载进系统
- 将你的文档进行分块处理
- 对分块内容进行嵌入,并存储这些块
首先,你需要收集并加载数据。为了加载数据,你可以利用 LangChain 提供的众多 DocumentLoader 之一。Document 是一个包含文本和元数据的字典。为了加载文本,你会使用 LangChain 的 TextLoader。
import requests
from langchain.document_loaders import TextLoader
url = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
其次,需要对文档进行分块 — 由于 Document 的原始大小超出了 LLM 处理窗口的限制,因此需要将其切割成更小的片段。LangChain 提供了许多文本分割工具,对于这个简单的示例,你可以使用 CharacterTextSplitter,设置 chunk_size 大约为 500,并且设置 chunk_overlap 为 50,以确保文本块之间的连贯性。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
最后一步是嵌入并存储这些文本块 — 为了实现对文本块的语义搜索,你需要为每个块生成向量嵌入,并将它们存储起来。生成向量嵌入时,你可以使用 OpenAI 的嵌入模型;而存储它们,则可以使用 Weaviate 向量数据库。通过执行 .from_documents() 操作,就可以自动将这些块填充进向量数据库中。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
一旦向量数据库准备好,你就可以将它设定为检索组件,这个组件能够根据用户查询与已嵌入的文本块之间的语义相似度,来检索出额外的上下文信息
retriever = vectorstore.as_retriever()
接下来,你需要准备一个提示模板,以便用额外的上下文信息来增强原始的提示。你可以根据下面显示的示例,轻松地定制这样一个提示模板。
from langchain.prompts import ChatPromptTemplate
template = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt)
在 RAG (检索增强生成) 管道的构建过程中,可以通过将检索器、提示模板与大语言模型 (LLM) 相结合来形成一个序列。定义好 RAG 序列之后,就可以开始执行它。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = "What did the president say about Justice Breyer"
rag_chain.invoke(query)

3. ollama替换chatgpt完成联网搜索拆分
此外可以通过ollama检索完成Embedding,给他资料,让他从这些资料从中找到答案来回答问题,就是构建知识库,回答问题
urls = [
"https://ollama.com/",
"https://ollama.com/blog/windows-preview",
"https://ollama.com/blog/openai-compatibility",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [ item for sublist in docs for item in sublist]
#text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500,chunk_overlap=100)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500, chunk_overlap=100)
docs_splits = text_splitter.split_documents(docs_list)
# 2 convert documents to Embeddings and store them
vectorstore = Chroma.from_documents(
documents=docs_splits,
collection_name="rag-chroma",
embedding=embeddings.ollama.OllamaEmbeddings(model='nomic-embed-text'),
)
retriever =vectorstore.as_retriever()
# 4 after RAG
print("\n######\nAfter RAG\n")
after_rag_template ="""Answer the question based only the following context:
{context}
Question:{question}
"""
after_rag_prompt = ChatPromptTemplate.from_template(after_rag_template)
after_rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| after_rag_prompt
| model_local
| StrOutputParser()
)
print(after_rag_chain.invoke("What is Ollama?"))
通过三个网址,获取数据,将其转化为embedding,存储在向量库中,我们提问时,就能得到我们想要的一个初步答案,比未给语料时效果要好。
使用nomic-embed-text进行嵌入,nomic-embed-text具有更高的上下文长度8k,该模型在短文本和长文本任务上均优于 OpenAI Ada-002 和text-embedding-3-small。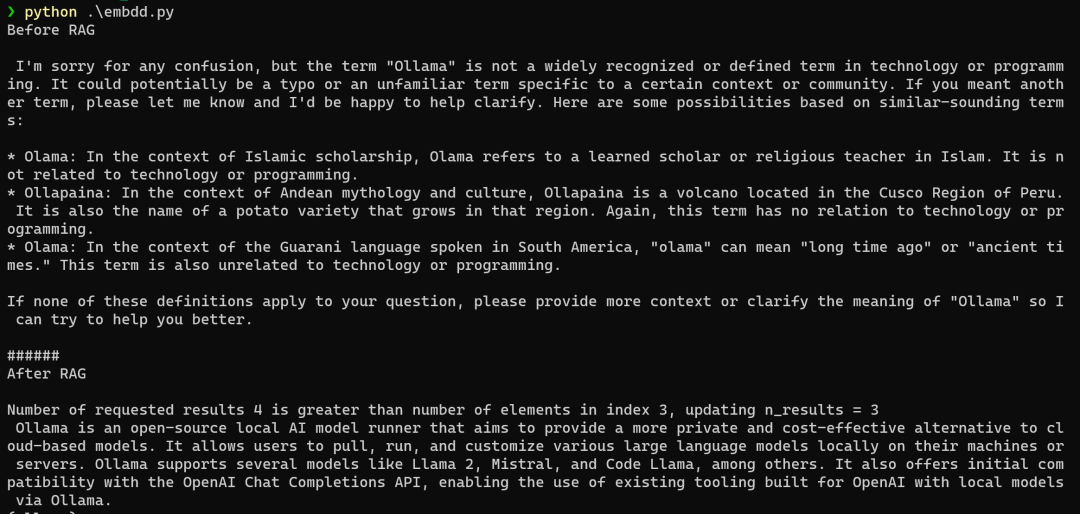
4. 多模态RAG
为了帮助模型识别出”猫”的图像和”猫”这个词是相似的,我们依赖于多模态嵌入。为了简化一下,想象有一个魔盒,能够处理各种输入——图像、音频、文本等。现在,当我们用一张”猫”的图像和文本”猫”来喂养这个盒子时,它施展魔法,生成两个数值向量。当这两个向量被输入机器时,机器会想:”根据这些数值,看起来它们都与’猫’有关。”这正是我们的目标!我们的目标是帮助机器识别”猫”的图像和文本”猫”之间的密切联系。然而,为了验证这个概念,当我们在向量空间中绘制这两个数值向量时,结果发现它们非常接近。这个结果与我们之前观察到的两个文本词”猫”和”狗”在向量空间中的接近度完全一致。这就是多模态的本质。
现在我们训练文本-图像模型识别出正样本提供了准确的解释,而负样本具有误导性,应该在训练过程中被忽略。正式来说,这种技术被OpenAI引入的 CLIP[2] (对比语言-图像预训练)所称,作者在大约4亿对从互联网上获取的图像标题对上训练了一个图像-文本模型,每当模型犯错误时,对比损失函数就会增加并惩罚它,以确保模型训练良好。同样的原则也适用于其他模态组合,例如猫的声音与猫这个词是语音-文本模型的正样本,一段猫的视频与描述性文本”这是一只猫”是视频-文本模型的正样本。
# 创建虚拟环境
python3 -m venv env
# 激活虚拟环境
source env/bin/activate
# 升级虚拟环境中的pip
pip install --upgrade pip
#安装所需的依赖项
pip3 install lancedb clip torch datasets pillow
pip3 install git+https://github.com/openai/CLIP.git
数据集由两个关键特征组成:图像及其相应的描述性文本。最初,我们的任务是创建一个LanceDB表来存储嵌入。这个过程很简单——你所需要做的就是定义相关的模式。在我们的例子中,列包括存储多模态嵌入的 “vector”、描述性文本的 “text “列和相应ID的 “label “列
import pyarrow as pa
import lancedb
import tqdm
db = lancedb.connect('./data/tables')
schema = pa.schema(
[
pa.field("vector", pa.list_(pa.float32(), 512)),
pa.field("text", pa.string()),
pa.field("id", pa.int32())
])
tbl = db.create_table("gta_data", schema=schema, mode="overwrite")
data = []
for i in range(len(ds["train"])):
img = ds["train"][i]['image']
text = ds["train"][i]['text']
# 编码图像
encoded_img = embed_image(img)
data.append({"vector": encoded_img, "text": text, "id" : i})
tbl.add(data)
tbl.to_pandas()
def embed_image(img):
processed_image = preprocess(img)
unsqueezed_image = processed_image.unsqueeze(0).to(device)
embeddings = model.encode_image(unsqueezed_image)
# 分离,移至CPU,转换为numpy数组,并提取第一个元素作为列表
result = embeddings.detach().cpu().numpy()[0].tolist()
return result
def embed_txt(txt):
tokenized_text = clip.tokenize([txt]).to(device)
embeddings = model.encode_text(tokenized_text)
# 分离,移至CPU,转换为numpy数组,并提取第一个元素作为列表
result = embeddings.detach().cpu().numpy()[0].tolist()
return result
如果借助其他的例如GPT4V,则可以得到大体流程:
1)使用多模态embedding(如 CLIP)处理图像和文本
2)对于图像和文本均使用向量检索
3)将原始图像和文本块传递给多模态 LLM(GPT4-V)进行答案合成
具体代码如下:
对文档进行多模态embedding入库
在这里,使用了 OpenClip 多模态embedding。为了获得更好的性能,使用了更大的模型(在 langchain_experimental.open_clip.py 中设置)。
model_name = “ViT-g-14” checkpoint = “laion2b_s34b_b88k”
import chromadb
import numpy as np
from langchain.vectorstores import Chroma
from langchain_experimental.open_clip import OpenCLIPEmbeddings
from PIL import Image as _PILImage
# Create chroma
vectorstore = Chroma(
collection_name="mm_rag_clip_photos", embedding_function=OpenCLIPEmbeddings()
)
# Get image URIs with .jpg extension only
image_uris = sorted(
[
os.path.join(path, image_name)
for image_name in os.listdir(path)
if image_name.endswith(".jpg")
]
)
# Add images
vectorstore.add_images(uris=image_uris)
# Add documents
vectorstore.add_texts(texts=texts)
# Make retriever
retriever = vectorstore.as_retriever()
检索增强生成
上面的vectorstore.add_images 方法将以 base64 编码字符串的形式存储/检索图像,然后将这些信息传递给 GPT-4V
import base64
import io
from io import BytesIO
import numpy as np
from PIL import Image
def resize_base64_image(base64_string, size=(128, 128)):
"""
Resize an image encoded as a Base64 string.
Args:
base64_string (str): Base64 string of the original image.
size (tuple): Desired size of the image as (width, height).
Returns:
str: Base64 string of the resized image.
"""
# Decode the Base64 string
img_data = base64.b64decode(base64_string)
img = Image.open(io.BytesIO(img_data))
# Resize the image
resized_img = img.resize(size, Image.LANCZOS)
# Save the resized image to a bytes buffer
buffered = io.BytesIO()
resized_img.save(buffered, format=img.format)
# Encode the resized image to Base64
return base64.b64encode(buffered.getvalue()).decode("utf-8")
def is_base64(s):
"""Check if a string is Base64 encoded"""
try:
return base64.b64encode(base64.b64decode(s)) == s.encode()
except Exception:
return False
def split_image_text_types(docs):
"""Split numpy array images and texts"""
images = []
text = []
for doc in docs:
doc = doc.page_content # Extract Document contents
if is_base64(doc):
# Resize image to avoid OAI server error
images.append(
resize_base64_image(doc, size=(250, 250))
) # base64 encoded str
else:
text.append(doc)
return {"images": images, "texts": text}
使用 RunnableParallel 对输入进行格式化,同时为 ChatPromptTemplates 添加图像支持。
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough,RunnableParallel
def prompt_func(data_dict):
# Joining the context texts into a single string
formatted_texts = "\n".join(data_dict["context"]["texts"])
messages = []
# Adding image(s) to the messages if present
if data_dict["context"]["images"]:
image_message = {
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{data_dict['context']['images'][0]}"
},
}
messages.append(image_message)
# Adding the text message for analysis
text_message = {
"type": "text",
"text": (
"As an expert art critic and historian, your task is to analyze and interpret images, "
"considering their historical and cultural significance. Alongside the images, you will be "
"provided with related text to offer context. Both will be retrieved from a vectorstore based "
"on user-input keywords. Please use your extensive knowledge and analytical skills to provide a "
"comprehensive summary that includes:\n"
"- A detailed description of the visual elements in the image.\n"
"- The historical and cultural context of the image.\n"
"- An interpretation of the image's symbolism and meaning.\n"
"- Connections between the image and the related text.\n\n"
f"User-provided keywords: {data_dict['question']}\n\n"
"Text and / or tables:\n"
f"{formatted_texts}"
),
}
messages.append(text_message)
return [HumanMessage(content=messages)]
利用LCEL 构造RAG chain
from google.colab import userdata
openai_api_key = userdata.get('OPENAI_API_KEY')
model = ChatOpenAI(temperature=0,
openai_api_key=openai_api_key,
model="gpt-4-vision-preview",
max_tokens=1024)
# RAG pipeline
chain = (
{
"context": retriever | RunnableLambda(split_image_text_types),
"question": RunnablePassthrough(),
}
| RunnableParallel({"response":prompt_func| model| StrOutputParser(),
"context": itemgetter("context"),})
)
RAG的一些不足以及注意点
1.RAG主要由两阶段所构成,因此其效果主要受两方面的影响:
第一点:受到向量库的构建,以及检索召回的方式影响,召回的内容越详尽越准确越好
第二点:受到大模型的本身能力的影响,包括大模型的理解能力,是否理解召回的知识,大模型的生成能力,是否能生成准确答案
2.同时也应该注意prompt模板的设置,模板的设置也会影响到模型的表现、
参考链接
https://blog.csdn.net/qq_48814168/article/details/136717146
https://mp.weixin.qq.com/s/k-OF_L-x85B6H73xMoxpcg


评论(0)
您还未登录,请登录后发表或查看评论